Compare commits
37 commits
master
...
slf/chain-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
94e4eac12c | ||
|
|
54851488cc | ||
|
|
e0c6aeac94 | ||
|
|
f2ee7b5045 | ||
|
|
fab03a90c6 | ||
|
|
f89c9c43d3 | ||
|
|
2f16a3a944 | ||
|
|
7817d7c160 | ||
|
|
6566420e32 | ||
|
|
8ff177f0c5 | ||
|
|
666a05b50b | ||
|
|
8cdf69c8b9 | ||
|
|
f129801f29 | ||
|
|
2fe2a23c79 | ||
|
|
6ed7293b02 | ||
|
|
b8063c9575 | ||
|
|
b558de2244 | ||
|
|
4e01f5bac0 | ||
|
|
cf56e2d388 | ||
|
|
cebb205b52 | ||
|
|
6e4e2ac6bf | ||
|
|
fbdf606128 | ||
|
|
938f3c16f2 | ||
|
|
24fc2a773c | ||
|
|
77f16523f4 | ||
|
|
07e477598a | ||
|
|
ecd56a194e | ||
|
|
187ed6ddce | ||
|
|
b03f88de43 | ||
|
|
2ae8a42d07 | ||
|
|
50dd83919a | ||
|
|
35c9f41cf4 | ||
|
|
4f28191552 | ||
|
|
1488587dd9 | ||
|
|
0b4e106635 | ||
|
|
27f17e88ad | ||
|
|
f4a2a453bd |
32
.gitignore
vendored
|
|
@ -1,33 +1,9 @@
|
|||
prototype/chain-manager/patch.*
|
||||
.eqc-info
|
||||
.eunit
|
||||
deps
|
||||
dev
|
||||
*.o
|
||||
ebin/*.beam
|
||||
*.plt
|
||||
erl_crash.dump
|
||||
eqc
|
||||
rel/example_project
|
||||
.concrete/DEV_MODE
|
||||
.rebar
|
||||
edoc
|
||||
|
||||
# Dialyzer stuff
|
||||
.dialyzer-last-run.txt
|
||||
.ebin.native
|
||||
.local_dialyzer_plt
|
||||
dialyzer_unhandled_warnings
|
||||
dialyzer_warnings
|
||||
*.plt
|
||||
|
||||
# PB artifacts for Erlang
|
||||
include/machi_pb.hrl
|
||||
|
||||
# Release packaging
|
||||
rel/machi
|
||||
rel/vars/dev*vars.config
|
||||
|
||||
# Misc Scott cruft
|
||||
*.patch
|
||||
current_counterexample.eqc
|
||||
foo*
|
||||
RUNLOG*
|
||||
typescript*
|
||||
*.swp
|
||||
|
|
|
|||
|
|
@ -1,7 +0,0 @@
|
|||
language: erlang
|
||||
notifications:
|
||||
email: scott@basho.com
|
||||
script: "priv/test-for-gh-pr.sh"
|
||||
otp_release:
|
||||
- 17.5
|
||||
## No, Dialyzer is too different between 17 & 18: - 18.1
|
||||
|
|
@ -1,35 +0,0 @@
|
|||
# Contributing to the Machi project
|
||||
|
||||
The most helpful way to contribute is by reporting your experience
|
||||
through issues. Issues may not be updated while we review internally,
|
||||
but they're still incredibly appreciated.
|
||||
|
||||
Pull requests may take multiple engineers for verification and testing. If
|
||||
you're passionate enough to want to learn more on how you can get
|
||||
hands on in this process, reach out to
|
||||
[Matt Brender](mailto:mbrender@basho.com), your developer advocate.
|
||||
|
||||
Thank you for being part of the community! We love you for it.
|
||||
|
||||
## If you have a question or wish to provide design feedback/criticism
|
||||
|
||||
Please
|
||||
[open a support ticket at GitHub](https://github.com/basho/machi/issues/new)
|
||||
to ask questions and to provide feedback about Machi's
|
||||
design/documentation/source code.
|
||||
|
||||
## General development process
|
||||
|
||||
Machi is still a very young project within Basho, with a small team of
|
||||
developers; please bear with us as we grow out of "toddler" stage into
|
||||
a more mature open source software project.
|
||||
|
||||
* Fork the Machi source repo and/or the sub-projects that are affected
|
||||
by your change.
|
||||
* Create a topic branch for your change and checkout that branch.
|
||||
git checkout -b some-topic-branch
|
||||
* Make your changes and run the test suite if one is provided.
|
||||
* Commit your changes and push them to your fork.
|
||||
* Open pull-requests for the appropriate projects.
|
||||
* Contributors will review your pull request, suggest changes, and merge it when it’s ready and/or offer feedback.
|
||||
* To report a bug or issue, please open a new issue against this repository.
|
||||
630
FAQ.md
|
|
@ -1,630 +0,0 @@
|
|||
# Frequently Asked Questions (FAQ)
|
||||
|
||||
<!-- Formatting: -->
|
||||
<!-- All headings omitted from outline are H1 -->
|
||||
<!-- All other headings must be on a single line! -->
|
||||
<!-- Run: ./priv/make-faq.pl ./FAQ.md > ./tmpfoo; mv ./tmpfoo ./FAQ.md -->
|
||||
|
||||
# Outline
|
||||
|
||||
<!-- OUTLINE -->
|
||||
|
||||
+ [1 Questions about Machi in general](#n1)
|
||||
+ [1.1 What is Machi?](#n1.1)
|
||||
+ [1.2 What is a Machi chain?](#n1.2)
|
||||
+ [1.3 What is a Machi cluster?](#n1.3)
|
||||
+ [1.4 What is Machi like when operating in "eventually consistent" mode?](#n1.4)
|
||||
+ [1.5 What is Machi like when operating in "strongly consistent" mode?](#n1.5)
|
||||
+ [1.6 What does Machi's API look like?](#n1.6)
|
||||
+ [1.7 What licensing terms are used by Machi?](#n1.7)
|
||||
+ [1.8 Where can I find the Machi source code and documentation? Can I contribute?](#n1.8)
|
||||
+ [1.9 What is Machi's expected release schedule, packaging, and operating system/OS distribution support?](#n1.9)
|
||||
+ [2 Questions about Machi relative to {{something else}}](#n2)
|
||||
+ [2.1 How is Machi better than Hadoop?](#n2.1)
|
||||
+ [2.2 How does Machi differ from HadoopFS/HDFS?](#n2.2)
|
||||
+ [2.3 How does Machi differ from Kafka?](#n2.3)
|
||||
+ [2.4 How does Machi differ from Bookkeeper?](#n2.4)
|
||||
+ [2.5 How does Machi differ from CORFU and Tango?](#n2.5)
|
||||
+ [3 Machi's specifics](#n3)
|
||||
+ [3.1 What technique is used to replicate Machi's files? Can other techniques be used?](#n3.1)
|
||||
+ [3.2 Does Machi have a reliance on a coordination service such as ZooKeeper or etcd?](#n3.2)
|
||||
+ [3.3 Are there any presentations available about Humming Consensus](#n3.3)
|
||||
+ [3.4 Is it true that there's an allegory written to describe Humming Consensus?](#n3.4)
|
||||
+ [3.5 How is Machi tested?](#n3.5)
|
||||
+ [3.6 Does Machi require shared disk storage? e.g. iSCSI, NBD (Network Block Device), Fibre Channel disks](#n3.6)
|
||||
+ [3.7 Does Machi require or assume that servers with large numbers of disks must use RAID-0/1/5/6/10/50/60 to create a single block device?](#n3.7)
|
||||
+ [3.8 What language(s) is Machi written in?](#n3.8)
|
||||
+ [3.9 Can Machi run on Windows? Can Machi run on 32-bit platforms?](#n3.9)
|
||||
+ [3.10 Does Machi use the Erlang/OTP network distribution system (aka "disterl")?](#n3.10)
|
||||
+ [3.11 Can I use HTTP to write/read stuff into/from Machi?](#n3.11)
|
||||
|
||||
<!-- ENDOUTLINE -->
|
||||
|
||||
<a name="n1">
|
||||
## 1. Questions about Machi in general
|
||||
|
||||
<a name="n1.1">
|
||||
### 1.1. What is Machi?
|
||||
|
||||
Very briefly, Machi is a very simple append-only blob/file store.
|
||||
|
||||
Machi is
|
||||
"dumber" than many other file stores (i.e., lacking many features
|
||||
found in other file stores) such as HadoopFS or a simple NFS or CIFS file
|
||||
server.
|
||||
However, Machi is a distributed blob/file store, which makes it different
|
||||
(and, in some ways, more complicated) than a simple NFS or CIFS file
|
||||
server.
|
||||
|
||||
All Machi data is protected by SHA-1 checksums. By default, these
|
||||
checksums are calculated by the client to provide strong end-to-end
|
||||
protection against data corruption. (If the client does not provide a
|
||||
checksum, one will be generated by the first Machi server to handle
|
||||
the write request.) Internally, Machi uses these checksums for local
|
||||
data integrity checks and for server-to-server file synchronization
|
||||
and corrupt data repair.
|
||||
|
||||
As a distributed system, Machi can be configured to operate with
|
||||
either eventually consistent mode or strongly consistent mode. In
|
||||
strongly consistent mode, Machi can provide write-once file store
|
||||
service in the same style as CORFU. Machi can be an easy to use tool
|
||||
for building fully ordered, log-based distributed systems and
|
||||
distributed data structures.
|
||||
|
||||
In eventually consistent mode, Machi can remain available for writes
|
||||
during arbitrary network partitions. When a network partition is
|
||||
fixed, Machi can safely merge all file data together without data
|
||||
loss. Similar to the operation of
|
||||
Basho's
|
||||
[Riak key-value store, Riak KV](http://basho.com/products/riak-kv/),
|
||||
Machi can provide file writes during arbitrary network partitions and
|
||||
later merge all results together safely when the cluster recovers.
|
||||
|
||||
For a much longer answer, please see the
|
||||
[Machi high level design doc](https://github.com/basho/machi/tree/master/doc/high-level-machi.pdf).
|
||||
|
||||
<a name="n1.2">
|
||||
### 1.2. What is a Machi chain?
|
||||
|
||||
A Machi chain is a small number of machines that maintain a common set
|
||||
of replicated files. A typical chain is of length 2 or 3. For
|
||||
critical data that must be available despite several simultaneous
|
||||
server failures, a chain length of 6 or 7 might be used.
|
||||
|
||||
<a name="n1.3">
|
||||
### 1.3. What is a Machi cluster?
|
||||
|
||||
A Machi cluster is a collection of Machi chains that
|
||||
partitions/shards/distributes files (based on file name) across the
|
||||
collection of chains. Machi uses the "random slicing" algorithm (a
|
||||
variation of consistent hashing) to define the mapping of file name to
|
||||
chain name.
|
||||
|
||||
The cluster management service will be fully decentralized
|
||||
and run as a separate software service installed on each Machi
|
||||
cluster. This manager will appear to the local Machi server as simply
|
||||
another Machi file client. The cluster managers will take
|
||||
care of file migration as the cluster grows and shrinks in capacity
|
||||
and in response to day-to-day changes in workload.
|
||||
|
||||
Though the cluster manager has not yet been implemented,
|
||||
its design is fully decentralized and capable of operating despite
|
||||
multiple partial failure of its member chains. We expect this
|
||||
design to scale easily to at least one thousand servers.
|
||||
|
||||
Please see the
|
||||
[Machi source repository's 'doc' directory for more details](https://github.com/basho/machi/tree/master/doc/).
|
||||
|
||||
<a name="n1.4">
|
||||
### 1.4. What is Machi like when operating in "eventually consistent" mode?
|
||||
|
||||
Machi's operating mode dictates how a Machi cluster will react to
|
||||
network partitions. A network partition may be caused by:
|
||||
|
||||
* A network failure
|
||||
* A server failure
|
||||
* An extreme server software "hang" or "pause", e.g. caused by OS
|
||||
scheduling problems such as a failing/stuttering disk device.
|
||||
|
||||
The consistency semantics of file operations while in eventual
|
||||
consistency mode during and after network partitions are:
|
||||
|
||||
* File write operations are permitted by any client on the "same side"
|
||||
of the network partition.
|
||||
* File read operations are successful for any file contents where the
|
||||
client & server are on the "same side" of the network partition.
|
||||
* File read operations will probably fail for any file contents where the
|
||||
client & server are on "different sides" of the network partition.
|
||||
* After the network partition(s) is resolved, files are merged
|
||||
together from "all sides" of the partition(s).
|
||||
* Unique files are copied in their entirety.
|
||||
* Byte ranges within the same file are merged. This is possible
|
||||
due to Machi's restrictions on file naming and file offset
|
||||
assignment. Both file names and file offsets are always chosen
|
||||
by Machi servers according to rules which guarantee safe
|
||||
mergeability. Server-assigned names are a characteristic of a
|
||||
"blob store".
|
||||
|
||||
<a name="n1.5">
|
||||
### 1.5. What is Machi like when operating in "strongly consistent" mode?
|
||||
|
||||
The consistency semantics of file operations while in strongly
|
||||
consistency mode during and after network partitions are:
|
||||
|
||||
* File write operations are permitted by any client on the "same side"
|
||||
of the network partition if and only if a quorum majority of Machi servers
|
||||
are also accessible within that partition.
|
||||
* In other words, file write service is unavailable in any
|
||||
partition where only a minority of Machi servers are accessible.
|
||||
* File read operations are successful for any file contents where the
|
||||
client & server are on the "same side" of the network partition.
|
||||
* After the network partition(s) is resolved, files are repaired from
|
||||
the surviving quorum majority members to out-of-sync minority
|
||||
members.
|
||||
|
||||
Machi's design can provide the illusion of quorum minority write
|
||||
availability if the cluster is configured to operate with "witness
|
||||
servers". (This feaure partially implemented, as of December 2015.)
|
||||
See Section 11 of
|
||||
[Machi chain manager high level design doc](https://github.com/basho/machi/tree/master/doc/high-level-chain-mgr.pdf)
|
||||
for more details.
|
||||
|
||||
<a name="n1.6">
|
||||
### 1.6. What does Machi's API look like?
|
||||
|
||||
The Machi API only contains a handful of API operations. The function
|
||||
arguments shown below (in simplifed form) use Erlang-style type annotations.
|
||||
|
||||
append_chunk(Prefix:binary(), Chunk:binary(), CheckSum:binary()).
|
||||
append_chunk_extra(Prefix:binary(), Chunk:binary(), CheckSum:binary(), ExtraSpace:non_neg_integer()).
|
||||
read_chunk(File:binary(), Offset:non_neg_integer(), Size:non_neg_integer()).
|
||||
|
||||
checksum_list(File:binary()).
|
||||
list_files().
|
||||
|
||||
Machi allows the client to choose the prefix of the file name to
|
||||
append data to, but the Machi server will always choose the final file
|
||||
name and byte offset for each `append_chunk()` operation. This
|
||||
restriction on file naming makes it easy to operate in "eventually
|
||||
consistent" mode: files may be written to any server during network
|
||||
partitions and can be easily merged together after the partition is
|
||||
healed.
|
||||
|
||||
Internally, there is a more complex protocol used by individual
|
||||
cluster members to manage file contents and to repair damaged/missing
|
||||
files. See Figure 3 in
|
||||
[Machi high level design doc](https://github.com/basho/machi/tree/master/doc/high-level-machi.pdf)
|
||||
for more description.
|
||||
|
||||
The definitions of both the "high level" external protocol and "low
|
||||
level" internal protocol are in a
|
||||
[Protocol Buffers](https://developers.google.com/protocol-buffers/docs/overview)
|
||||
definition at [./src/machi.proto](./src/machi.proto).
|
||||
|
||||
<a name="n1.7">
|
||||
### 1.7. What licensing terms are used by Machi?
|
||||
|
||||
All Machi source code and documentation is licensed by
|
||||
[Basho Technologies, Inc.](http://www.basho.com/)
|
||||
under the [Apache Public License version 2](https://github.com/basho/machi/tree/master/LICENSE).
|
||||
|
||||
<a name="n1.8">
|
||||
### 1.8. Where can I find the Machi source code and documentation? Can I contribute?
|
||||
|
||||
All Machi source code and documentation can be found at GitHub:
|
||||
[https://github.com/basho/machi](https://github.com/basho/machi).
|
||||
The full URL for this FAQ is [https://github.com/basho/machi/blob/master/FAQ.md](https://github.com/basho/machi/blob/master/FAQ.md).
|
||||
|
||||
There are several "README" files in the source repository. We hope
|
||||
they provide useful guidance for first-time readers.
|
||||
|
||||
If you're interested in contributing code or documentation or
|
||||
ideas for improvement, please see our contributing & collaboration
|
||||
guidelines at
|
||||
[https://github.com/basho/machi/blob/master/CONTRIBUTING.md](https://github.com/basho/machi/blob/master/CONTRIBUTING.md).
|
||||
|
||||
<a name="n1.9">
|
||||
### 1.9. What is Machi's expected release schedule, packaging, and operating system/OS distribution support?
|
||||
|
||||
Basho expects that Machi's first major product release will take place
|
||||
during the 2nd quarter of 2016.
|
||||
|
||||
Basho's official support for operating systems (e.g. Linux, FreeBSD),
|
||||
operating system packaging (e.g. CentOS rpm/yum package management,
|
||||
Ubuntu debian/apt-get package management), and
|
||||
container/virtualization have not yet been chosen. If you wish to
|
||||
provide your opinion, we'd love to hear it. Please
|
||||
[open a support ticket at GitHub](https://github.com/basho/machi/issues/new)
|
||||
and let us know.
|
||||
|
||||
<a name="n2">
|
||||
## 2. Questions about Machi relative to {{something else}}
|
||||
|
||||
<a name="better-than-hadoop">
|
||||
<a name="n2.1">
|
||||
### 2.1. How is Machi better than Hadoop?
|
||||
|
||||
This question is frequently asked by trolls. If this is a troll
|
||||
question, the answer is either, "Nothing is better than Hadoop," or
|
||||
else "Everything is better than Hadoop."
|
||||
|
||||
The real answer is that Machi is not a distributed data processing
|
||||
framework like Hadoop is.
|
||||
See [Hadoop's entry in Wikipedia](https://en.wikipedia.org/wiki/Apache_Hadoop)
|
||||
and focus on the description of Hadoop's MapReduce and YARN; Machi
|
||||
contains neither.
|
||||
|
||||
<a name="n2.2">
|
||||
### 2.2. How does Machi differ from HadoopFS/HDFS?
|
||||
|
||||
This is a much better question than the
|
||||
[How is Machi better than Hadoop?](#better-than-hadoop)
|
||||
question.
|
||||
|
||||
[HadoopFS's entry in Wikipedia](https://en.wikipedia.org/wiki/Apache_Hadoop#HDFS)
|
||||
|
||||
One way to look at Machi is to consider Machi as a distributed file
|
||||
store. HadoopFS is also a distributed file store. Let's compare and
|
||||
contrast.
|
||||
|
||||
<table>
|
||||
|
||||
<tr>
|
||||
<td> <b>Machi</b>
|
||||
<td> <b>HadoopFS (HDFS)</b>
|
||||
|
||||
<tr>
|
||||
<td> Not POSIX compliant
|
||||
<td> Not POSIX compliant
|
||||
|
||||
<tr>
|
||||
<td> Immutable file store with append-only semantics (simplifying
|
||||
things a little bit).
|
||||
<td> Immutable file store with append-only semantics
|
||||
|
||||
<tr>
|
||||
<td> File data may be read concurrently while file is being actively
|
||||
appended to.
|
||||
<td> File must be closed before a client can read it.
|
||||
|
||||
<tr>
|
||||
<td> No concept (yet) of users or authentication (though the initial
|
||||
supported release will support basic user + password authentication).
|
||||
Machi will probably never natively support directories or ACLs.
|
||||
<td> Has concepts of users, directories, and ACLs.
|
||||
|
||||
<tr>
|
||||
<td> Machi does not allow clients to name their own files or to specify data
|
||||
placement/offset within a file.
|
||||
<td> While not POSIX compliant, HDFS allows a fairly flexible API for
|
||||
managing file names and file writing position within a file (during a
|
||||
file's writable phase).
|
||||
|
||||
<tr>
|
||||
<td> Does not have any file distribution/partitioning/sharding across
|
||||
Machi chains: in a single Machi chain, all files are replicated by
|
||||
all servers in the chain. The "random slicing" technique is used
|
||||
to distribute/partition/shard files across multiple Machi clusters.
|
||||
<td> File distribution/partitioning/sharding is performed
|
||||
automatically by the HDFS "name node".
|
||||
|
||||
<tr>
|
||||
<td> Machi requires no central "name node" for single chain use or
|
||||
for multi-chain cluster use.
|
||||
<td> Requires a single "namenode" server to maintain file system contents
|
||||
and file content mapping. (May be deployed with a "secondary
|
||||
namenode" to reduce unavailability when the primary namenode fails.)
|
||||
|
||||
<tr>
|
||||
<td> Machi uses Chain Replication to manage all file replicas.
|
||||
<td> The HDFS name node uses an ad hoc mechanism for replicating file
|
||||
contents. The HDFS file system metadata (file names, file block(s)
|
||||
locations, ACLs, etc.) is stored by the name node in the local file
|
||||
system and is replicated to any secondary namenode using snapshots.
|
||||
|
||||
<tr>
|
||||
<td> Machi replicates files *N* ways where *N* is the length of the
|
||||
Chain Replication chain. Typically, *N=2*, but this is configurable.
|
||||
<td> HDFS typical replicates file contents *N=3* ways, but this is
|
||||
configurable.
|
||||
|
||||
<tr>
|
||||
<td> All Machi file data is protected by SHA-1 checksums generated by
|
||||
the client prior to writing by Machi servers.
|
||||
<td> Optional file checksum protection may be implemented on the
|
||||
server side.
|
||||
|
||||
</table>
|
||||
|
||||
<a name="n2.3">
|
||||
### 2.3. How does Machi differ from Kafka?
|
||||
|
||||
Machi is rather close to Kafka in spirit, though its implementation is
|
||||
quite different.
|
||||
|
||||
<table>
|
||||
|
||||
<tr>
|
||||
<td> <b>Machi</b>
|
||||
<td> <b>Kafka</b>
|
||||
|
||||
<tr>
|
||||
<td> Append-only, strongly consistent file store only
|
||||
<td> Append-only, strongly consistent log file store + additional
|
||||
services: for example, producer topics & sharding, consumer groups &
|
||||
failover, etc.
|
||||
|
||||
<tr>
|
||||
<td> Not yet code complete nor "battle tested" in large production
|
||||
environments.
|
||||
<td> "Battle tested" in large production environments.
|
||||
|
||||
<tr>
|
||||
<td> All Machi file data is protected by SHA-1 checksums generated by
|
||||
the client prior to writing by Machi servers.
|
||||
<td> Each log entry is protected by a 32 bit CRC checksum.
|
||||
|
||||
</table>
|
||||
|
||||
In theory, it should be "quite straightforward" to remove these parts
|
||||
of Kafka's code base:
|
||||
|
||||
* local file system I/O for all topic/partition/log files
|
||||
* leader/follower file replication, ISR ("In Sync Replica") state
|
||||
management, and related log file replication logic
|
||||
|
||||
... and replace those parts with Machi client API calls. Those parts
|
||||
of Kafka are what Machi has been designed to do from the very
|
||||
beginning.
|
||||
|
||||
See also:
|
||||
<a href="#corfu-and-tango">How does Machi differ from CORFU and Tango?</a>
|
||||
|
||||
<a name="n2.4">
|
||||
### 2.4. How does Machi differ from Bookkeeper?
|
||||
|
||||
Sorry, we haven't studied Bookkeeper very deeply or used Bookkeeper
|
||||
for any non-trivial project.
|
||||
|
||||
One notable limitation of the Bookkeeper API is that a ledger cannot
|
||||
be read by other clients until it has been closed. Any byte in a
|
||||
Machi file that has been written successfully may
|
||||
be read immedately by any other Machi client.
|
||||
|
||||
The name "Machi" does not have three consecutive pairs of repeating
|
||||
letters. The name "Bookkeeper" does.
|
||||
|
||||
<a name="corfu-and-tango">
|
||||
<a name="n2.5">
|
||||
### 2.5. How does Machi differ from CORFU and Tango?
|
||||
|
||||
Machi's design borrows very heavily from CORFU. We acknowledge a deep
|
||||
debt to the original Microsoft Research papers that describe CORFU's
|
||||
original design and implementation.
|
||||
|
||||
<table>
|
||||
|
||||
<tr>
|
||||
<td> <b>Machi</b>
|
||||
<td> <b>CORFU</b>
|
||||
|
||||
<tr>
|
||||
<td> Writes & reads may be on byte boundaries
|
||||
<td> Wries & reads must be on page boundaries, e.g. 4 or 8 KBytes, to
|
||||
align with server storage based on flash NVRAM/solid state disk (SSD).
|
||||
|
||||
<tr>
|
||||
<td> Provides multiple "logs", where each log has a name and is
|
||||
appended to & read from like a file. A read operation requires a 3-tuple:
|
||||
file name, starting byte offset, number of bytes.
|
||||
<td> Provides a single "log". A read operation requires only a
|
||||
1-tuple: the log page number. (A protocol option exists to
|
||||
request multiple pages in a single read query?)
|
||||
|
||||
<tr>
|
||||
<td> Offers service in either strongly consistent mode or eventually
|
||||
consistent mode.
|
||||
<td> Offers service in strongly consistent mode.
|
||||
|
||||
<tr>
|
||||
<td> May be deployed on solid state disk (SSD) or Winchester hard disks.
|
||||
<td> Designed for use with solid state disk (SSD) but can also be used
|
||||
with Winchester hard disks (with a performance penalty if used as
|
||||
suggested by use cases described by the CORFU papers).
|
||||
|
||||
<tr>
|
||||
<td> All Machi file data is protected by SHA-1 checksums generated by
|
||||
the client prior to writing by Machi servers.
|
||||
<td> Depending on server & flash device capabilities, each data page
|
||||
may be protected by a checksum (calculated independently by each
|
||||
server rather than the client).
|
||||
|
||||
</table>
|
||||
|
||||
See also: the "Recommended reading & related work" and "References"
|
||||
sections of the
|
||||
[Machi high level design doc](https://github.com/basho/machi/tree/master/doc/high-level-machi.pdf)
|
||||
for pointers to the MSR papers related to CORFU.
|
||||
|
||||
Machi does not implement Tango directly. (Not yet, at least.)
|
||||
However, there is a prototype implementation included in the Machi
|
||||
source tree. See
|
||||
[the prototype/tango source code directory](https://github.com/basho/machi/tree/master/prototype/tango)
|
||||
for details.
|
||||
|
||||
Also, it's worth adding that the original MSR code behind the research
|
||||
papers is now available at GitHub:
|
||||
[https://github.com/CorfuDB/CorfuDB](https://github.com/CorfuDB/CorfuDB).
|
||||
|
||||
<a name="n3">
|
||||
## 3. Machi's specifics
|
||||
|
||||
<a name="n3.1">
|
||||
### 3.1. What technique is used to replicate Machi's files? Can other techniques be used?
|
||||
|
||||
Machi uses Chain Replication to replicate all file data. Each byte of
|
||||
a file is stored using a "write-once register", which is a mechanism
|
||||
to enforce immutability after the byte has been written exactly once.
|
||||
|
||||
In order to ensure availability in the event of *F* failures, Chain
|
||||
Replication requires a minimum of *F + 1* servers to be configured.
|
||||
|
||||
Alternative mechanisms could be used to manage file replicas, such as
|
||||
Paxos or Raft. Both Paxos and Raft have some requirements that are
|
||||
difficult to adapt to Machi's design goals:
|
||||
|
||||
* Both protocols use quorum majority consensus, which requires a
|
||||
minimum of *2F + 1* working servers to tolerate *F* failures. For
|
||||
example, to tolerate 2 server failures, quorum majority protocols
|
||||
require a minimum of 5 servers. To tolerate the same number of
|
||||
failures, Chain Replication requires a minimum of only 3 servers.
|
||||
* Machi's use of "humming consensus" to manage internal server
|
||||
metadata state would also (probably) require conversion to Paxos or
|
||||
Raft. (Or "outsourced" to a service such as ZooKeeper.)
|
||||
|
||||
<a name="n3.2">
|
||||
### 3.2. Does Machi have a reliance on a coordination service such as ZooKeeper or etcd?
|
||||
|
||||
No. Machi maintains critical internal cluster information in an
|
||||
internal, immutable data service called the "projection store". The
|
||||
contents of the projection store are maintained by a new technique
|
||||
called "humming consensus".
|
||||
|
||||
Humming consensus is described in the
|
||||
[Machi chain manager high level design doc](https://github.com/basho/machi/tree/master/doc/high-level-chain-mgr.pdf).
|
||||
|
||||
<a name="n3.3">
|
||||
### 3.3. Are there any presentations available about Humming Consensus
|
||||
|
||||
Scott recently (November 2015) gave a presentation at the
|
||||
[RICON 2015 conference](http://ricon.io) about one of the techniques
|
||||
used by Machi; "Managing Chain Replication Metadata with
|
||||
Humming Consensus" is available online now.
|
||||
* [slides (PDF format)](http://ricon.io/speakers/slides/Scott_Fritchie_Ricon_2015.pdf)
|
||||
* [video](https://www.youtube.com/watch?v=yR5kHL1bu1Q)
|
||||
|
||||
<a name="n3.4">
|
||||
### 3.4. Is it true that there's an allegory written to describe Humming Consensus?
|
||||
|
||||
Yes. In homage to Leslie Lamport's original paper about the Paxos
|
||||
protocol, "The Part-time Parliamant", there is an allegorical story
|
||||
that describes humming consensus as method to coordinate
|
||||
many composers to write a single piece of music.
|
||||
The full story, full of wonder and mystery, is called
|
||||
["On “Humming Consensus”, an allegory"](http://www.snookles.com/slf-blog/2015/03/01/on-humming-consensus-an-allegory/).
|
||||
There is also a
|
||||
[short followup blog posting](http://www.snookles.com/slf-blog/2015/03/20/on-humming-consensus-an-allegory-part-2/).
|
||||
|
||||
<a name="n3.5">
|
||||
### 3.5. How is Machi tested?
|
||||
|
||||
While not formally proven yet, Machi's implementation of Chain
|
||||
Replication and of humming consensus have been extensively tested with
|
||||
several techniques:
|
||||
|
||||
* We use an executable model based on the QuickCheck framework for
|
||||
property based testing.
|
||||
* In addition to QuickCheck alone, we use the PULSE extension to
|
||||
QuickCheck is used to test the implementation
|
||||
under extremely skewed & unfair scheduling/timing conditions.
|
||||
|
||||
The model includes simulation of asymmetric network partitions. For
|
||||
example, actor A can send messages to actor B, but B cannot send
|
||||
messages to A. If such a partition happens somewhere in a traditional
|
||||
network stack (e.g. a faulty Ethernet cable), any TCP connection
|
||||
between A & B will quickly interrupt communication in _both_
|
||||
directions. In the Machi network partition simulator, network
|
||||
partitions can be truly one-way only.
|
||||
|
||||
After randomly generating a series of network partitions (which may
|
||||
change several times during any single test case) and a random series
|
||||
of cluster operations, an event trace of all cluster activity is used
|
||||
to verify that no safety-critical rules have been violated.
|
||||
|
||||
All test code is available in the [./test](./test) subdirectory.
|
||||
Modules that use QuickCheck will use a file suffix of `_eqc`, for
|
||||
example, [./test/machi_ap_repair_eqc.erl](./test/machi_ap_repair_eqc.erl).
|
||||
|
||||
<a name="n3.6">
|
||||
### 3.6. Does Machi require shared disk storage? e.g. iSCSI, NBD (Network Block Device), Fibre Channel disks
|
||||
|
||||
No, Machi's design assumes that each Machi server is a fully
|
||||
independent hardware and assumes only standard local disks (Winchester
|
||||
and/or SSD style) with local-only interfaces (e.g. SATA, SCSI, PCI) in
|
||||
each machine.
|
||||
|
||||
<a name="n3.7">
|
||||
### 3.7. Does Machi require or assume that servers with large numbers of disks must use RAID-0/1/5/6/10/50/60 to create a single block device?
|
||||
|
||||
No. When used with servers with multiple disks, the intent is to
|
||||
deploy multiple Machi servers per machine: one Machi server per disk.
|
||||
|
||||
* Pro: disk bandwidth and disk storage capacity can be managed at the
|
||||
level of an individual disk.
|
||||
* Pro: failure of an individual disk does not risk data loss on other
|
||||
disks.
|
||||
* Con (or pro, depending on the circumstances): in this configuration,
|
||||
Machi would require additional network bandwidth to repair data on a lost
|
||||
drive instead of intra-machine disk & bus & memory bandwidth that
|
||||
would be required for RAID volume repair
|
||||
* Con: replica placement policy, such as "rack awareness", becomes a
|
||||
larger problem that must be automated. For example, a problem of
|
||||
placement relative to 12 servers is smaller than a placement problem
|
||||
of managing 264 seprate disks (if each of 12 servers has 22 disks).
|
||||
|
||||
<a name="n3.8">
|
||||
### 3.8. What language(s) is Machi written in?
|
||||
|
||||
So far, Machi is written in Erlang, mostly. Machi uses at least one
|
||||
library, [ELevelDB](https://github.com/basho/eleveldb), that is
|
||||
implemented both in C++ and in Erlang, using Erlang NIFs (Native
|
||||
Interface Functions) to allow Erlang code to call C++ functions.
|
||||
|
||||
In the event that we encounter a performance problem that cannot be
|
||||
solved within the Erlang/OTP runtime environment, all of Machi's
|
||||
performance-critical components are small enough to be re-implemented
|
||||
in C, Java, or other "gotta go fast fast FAST!!" programming
|
||||
language. We expect that the Chain Replication manager and other
|
||||
critical "control plane" software will remain in Erlang.
|
||||
|
||||
<a name="n3.9">
|
||||
### 3.9. Can Machi run on Windows? Can Machi run on 32-bit platforms?
|
||||
|
||||
The ELevelDB NIF does not compile or run correctly on Erlang/OTP
|
||||
Windows platforms, nor does it compile correctly on 32-bit platforms.
|
||||
Machi should support all 64-bit UNIX-like platforms that are supported
|
||||
by Erlang/OTP and ELevelDB.
|
||||
|
||||
<a name="n3.10">
|
||||
### 3.10. Does Machi use the Erlang/OTP network distribution system (aka "disterl")?
|
||||
|
||||
No, Machi doesn't use Erlang/OTP's built-in distributed message
|
||||
passing system. The code would be *much* simpler if we did use
|
||||
"disterl". However, due to (premature?) worries about performance, we
|
||||
wanted to have the option of re-writing some Machi components in C or
|
||||
Java or Go or OCaml or COBOL or in-kernel assembly hexadecimal
|
||||
bit-twiddling magicSPEED ... without also having to find a replacement
|
||||
for disterl. (Or without having to re-invent disterl's features in
|
||||
another language.)
|
||||
|
||||
All wire protocols used by Machi are defined & implemented using
|
||||
[Protocol Buffers](https://developers.google.com/protocol-buffers/docs/overview).
|
||||
The definition file can be found at [./src/machi.proto](./src/machi.proto).
|
||||
|
||||
<a name="n3.11">
|
||||
### 3.11. Can I use HTTP to write/read stuff into/from Machi?
|
||||
|
||||
Short answer: No, not yet.
|
||||
|
||||
Longer answer: No, but it was possible as a hack, many months ago, see
|
||||
[primitive/hack'y HTTP interface that is described in this source code commit log](https://github.com/basho/machi/commit/6cebf397232cba8e63c5c9a0a8c02ba391b20fef).
|
||||
Please note that commit `6cebf397232cba8e63c5c9a0a8c02ba391b20fef` is
|
||||
required to try using this feature: the code has since bit-rotted and
|
||||
will not work on today's `master` branch.
|
||||
|
||||
In the long term, we'll probably want the option of an HTTP interface
|
||||
that is as well designed and REST'ful as possible. It's on the
|
||||
internal Basho roadmap. If you'd like to work on a real, not-kludgy
|
||||
HTTP interface to Machi,
|
||||
[please contact us!](https://github.com/basho/machi/blob/master/CONTRIBUTING.md)
|
||||
|
||||
297
INSTALLATION.md
|
|
@ -1,297 +0,0 @@
|
|||
|
||||
# Installation instructions for Machi
|
||||
|
||||
Machi is still a young enough project that there is no "installation".
|
||||
All development is still done using the Erlang/OTP interactive shell
|
||||
for experimentation, using `make` to compile, and the shell's
|
||||
`l(ModuleName).` command to reload any recompiled modules.
|
||||
|
||||
In the coming months (mid-2015), there are plans to create OS packages
|
||||
for common operating systems and OS distributions, such as FreeBSD and
|
||||
Linux. If building RPM, DEB, PKG, or other OS package managers is
|
||||
your specialty, we could use your help to speed up the process! <b>:-)</b>
|
||||
|
||||
## Development toolchain dependencies
|
||||
|
||||
Machi's dependencies on the developer's toolchain are quite small.
|
||||
|
||||
* Erlang/OTP version 17.0 or later, 32-bit or 64-bit
|
||||
* The `make` utility.
|
||||
* The GNU version of make is not required.
|
||||
* Machi is bundled with a `rebar` package and should be usable on
|
||||
any Erlang/OTP 17.x platform.
|
||||
|
||||
Machi does not use any Erlang NIF or port drivers.
|
||||
|
||||
## Development OS
|
||||
|
||||
At this time, Machi is 100% Erlang. Although we have not tested it,
|
||||
there should be no good reason why Machi cannot run on Erlang/OTP on
|
||||
Windows platforms. Machi has been developed on OS X and FreeBSD and
|
||||
is expected to work on any UNIX-ish platform supported by Erlang/OTP.
|
||||
|
||||
## Compiling the Machi source
|
||||
|
||||
First, clone the Machi source code, then compile it. You will
|
||||
need Erlang/OTP version 17.x to compile.
|
||||
|
||||
cd /some/nice/dev/place
|
||||
git clone https://github.com/basho/machi.git
|
||||
cd machi
|
||||
make
|
||||
make test
|
||||
|
||||
The unit test suite is based on the EUnit framework (bundled with
|
||||
Erlang/OTP 17). The `make test` suite runs on my MacBook in 10
|
||||
seconds or less.
|
||||
|
||||
## Setting up a Machi cluster
|
||||
|
||||
As noted above, everything is done manually at the moment. Here is a
|
||||
rough sketch of day-to-day development workflow.
|
||||
|
||||
### 1. Run the server
|
||||
|
||||
cd /some/nice/dev/place/machi
|
||||
make
|
||||
erl -pz ebin deps/*/ebin +A 253 +K true
|
||||
|
||||
This will start an Erlang shell, plus a few extras.
|
||||
|
||||
* Tell the OTP code loader where to find dependent BEAM files.
|
||||
* Set a large pool (253) of file I/O worker threads
|
||||
* Use a more efficient kernel polling mechanism for network sockets.
|
||||
* If your Erlang/OTP package does not support `+K true`, do not
|
||||
worry. It is an optional flag.
|
||||
|
||||
The following commands will start three Machi FLU server processes and
|
||||
then tell them to form a single chain. Internally, each FLU will have
|
||||
Erlang registered processes with the names `a`, `b`, and `c`, and
|
||||
listen on TCP ports 4444, 4445, and 4446, respectively. Each will use
|
||||
a data directory located in the current directory, e.g. `./data.a`.
|
||||
|
||||
Cut-and-paste the following commands into the CLI at the prompt:
|
||||
|
||||
application:ensure_all_started(machi).
|
||||
machi_flu_psup:start_flu_package(a, 4444, "./data.a", []).
|
||||
machi_flu_psup:start_flu_package(b, 4445, "./data.b", []).
|
||||
D = orddict:from_list([{a,{p_srvr,a,machi_flu1_client,"localhost",4444,[]}},{b,{p_srvr,b,machi_flu1_client,"localhost",4445,[]}}]).
|
||||
machi_chain_manager1:set_chain_members(a_chmgr, D).
|
||||
machi_chain_manager1:set_chain_members(b_chmgr, D).
|
||||
|
||||
If you change the TCP ports of any of the processes, you must make the
|
||||
same change both in the `machi_flu_psup:start_flu_package()` arguments
|
||||
and also in the `D` dictionary.
|
||||
|
||||
The Erlang processes that will be started are arranged in the
|
||||
following hierarchy. See the
|
||||
[machi_flu_psup.erl](http://basho.github.io/machi/edoc/machi_flu_psup.html)
|
||||
EDoc documentation for a description of each of these processes.
|
||||
|
||||
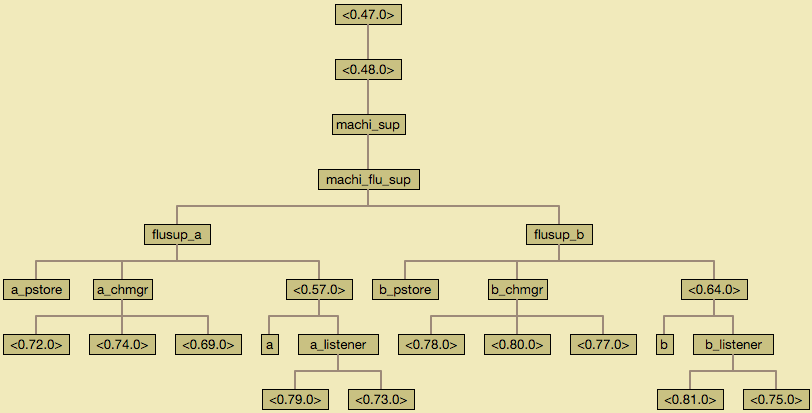
|
||||
|
||||
### 2. Check the status of the server processes.
|
||||
|
||||
Each Machi FLU is an independent file server. All replication between
|
||||
Machi servers is currently implemented by code on the *client* side.
|
||||
(This will change a bit later in 2015.)
|
||||
|
||||
Use the `read_latest_projection` command on the server CLI, e.g.:
|
||||
|
||||
rr("include/machi_projection.hrl").
|
||||
machi_projection_store:read_latest_projection(a_pstore, private).
|
||||
|
||||
... to query the projection store of the local FLU named `a`.
|
||||
|
||||
If you haven't looked at the server-side description of the various
|
||||
Machi server-side processes, please take a couple minutes to read
|
||||
[machi_flu_psup.erl](http://basho.github.io/machi/edoc/machi_flu_psup.html).
|
||||
|
||||
### 3. Use the machi_cr_client.erl client
|
||||
|
||||
For development work, I run the client & server on the same Erlang
|
||||
VM. It's just easier that way ... but the Machi client & server use
|
||||
TCP to communicate with each other.
|
||||
|
||||
If you are using a separate machine for the client, then compile the
|
||||
Machi source on the client machine. Then run:
|
||||
|
||||
cd /some/nice/dev/place/machi
|
||||
make
|
||||
erl -pz ebin deps/*/ebin
|
||||
|
||||
(You can add `+K true` if you wish ... but for light development work,
|
||||
it doesn't make a big difference.)
|
||||
|
||||
At the CLI, define the dictionary that describes the host & TCP port
|
||||
location for each of the Machi servers. (If you changed the host
|
||||
and/or TCP port values when starting the servers, then place make the
|
||||
same changes here.
|
||||
|
||||
D = orddict:from_list([{a,{p_srvr,a,machi_flu1_client,"localhost",4444,[]}},{b,{p_srvr,b,machi_flu1_client,"localhost",4445,[]}}]).
|
||||
|
||||
Then start a `machi_cr_client` client process.
|
||||
|
||||
{ok, C1} = machi_cr_client:start_link([P || {_,P} <- orddict:to_list(D)]).
|
||||
|
||||
Please keep in mind that this process is **linked** to your CLI
|
||||
process. If you run a CLI command the throws an exception/exits, then
|
||||
this `C1` process will also die! You can start a new one, using a
|
||||
different name, e.g. `C2`. Or you can start a new one by first
|
||||
"forgetting" the CLI's binding for `C1`.
|
||||
|
||||
f(C1).
|
||||
{ok, C1} = machi_cr_client:start_link([P || {_,P} <- orddict:to_list(D)]).
|
||||
|
||||
Now, append a small chunk of data to a file with the prefix
|
||||
`<<"pre">>`.
|
||||
|
||||
12> {ok, C1} = machi_cr_client:start_link([P || {_,P} <- orddict:to_list(D)]).
|
||||
{ok,<0.112.0>}
|
||||
|
||||
13> machi_cr_client:append_chunk(C1, <<"pre">>, <<"Hello, world">>).
|
||||
{ok,{1024,12,<<"pre.G6C116EA.3">>}}
|
||||
|
||||
|
||||
This chunk was written successfully to a file called
|
||||
`<<"pre.5BBL16EA.1">>` at byte offset 1024. Let's fetch it now. And
|
||||
let's see what happens in a couple of error conditions: fetching
|
||||
bytes that "straddle" the end of file, bytes that are after the known
|
||||
end of file, and bytes from a file that has never been written.
|
||||
|
||||
26> machi_cr_client:read_chunk(C1, <<"pre.G6C116EA.3">>, 1024, 12).
|
||||
{ok,<<"Hello, world">>}
|
||||
|
||||
27> machi_cr_client:read_chunk(C1, <<"pre.G6C116EA.3">>, 1024, 777).
|
||||
{error,partial_read}
|
||||
|
||||
28> machi_cr_client:read_chunk(C1, <<"pre.G6C116EA.3">>, 889323, 12).
|
||||
{error,not_written}
|
||||
|
||||
29> machi_cr_client:read_chunk(C1, <<"no-such-file">>, 1024, 12).
|
||||
{error,not_written}
|
||||
|
||||
### 4. Use the `machi_proxy_flu1_client.erl` client
|
||||
|
||||
The `machi_proxy_flu1_client` module implements a simpler client that
|
||||
only uses a single Machi FLU file server. This client is **not**
|
||||
aware of chain replication in any way.
|
||||
|
||||
Let's use this client to verify that the `<<"Hello, world!">> data
|
||||
that we wrote in step #3 was truly written to both FLU servers by the
|
||||
`machi_cr_client` library. We start proxy processes for each of the
|
||||
FLUs, then we'll query each ... but first we also need to ask (at
|
||||
least one of) the servers for the current Machi cluster's Epoch ID.
|
||||
|
||||
{ok, Pa} = machi_proxy_flu1_client:start_link(orddict:fetch(a, D)).
|
||||
{ok, Pb} = machi_proxy_flu1_client:start_link(orddict:fetch(b, D)).
|
||||
{ok, EpochID0} = machi_proxy_flu1_client:get_epoch_id(Pa).
|
||||
machi_proxy_flu1_client:read_chunk(Pa, EpochID0, <<"pre.G6C116EA.3">>, 1024, 12).
|
||||
machi_proxy_flu1_client:read_chunk(Pb, EpochID0, <<"pre.G6C116EA.3">>, 1024, 12).
|
||||
|
||||
### 5. Checking how Chain Replication "read repair" works
|
||||
|
||||
Now, let's cause some trouble: we will write some data only to the
|
||||
head of the chain. By default, all read operations go to the tail of
|
||||
the chain. But, if a value is not written at the tail, then "read
|
||||
repair" ought to verify:
|
||||
|
||||
* Perhaps the value truly is not written at any server in the chain.
|
||||
* Perhaps the value was partially written, i.e. by a buggy or
|
||||
crashed-in-the-middle-of-the-writing-procedure client.
|
||||
|
||||
So, first, let's double-check that the chain is in the order that we
|
||||
expect it to be.
|
||||
|
||||
rr("include/machi_projection.hrl"). % In case you didn't do this earlier.
|
||||
machi_proxy_flu1_client:read_latest_projection(Pa, private).
|
||||
|
||||
The part of the `#projection_v1` record that we're interested in is
|
||||
the `upi`. This is the list of servers that preserve the Update
|
||||
Propagation Invariant property of the Chain Replication algorithm.
|
||||
The output should look something like:
|
||||
|
||||
{ok,#projection_v1{
|
||||
epoch_number = 1119,
|
||||
[...]
|
||||
author_server = b,
|
||||
all_members = [a,b],
|
||||
creation_time = {1432,189599,85392},
|
||||
mode = ap_mode,
|
||||
upi = [a,b],
|
||||
repairing = [],down = [],
|
||||
[...]
|
||||
}
|
||||
|
||||
So, we see `upi=[a,b]`, which means that FLU `a` is the head of the
|
||||
chain and that `b` is the tail.
|
||||
|
||||
Let's append to `a` using the `machi_proxy_flu1_client` to the head
|
||||
and then read from both the head and tail. (If your chain order is
|
||||
different, then please exchange `Pa` and `Pb` in all of the commands
|
||||
below.)
|
||||
|
||||
16> {ok, {Off1,Size1,File1}} = machi_proxy_flu1_client:append_chunk(Pa, EpochID0, <<"foo">>, <<"Hi, again">>).
|
||||
{ok,{1024,9,<<"foo.K63D16M4.1">>}}
|
||||
|
||||
17> machi_proxy_flu1_client:read_chunk(Pa, EpochID0, File1, Off1, Size1). {ok,<<"Hi, again">>}
|
||||
|
||||
18> machi_proxy_flu1_client:read_chunk(Pb, EpochID0, File1, Off1, Size1).
|
||||
{error,not_written}
|
||||
|
||||
That is correct! Now, let's read the same file & offset using the
|
||||
client that understands chain replication. Then we will try reading
|
||||
directly from FLU `b` again ... we should see something different.
|
||||
|
||||
19> {ok, C2} = machi_cr_client:start_link([P || {_,P} <- orddict:to_list(D)]).
|
||||
{ok,<0.113.0>}
|
||||
|
||||
20> machi_cr_client:read_chunk(C2, File1, Off1, Size1).
|
||||
{ok,<<"Hi, again">>}
|
||||
|
||||
21> machi_proxy_flu1_client:read_chunk(Pb, EpochID0, File1, Off1, Size1).
|
||||
{ok,<<"Hi, again">>}
|
||||
|
||||
That is correct! The command at prompt #20 automatically performed
|
||||
"read repair" on FLU `b`.
|
||||
|
||||
### 6. Exploring what happens when a server is stopped, data written, and server restarted
|
||||
|
||||
Cut-and-paste the following into your CLI. We assume that your CLI
|
||||
still remembers the value of the `D` dictionary from the previous
|
||||
steps above. We will stop FLU `a`, write one thousand small
|
||||
chunks, then restart FLU `a`, then see what happens.
|
||||
|
||||
{ok, C3} = machi_cr_client:start_link([P || {_,P} <- orddict:to_list(D)]).
|
||||
machi_flu_psup:stop_flu_package(a).
|
||||
[machi_cr_client:append_chunk(C3, <<"foo">>, <<"Lots of stuff">>) || _ <- lists:seq(1,1000)].
|
||||
machi_flu_psup:start_flu_package(a, 4444, "./data.a", []).
|
||||
|
||||
About 10 seconds after we restarting `a` with the
|
||||
`machi_flu_psup:start_flu_package()` function, this appears on the
|
||||
console:
|
||||
|
||||
=INFO REPORT==== 21-May-2015::15:53:46 ===
|
||||
Repair start: tail b of [b] -> [a], ap_mode ID {b,{1432,191226,707262}}
|
||||
MissingFileSummary [{<<"foo.CYLJ16ZT.1">>,{14024,[a]}}]
|
||||
Make repair directives: . done
|
||||
Out-of-sync data for FLU a: 0.1 MBytes
|
||||
Out-of-sync data for FLU b: 0.0 MBytes
|
||||
Execute repair directives: .......... done
|
||||
|
||||
=INFO REPORT==== 21-May-2015::15:53:47 ===
|
||||
Repair success: tail b of [b] finished ap_mode repair ID {b,{1432,191226,707262}}: ok
|
||||
Stats [{t_in_files,0},{t_in_chunks,1000},{t_in_bytes,13000},{t_out_files,0},{t_out_chunks,1000},{t_out_bytes,13000},{t_bad_chunks,0},{t_elapsed_seconds,0.647}]
|
||||
|
||||
The data repair process, executed by `b`'s chain manager, found 1000
|
||||
chunks that were out of sync and copied them to `a` successfully.
|
||||
|
||||
### 7. Exploring the rest of the client APIs
|
||||
|
||||
Please see the EDoc documentation for the client APIs. Feel free to
|
||||
explore!
|
||||
|
||||
* [Erlang type definitions for the client APIs](http://basho.github.io/machi/edoc/machi_flu1_client.html)
|
||||
* [EDoc for machi_cr_client.erl](http://basho.github.io/machi/edoc/machi_cr_client.html)
|
||||
* [EDoc for machi_proxy_flu1_client.erl](http://basho.github.io/machi/edoc/machi_proxy_flu1_client.html)
|
||||
* [Top level EDoc collection](http://basho.github.io/machi/edoc/)
|
||||
178
LICENSE
|
|
@ -1,178 +0,0 @@
|
|||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
94
Makefile
|
|
@ -1,94 +0,0 @@
|
|||
REPO ?= machi
|
||||
PKG_REVISION ?= $(shell git describe --tags)
|
||||
PKG_BUILD = 1
|
||||
BASE_DIR = $(shell pwd)
|
||||
ERLANG_BIN = $(shell dirname $(shell which erl))
|
||||
REBAR := $(shell which rebar)
|
||||
ifeq ($(REBAR),)
|
||||
REBAR = $(BASE_DIR)/rebar
|
||||
endif
|
||||
OVERLAY_VARS ?=
|
||||
EUNIT_OPTS = -v
|
||||
|
||||
.PHONY: rel stagedevrel deps package pkgclean edoc
|
||||
|
||||
all: deps compile
|
||||
|
||||
compile:
|
||||
$(REBAR) compile
|
||||
|
||||
## Make reltool happy by creating a fake entry in the deps dir for
|
||||
## machi, because reltool really wants to have a path with
|
||||
## "machi/ebin" at the end, but we also don't want infinite recursion
|
||||
## if we just symlink "deps/machi" -> ".."
|
||||
|
||||
generate:
|
||||
rm -rf deps/machi
|
||||
mkdir deps/machi
|
||||
ln -s ../../ebin deps/machi
|
||||
ln -s ../../src deps/machi
|
||||
$(REBAR) generate $(OVERLAY_VARS) 2>&1 | grep -v 'command does not apply to directory'
|
||||
|
||||
deps:
|
||||
$(REBAR) get-deps
|
||||
|
||||
clean:
|
||||
$(REBAR) -r clean
|
||||
|
||||
edoc: edoc-clean
|
||||
$(REBAR) skip_deps=true doc
|
||||
|
||||
edoc-clean:
|
||||
rm -f edoc/*.png edoc/*.html edoc/*.css edoc/edoc-info
|
||||
|
||||
pulse: compile
|
||||
@echo Sorry, PULSE test needs maintenance. -SLF
|
||||
#env USE_PULSE=1 $(REBAR) skip_deps=true clean compile
|
||||
#env USE_PULSE=1 $(REBAR) skip_deps=true -D PULSE eunit -v
|
||||
|
||||
##
|
||||
## Release targets
|
||||
##
|
||||
rel: deps compile generate
|
||||
|
||||
relclean:
|
||||
rm -rf rel/$(REPO)
|
||||
|
||||
stage : rel
|
||||
$(foreach dep,$(wildcard deps/*), rm -rf rel/$(REPO)/lib/$(shell basename $(dep))* && ln -sf $(abspath $(dep)) rel/$(REPO)/lib;)
|
||||
|
||||
##
|
||||
## Developer targets
|
||||
##
|
||||
## devN - Make a dev build for node N
|
||||
## stagedevN - Make a stage dev build for node N (symlink libraries)
|
||||
## devrel - Make a dev build for 1..$DEVNODES
|
||||
## stagedevrel Make a stagedev build for 1..$DEVNODES
|
||||
##
|
||||
## Example, make a 68 node devrel cluster
|
||||
## make stagedevrel DEVNODES=68
|
||||
|
||||
.PHONY : stagedevrel devrel
|
||||
DEVNODES ?= 3
|
||||
|
||||
# 'seq' is not available on all *BSD, so using an alternate in awk
|
||||
SEQ = $(shell awk 'BEGIN { for (i = 1; i < '$(DEVNODES)'; i++) printf("%i ", i); print i ;exit(0);}')
|
||||
|
||||
$(eval stagedevrel : $(foreach n,$(SEQ),stagedev$(n)))
|
||||
$(eval devrel : $(foreach n,$(SEQ),dev$(n)))
|
||||
|
||||
dev% : all
|
||||
mkdir -p dev
|
||||
rel/gen_dev $@ rel/vars/dev_vars.config.src rel/vars/$@_vars.config
|
||||
(cd rel && ../rebar generate target_dir=../dev/$@ overlay_vars=vars/$@_vars.config)
|
||||
|
||||
stagedev% : dev%
|
||||
$(foreach dep,$(wildcard deps/*), rm -rf dev/$^/lib/$(shell basename $(dep))* && ln -sf $(abspath $(dep)) dev/$^/lib;)
|
||||
|
||||
devclean: clean
|
||||
rm -rf dev
|
||||
|
||||
DIALYZER_APPS = kernel stdlib sasl erts ssl compiler eunit crypto public_key syntax_tools
|
||||
PLT = $(HOME)/.machi_dialyzer_plt
|
||||
|
||||
include tools.mk
|
||||
6
NOTICE
|
|
@ -1,6 +0,0 @@
|
|||
Machi
|
||||
Copyright 2007-2015 Basho Technologies
|
||||
|
||||
This product contains code developed at Basho Technologies.
|
||||
(http://www.basho.com/)
|
||||
|
||||
174
README.md
|
|
@ -1,174 +0,0 @@
|
|||
# Machi: a distributed, decentralized blob/large file store
|
||||
|
||||
[Travis-CI](http://travis-ci.org/basho/machi) :: 
|
||||
|
||||
Outline
|
||||
|
||||
1. [Why another blob/file store?](#sec1)
|
||||
2. [Where to learn more about Machi](#sec2)
|
||||
3. [Development status summary](#sec3)
|
||||
4. [Contributing to Machi's development](#sec4)
|
||||
|
||||
<a name="sec1">
|
||||
## 1. Why another blob/file store?
|
||||
|
||||
Our goal is a robust & reliable, distributed, highly available, large
|
||||
file and blob store. Such stores already exist, both in the open source world
|
||||
and in the commercial world. Why reinvent the wheel? We believe
|
||||
there are three reasons, ordered by decreasing rarity.
|
||||
|
||||
1. We want end-to-end checksums for all file data, from the initial
|
||||
file writer to every file reader, anywhere, all the time.
|
||||
2. We need flexibility to trade consistency for availability:
|
||||
e.g. weak consistency in exchange for being available in cases
|
||||
of partial system failure.
|
||||
3. We want to manage file replicas in a way that's provably correct
|
||||
and also easy to test.
|
||||
|
||||
Criteria #3 is difficult to find in the open source world but perhaps
|
||||
not impossible.
|
||||
|
||||
If we have app use cases where availability is more important than
|
||||
consistency, then systems that meet criteria #2 are also rare.
|
||||
Most file stores provide only strong consistency and therefore
|
||||
have unavoidable, unavailable behavior when parts of the system
|
||||
fail.
|
||||
What if we want a file store that is always available to write new
|
||||
file data and attempts best-effort file reads?
|
||||
|
||||
If we really do care about data loss and/or data corruption, then we
|
||||
really want both #3 and #1. Unfortunately, systems that meet
|
||||
criteria #1 are _very rare_. (Nonexistant?)
|
||||
Why? This is 2015. We have decades of research that shows
|
||||
that computer hardware can (and
|
||||
indeed does) corrupt data at nearly every level of the modern
|
||||
client/server application stack. Systems with end-to-end data
|
||||
corruption detection should be ubiquitous today. Alas, they are not.
|
||||
|
||||
Machi is an effort to change the deplorable state of the world, one
|
||||
Erlang function at a time.
|
||||
|
||||
<a name="sec2">
|
||||
## 2. Where to learn more about Machi
|
||||
|
||||
The two major design documents for Machi are now mostly stable.
|
||||
Please see the [doc](./doc) directory's [README](./doc) for details.
|
||||
|
||||
We also have a
|
||||
[Frequently Asked Questions (FAQ) list](./FAQ.md).
|
||||
|
||||
Scott recently (November 2015) gave a presentation at the
|
||||
[RICON 2015 conference](http://ricon.io) about one of the techniques
|
||||
used by Machi; "Managing Chain Replication Metadata with
|
||||
Humming Consensus" is available online now.
|
||||
* [slides (PDF format)](http://ricon.io/speakers/slides/Scott_Fritchie_Ricon_2015.pdf)
|
||||
* [video](https://www.youtube.com/watch?v=yR5kHL1bu1Q)
|
||||
|
||||
See later in this document for how to run the Humming Consensus demos,
|
||||
including the network partition simulator.
|
||||
|
||||
<a name="sec3">
|
||||
## 3. Development status summary
|
||||
|
||||
Mid-March 2016: The Machi development team has been downsized in
|
||||
recent months, and the pace of development has slowed. Here is a
|
||||
summary of the status of Machi's major components.
|
||||
|
||||
* Humming Consensus and the chain manager
|
||||
* No new safety bugs have been found by model-checking tests.
|
||||
* A new document,
|
||||
[Hands-on experiments with Machi and Humming Consensus](doc/humming-consensus-demo.md)
|
||||
is now available. It is a tutorial for setting up a 3 virtual
|
||||
machine Machi cluster and how to demonstrate the chain manager's
|
||||
reactions to server stops & starts, crashes & restarts, and pauses
|
||||
(simulated by `SIGSTOP` and `SIGCONT`).
|
||||
* The chain manager can still make suboptimal-but-safe choices for
|
||||
chain transitions when a server hangs/pauses temporarily.
|
||||
* Recent chain manager changes have made the instability window
|
||||
much shorter when the slow/paused server resumes execution.
|
||||
* Scott believes that a modest change to the chain manager's
|
||||
calculation of a new projection can reduce flapping in this (and
|
||||
many other cases) less likely. Currently, the new local
|
||||
projection is calculated using only local state (i.e., the chain
|
||||
manager's internal state + the fitness server's state).
|
||||
However, if the "latest" projection read from the public
|
||||
projection stores were also input to the new projection
|
||||
calculation function, then many obviously bad projections can be
|
||||
avoided without needing rounds of Humming Consensus to
|
||||
demonstrate that a bad projection is bad.
|
||||
|
||||
* FLU/data server process
|
||||
* All known correctness bugs have been fixed.
|
||||
* Performance has not yet been measured. Performance measurement
|
||||
and enhancements are scheduled to start in the middle of March 2016.
|
||||
(This will include a much-needed update to the `basho_bench` driver.)
|
||||
|
||||
* Access protocols and client libraries
|
||||
* The protocol used by both external clients and internally (instead
|
||||
of using Erlang's native message passing mechanisms) is based on
|
||||
Protocol Buffers.
|
||||
* (Machi PB protocol specification: ./src/machi.proto)[./src/machi.proto]
|
||||
* At the moment, the PB specification contains two protocols.
|
||||
Sometime in the near future, the spec will be split to separate
|
||||
the external client API (the "high" protocol) from the internal
|
||||
communication API (the "low" protocol).
|
||||
|
||||
* Recent conference talks about Machi
|
||||
* Erlang Factory San Francisco 2016
|
||||
[the slides and video recording](http://www.erlang-factory.com/sfbay2016/scott-lystig-fritchie)
|
||||
will be available a few weeks after the conference ends on March
|
||||
11, 2016.
|
||||
* Ricon 2015
|
||||
* [The slides](http://ricon.io/archive/2015/slides/Scott_Fritchie_Ricon_2015.pdf)
|
||||
* and the [video recording](https://www.youtube.com/watch?v=yR5kHL1bu1Q&index=13&list=PL9Jh2HsAWHxIc7Tt2M6xez_TOP21GBH6M)
|
||||
are now available.
|
||||
* If you would like to run the Humming Consensus code (with or without
|
||||
the network partition simulator) as described in the RICON 2015
|
||||
presentation, please see the
|
||||
[Humming Consensus demo doc](./doc/humming_consensus_demo.md).
|
||||
|
||||
<a name="sec4">
|
||||
## 4. Contributing to Machi's development
|
||||
|
||||
### 4.1 License
|
||||
|
||||
Basho Technologies, Inc. as committed to licensing all work for Machi
|
||||
under the
|
||||
[Apache Public License version 2](./LICENSE). All authors of source code
|
||||
and documentation who agree with these licensing terms are welcome to
|
||||
contribute their ideas in any form: suggested design or features,
|
||||
documentation, and source code.
|
||||
|
||||
Machi is still a very young project within Basho, with a small team of
|
||||
developers; please bear with us as we grow out of "toddler" stage into
|
||||
a more mature open source software project.
|
||||
We invite all contributors to review the
|
||||
[CONTRIBUTING.md](./CONTRIBUTING.md) document for guidelines for
|
||||
working with the Basho development team.
|
||||
|
||||
### 4.2 Development environment requirements
|
||||
|
||||
All development to date has been done with Erlang/OTP version 17 on OS
|
||||
X. The only known limitations for using R16 are minor type
|
||||
specification difference between R16 and 17, but we strongly suggest
|
||||
continuing development using version 17.
|
||||
|
||||
We also assume that you have the standard UNIX/Linux developer
|
||||
tool chain for C and C++ applications. Also, we assume
|
||||
that Git and GNU Make are available.
|
||||
The utility used to compile the Machi source code,
|
||||
`rebar`, is pre-compiled and included in the repo.
|
||||
For more details, please see the
|
||||
[Machi development environment prerequisites doc](./doc/dev-prerequisites.md).
|
||||
|
||||
Machi has a dependency on the
|
||||
[ELevelDB](https://github.com/basho/eleveldb) library. ELevelDB only
|
||||
supports UNIX/Linux OSes and 64-bit versions of Erlang/OTP only; we
|
||||
apologize to Windows-based and 32-bit-based Erlang developers for this
|
||||
restriction.
|
||||
|
||||
### 4.3 New protocols and features
|
||||
|
||||
If you'd like to work on a protocol such as Thrift, UBF,
|
||||
msgpack over UDP, or some other protocol, let us know by
|
||||
[opening an issue to discuss it](./issues/new).
|
||||
|
|
@ -1,114 +0,0 @@
|
|||
* To Do list
|
||||
|
||||
** DONE remove the escript* stuff from machi_util.erl
|
||||
** DONE Add functions to manipulate 1-chain projections
|
||||
|
||||
- Add epoch ID = epoch number + checksum of projection!
|
||||
Done via compare() func.
|
||||
|
||||
** DONE Change all protocol ops to add epoch ID
|
||||
** DONE Add projection store to each FLU.
|
||||
|
||||
*** DONE What should the API look like? (borrow from chain mgr PoC?)
|
||||
|
||||
Yeah, I think that's pretty complete. Steal it now, worry later.
|
||||
|
||||
*** DONE Choose protocol & TCP port. Share with get/put? Separate?
|
||||
|
||||
Hrm, I like the idea of having a single TCP port to talk to any single
|
||||
FLU.
|
||||
|
||||
To make the protocol "easy" to hack, how about using the same basic
|
||||
method as append/write where there's a variable size blob. But we'll
|
||||
format that blob as a term_to_binary(). Then dispatch to a single
|
||||
func, and pattern match Erlang style in that func.
|
||||
|
||||
*** DONE Do it.
|
||||
|
||||
** DONE Finish OTP'izing the Chain Manager with FLU & proj store processes
|
||||
** DONE Eliminate the timeout exception for the client: just {error,timeout} ret
|
||||
** DONE Move prototype/chain-manager code to "top" of source tree
|
||||
*** DONE Preserve current test code (leave as-is? tiny changes?)
|
||||
*** DONE Make chain manager code flexible enough to run "real world" or "sim"
|
||||
** DONE Add projection wedging logic to each FLU.
|
||||
** DONE Implement real data repair, orchestrated by the chain manager
|
||||
** DONE Change all protocol ops to enforce the epoch ID
|
||||
|
||||
- Add no-wedging state to make testing easier?
|
||||
|
||||
|
||||
** DONE Adapt the projection-aware, CR-implementing client from demo-day
|
||||
** DONE Add major comment sections to the CR-impl client
|
||||
** DONE Simple basho_bench driver, put some unscientific chalk on the benchtop
|
||||
** TODO Create parallel PULSE test for basic API plus chain manager repair
|
||||
** DONE Add client-side vs. server-side checksum type, expand client API?
|
||||
** TODO Add gproc and get rid of registered name rendezvous
|
||||
*** TODO Fixes the atom table leak
|
||||
*** TODO Fixes the problem of having active sequencer for the same prefix
|
||||
on two FLUS in the same VM
|
||||
|
||||
** TODO Fix all known bugs/cruft with Chain Manager (list below)
|
||||
*** DONE Fix known bugs
|
||||
*** DONE Clean up crufty TODO comments and other obvious cruft
|
||||
*** TODO Re-add verification step of stable epochs, including inner projections!
|
||||
*** TODO Attempt to remove cruft items in flapping_i?
|
||||
|
||||
** TODO Move the FLU server to gen_server behavior?
|
||||
|
||||
|
||||
* DONE Chain manager CP mode, Plan B
|
||||
** SKIP Maybe? Change ch_mgr to use middleworker
|
||||
**** DONE Is it worthwhile? Is the parallelism so important? No, probably.
|
||||
**** SKIP Move middleworker func to utility module?
|
||||
** DONE Add new proc to psup group
|
||||
*** DONE Name: machi_fitness
|
||||
** DONE ch_mgr keeps its current proc struct: i.e. same 1 proc as today
|
||||
** NO chmgr asks hosed mgr for hosed list @ start of react_to_env
|
||||
** DONE For all hosed, do *async*: try to read latest proj.
|
||||
*** NO If OK, inform hosed mgr: status change will be used by next HC iter.
|
||||
*** NO If fail, no change, because that server is already known to be hosed
|
||||
*** DONE For all non-hosed, continue as the chain manager code does today
|
||||
*** DONE Any new errors are added to UpNodes/DownNodes tracking as used today
|
||||
*** DONE At end of react loop, if UpNodes list differs, inform hosed mgr.
|
||||
|
||||
* DONE fitness_mon, the fitness monitor
|
||||
** DONE Map key & val sketch
|
||||
|
||||
Logical sketch:
|
||||
|
||||
Map key: ObservingServerName::atom()
|
||||
|
||||
Map val: { ObservingServerLastModTime::now(),
|
||||
UnfitList::list(ServerName::atom()),
|
||||
AdminDownList::list(ServerName::atom()),
|
||||
Props::proplist() }
|
||||
|
||||
Implementation sketch:
|
||||
|
||||
1. Use CRDT map.
|
||||
2. If map key is not atom, then atom->string or atom->binary is fine.
|
||||
3. For map value, is it possible CRDT LWW type?
|
||||
|
||||
** DONE Investigate riak_dt data structure definition, manipulating, etc.
|
||||
** DONE Add dependency on riak_dt
|
||||
** DONE Update is an entire dict from Observer O
|
||||
*** DONE Merge my pending map + update map + my last mod time + my unfit list
|
||||
*** DONE if merged /= pending:
|
||||
**** DONE Schedule async tick (more)
|
||||
|
||||
Tick message contains list of servers with differing state as of this
|
||||
instant in time... we want to avoid triggering decisions about
|
||||
fitness/unfitness for other servers where we might have received less
|
||||
than a full time period's worth of waiting.
|
||||
|
||||
**** DONE Spam merged map to All_list -- [Me]
|
||||
**** DONE Set pending <- merged
|
||||
|
||||
*** DONE When we receive an async tick
|
||||
**** DONE set active map <- pending map for all servers in ticks list
|
||||
**** DONE Send ch_mgr a react_to_env tick trigger
|
||||
*** DONE react_to_env tick trigger actions
|
||||
**** DONE Filter active map to remove stale entries (i.e. no update in 1 hour)
|
||||
**** DONE If time since last map spam is too long, spam our *pending* map
|
||||
**** DONE Proceed with normal react processing, using *active* map for AllHosed!
|
||||
|
||||
|
|
@ -1,15 +0,0 @@
|
|||
### The auto-generated code of machi_pb.beam has some complaints, not fixed yet.
|
||||
machi_pb.erl:0:
|
||||
##################################################
|
||||
######## Specific types #####################
|
||||
##################################################
|
||||
Unknown types:
|
||||
basho_bench_config:get/2
|
||||
machi_partition_simulator:get/1
|
||||
hamcrest:matchspec/0
|
||||
##################################################
|
||||
######## Specific messages #####################
|
||||
##################################################
|
||||
machi_chain_manager1.erl:2473: The created fun has no local return
|
||||
machi_chain_manager1.erl:2184: The pattern <_P1, P2, Else = {'expected_author2', UPI1_tail, _}> can never match the type <#projection_v1{epoch_number::'undefined' | non_neg_integer(),epoch_csum::'undefined' | binary(),author_server::atom(),chain_name::atom(),all_members::'undefined' | [atom()],witnesses::[atom()],creation_time::'undefined' | {non_neg_integer(),non_neg_integer(),non_neg_integer()},mode::'ap_mode' | 'cp_mode',upi::'undefined' | [atom()],repairing::'undefined' | [atom()],down::'undefined' | [atom()],dbg::'undefined' | [any()],dbg2::'undefined' | [any()],members_dict::'undefined' | [{_,_}]},#projection_v1{epoch_number::'undefined' | non_neg_integer(),epoch_csum::binary(),author_server::atom(),chain_name::atom(),all_members::'undefined' | [atom()],witnesses::[atom()],creation_time::'undefined' | {non_neg_integer(),non_neg_integer(),non_neg_integer()},mode::'ap_mode' | 'cp_mode',upi::'undefined' | [atom()],repairing::'undefined' | [atom()],down::'undefined' | [atom()],dbg::'undefined' | [any()],dbg2::'undefined' | [any()],members_dict::'undefined' | [{_,_}]},'true'>
|
||||
machi_chain_manager1.erl:2233: The pattern <_P1 = {'projection_v1', _, _, _, _, _, _, _, 'cp_mode', UPI1, Repairing1, _, _, _, _}, _P2 = {'projection_v1', _, _, _, _, _, _, _, 'cp_mode', UPI2, Repairing2, _, _, _, _}, Else = {'epoch_not_si', EpochX, 'not_gt', EpochY}> can never match the type <#projection_v1{epoch_number::'undefined' | non_neg_integer(),epoch_csum::'undefined' | binary(),author_server::atom(),chain_name::atom(),all_members::'undefined' | [atom()],witnesses::[atom()],creation_time::'undefined' | {non_neg_integer(),non_neg_integer(),non_neg_integer()},mode::'ap_mode' | 'cp_mode',upi::'undefined' | [atom()],repairing::'undefined' | [atom()],down::'undefined' | [atom()],dbg::'undefined' | [any()],dbg2::'undefined' | [any()],members_dict::'undefined' | [{_,_}]},#projection_v1{epoch_number::'undefined' | non_neg_integer(),epoch_csum::binary(),author_server::atom(),chain_name::atom(),all_members::'undefined' | [atom()],witnesses::[atom()],creation_time::'undefined' | {non_neg_integer(),non_neg_integer(),non_neg_integer()},mode::'ap_mode' | 'cp_mode',upi::'undefined' | [atom()],repairing::'undefined' | [atom()],down::'undefined' | [atom()],dbg::'undefined' | [any()],dbg2::'undefined' | [any()],members_dict::'undefined' | [{_,_}]},'true'>
|
||||
|
|
@ -1,74 +0,0 @@
|
|||
## Machi Documentation Overview
|
||||
|
||||
For a Web-browsable version of a snapshot of the source doc "EDoc"
|
||||
Erlang documentation, please use this link:
|
||||
[Machi EDoc snapshot](https://basho.github.io/machi/edoc/).
|
||||
|
||||
## Documents in this directory
|
||||
|
||||
### high-level-machi.pdf
|
||||
|
||||
[high-level-machi.pdf](high-level-machi.pdf)
|
||||
is an overview of the high level design for
|
||||
Machi. Its abstract:
|
||||
|
||||
> Our goal is a robust & reliable, distributed, highly available large
|
||||
> file store based upon write-once registers, append-only files, Chain
|
||||
> Replication, and client-server style architecture. All members of
|
||||
> the cluster store all of the files. Distributed load
|
||||
> balancing/sharding of files is outside of the scope of this system.
|
||||
> However, it is a high priority that this system be able to integrate
|
||||
> easily into systems that do provide distributed load balancing,
|
||||
> e.g., Riak Core. Although strong consistency is a major feature of
|
||||
> Chain Replication, this document will focus mainly on eventual
|
||||
> consistency features --- strong consistency design will be discussed
|
||||
> in a separate document.
|
||||
|
||||
### high-level-chain-mgr.pdf
|
||||
|
||||
[high-level-chain-mgr.pdf](high-level-chain-mgr.pdf)
|
||||
is an overview of the techniques used by
|
||||
Machi to manage Chain Replication metadata state. It also provides an
|
||||
introduction to the Humming Consensus algorithm. Its abstract:
|
||||
|
||||
> Machi is an immutable file store, now in active development by Basho
|
||||
> Japan KK. Machi uses Chain Replication to maintain strong consistency
|
||||
> of file updates to all replica servers in a Machi cluster. Chain
|
||||
> Replication is a variation of primary/backup replication where the
|
||||
> order of updates between the primary server and each of the backup
|
||||
> servers is strictly ordered into a single "chain". Management of
|
||||
> Chain Replication's metadata, e.g., "What is the current order of
|
||||
> servers in the chain?", remains an open research problem. The
|
||||
> current state of the art for Chain Replication metadata management
|
||||
> relies on an external oracle (e.g., ZooKeeper) or the Elastic
|
||||
> Replication algorithm.
|
||||
>
|
||||
> This document describes the Machi chain manager, the component
|
||||
> responsible for managing Chain Replication metadata state. The chain
|
||||
> manager uses a new technique, based on a variation of CORFU, called
|
||||
> "humming consensus".
|
||||
> Humming consensus does not require active participation by all or even
|
||||
> a majority of participants to make decisions. Machi's chain manager
|
||||
> bases its logic on humming consensus to make decisions about how to
|
||||
> react to changes in its environment, e.g. server crashes, network
|
||||
> partitions, and changes by Machi cluster admnistrators. Once a
|
||||
> decision is made during a virtual time epoch, humming consensus will
|
||||
> eventually discover if other participants have made a different
|
||||
> decision during that epoch. When a differing decision is discovered,
|
||||
> new time epochs are proposed in which a new consensus is reached and
|
||||
> disseminated to all available participants.
|
||||
|
||||
### chain-self-management-sketch.org
|
||||
|
||||
[chain-self-management-sketch.org](chain-self-management-sketch.org)
|
||||
is a mostly-deprecated draft of
|
||||
an introduction to the
|
||||
self-management algorithm proposed for Machi. Most material has been
|
||||
moved to the [high-level-chain-mgr.pdf](high-level-chain-mgr.pdf) document.
|
||||
|
||||
### cluster (directory)
|
||||
|
||||
This directory contains the sketch of the cluster design
|
||||
strawman for partitioning/distributing/sharding files across a large
|
||||
number of independent Machi chains.
|
||||
|
||||
|
|
@ -1,258 +0,0 @@
|
|||
|
||||
# Using basho_bench to twiddle with Machi
|
||||
|
||||
"Twiddle"? Really, is that a word? (Yes, it is a real English word.)
|
||||
|
||||
## Benchmarking Machi's performance ... no, don't do it.
|
||||
|
||||
Machi isn't ready for benchmark testing. Its public-facing API isn't
|
||||
finished yet. Its internal APIs aren't quite finished yet either. So
|
||||
any results of "benchmarking" effort is something that has even less
|
||||
value **N** months from now than the usual benchmarking effort.
|
||||
|
||||
However, there are uses for a benchmark tool. For example, one of my
|
||||
favorites is to put **stress** on a system. I don't care about
|
||||
average or 99th-percentile latencies, but I **might** care very much
|
||||
about behavior.
|
||||
|
||||
* What happens if a Machi system is under moderate load, and then I
|
||||
stop one of the servers? What happens?
|
||||
* How quickly do the chain managers react?
|
||||
* How quickly do the client libraries within Machi react?
|
||||
* How quickly do the external client API libraries react?
|
||||
|
||||
* What happens if a Machi system is under heavy load, for example,
|
||||
100% CPU load. Not all 100% might be the Machi services. Some CPU
|
||||
consumption might be from the load generator, like `basho_bench`
|
||||
itself that is running on the same machine as a Machi server. Or
|
||||
perhaps it's a tiny C program that I wrote:
|
||||
|
||||
main()
|
||||
{ while (1) { ; } }
|
||||
|
||||
## An example of how adding moderate stress can find weird bugs
|
||||
|
||||
The driver/plug-in module for `basho_bench` is only a few hours old.
|
||||
(I'm writing on Wednesday, 2015-05-20.) But just now, I configured my
|
||||
basho_bench config file to try to contact a Machi cluster of three
|
||||
nodes ... but really, only one was running. The client library,
|
||||
`machi_cr_client.erl`, has **an extremely simple** method for dealing
|
||||
with failed servers. I know it's simple and dumb, but that's OK in
|
||||
many cases.
|
||||
|
||||
However, `basho_bench` and the `machi_cr_client.erl` were acting very,
|
||||
very badly. I couldn't figure it out until I took a peek at my OS's
|
||||
`dmesg` output, namely: `dmesg | tail`. It said things like this:
|
||||
|
||||
Limiting closed port RST response from 690 to 50 packets per second
|
||||
Limiting closed port RST response from 367 to 50 packets per second
|
||||
Limiting closed port RST response from 101 to 50 packets per second
|
||||
Limiting closed port RST response from 682 to 50 packets per second
|
||||
Limiting closed port RST response from 467 to 50 packets per second
|
||||
|
||||
Well, isn't that interesting?
|
||||
|
||||
This system was running on a single OS X machine: my MacBook Pro
|
||||
laptop, running OS X 10.10 (Yosemite). I have seen that error
|
||||
before. And I know how to fix it.
|
||||
|
||||
* **Option 1**: Change the client library config to ignore the Machi
|
||||
servers that I know will always be down during my experiment.
|
||||
* ** Option 2**: Use the following to change my OS's TCP stack RST
|
||||
behavior. (If a TCP port is not being listened to, the OS will
|
||||
send a RST packet to signal "connection refused".)
|
||||
|
||||
On OS X, the limit for RST packets is 50/second. The
|
||||
`machi_cr_client.erl` client can generate far more than 50/second, as
|
||||
the `Limiting closed port RST response...` messages above show. So, I
|
||||
used some brute-force to change the environment:
|
||||
|
||||
sudo sysctl -w net.inet.icmp.icmplim=20000
|
||||
|
||||
... and the problem disappeared.
|
||||
|
||||
## Starting with basho_bench: a step-by-step tutorial
|
||||
|
||||
First, clone the `basho_bench` source code, then compile it. You will
|
||||
need Erlang/OTP version R16B or later to compile. I recommend using
|
||||
Erlang/OTP 17.x, because I've been doing my Machi development using
|
||||
17.x.
|
||||
|
||||
cd /some/nice/dev/place
|
||||
git clone https://github.com/basho/basho_bench.git
|
||||
cd basho_bench
|
||||
make
|
||||
|
||||
In order to create graphs of `basho_bench` output, you'll need
|
||||
installed one of the following:
|
||||
|
||||
* R (the statistics package)
|
||||
* gnuplot
|
||||
|
||||
If you don't have either available on the machine(s) you're testing,
|
||||
but you do have R (or gnuplot) on some other machine **Y**, then you can
|
||||
copy the output files to machine **Y** and generate the graphs there.
|
||||
|
||||
## Compiling the Machi source
|
||||
|
||||
First, clone the Machi source code, then compile it. You will
|
||||
need Erlang/OTP version 17.x to compile.
|
||||
|
||||
cd /some/nice/dev/place
|
||||
git clone https://github.com/basho/machi.git
|
||||
cd machi
|
||||
make
|
||||
|
||||
## Creating a basho_bench test configuration file.
|
||||
|
||||
There are a couple of example `basho_bench` configuration files in the
|
||||
Machi `priv` directory.
|
||||
|
||||
* [basho_bench.append-example.config](priv/basho_bench.append-example.config),
|
||||
an example for writing Machi files.
|
||||
* [basho_bench.read-example.config](priv/basho_bench.read-example.config),
|
||||
an example for reading Machi files.
|
||||
|
||||
If you want a test to do both reading & writing ... well, the
|
||||
driver/plug-in is not mature enough to do it **well**. If you really
|
||||
want to, refer to the `basho_bench` docs for how to use the
|
||||
`operations` config option.
|
||||
|
||||
The `basho_bench` config file is configured in Erlang term format.
|
||||
Each configuration item is a 2-tuple followed by a period. Comments
|
||||
begin with a `%` character and continue to the end-of-line.
|
||||
|
||||
%% Mandatory: adjust this code path to top of your compiled Machi source distro
|
||||
{code_paths, ["/Users/fritchie/b/src/machi"]}.
|
||||
{driver, machi_basho_bench_driver}.
|
||||
|
||||
%% Chose your maximum rate (per worker proc, see 'concurrent' below)
|
||||
{mode, {rate, 25}}.
|
||||
|
||||
%% Runtime & reporting interval
|
||||
{duration, 10}. % minutes
|
||||
{report_interval, 1}. % seconds
|
||||
|
||||
%% Choose your number of worker procs
|
||||
{concurrent, 5}.
|
||||
|
||||
%% Here's a chain of (up to) length 3, all on localhost
|
||||
{machi_server_info,
|
||||
[
|
||||
{p_srvr,a,machi_flu1_client,"localhost",4444,[]},
|
||||
{p_srvr,b,machi_flu1_client,"localhost",4445,[]},
|
||||
{p_srvr,c,machi_flu1_client,"localhost",4446,[]}
|
||||
]}.
|
||||
{machi_ets_key_tab_type, set}. % 'set' or 'ordered_set'
|
||||
|
||||
%% Workload-specific definitions follow....
|
||||
|
||||
%% 10 parts 'append' operation + 0 parts anything else = 100% 'append' ops
|
||||
{operations, [{append, 10}]}.
|
||||
|
||||
%% For append, key = Machi file prefix name
|
||||
{key_generator, {concat_binary, <<"prefix">>,
|
||||
{to_binstr, "~w", {uniform_int, 30}}}}.
|
||||
|
||||
%% Increase size of value_generator_source_size if value_generator is big!!
|
||||
{value_generator_source_size, 2111000}.
|
||||
{value_generator, {fixed_bin, 32768}}. % 32 KB
|
||||
|
||||
In summary:
|
||||
|
||||
* Yes, you really need to change `code_paths` to be the same as your
|
||||
`/some/nice/dev/place/basho_bench` directory ... and that directory
|
||||
must be on the same machine(s) that you intend to run `basho_bench`.
|
||||
* Each worker process will have a rate limit of 25 ops/sec.
|
||||
* The test will run for 10 minutes and report stats every 1 second.
|
||||
* There are 5 concurrent worker processes. Each worker will
|
||||
concurrently issue commands from the `operations` list, within the
|
||||
workload throttle limit.
|
||||
* The Machi cluster is a collection of three servers, all on
|
||||
"localhost", and using TCP ports 4444-4446.
|
||||
* Don't change the `machi_ets_key_tab_type`
|
||||
* Our workload operation mix is 100% `append` operations.
|
||||
* The key generator for the `append` operation specifies the file
|
||||
prefix that will be chosen (at pseudo-random). In this case, we'll
|
||||
choose uniformly randomly between file prefix `prefix0` and
|
||||
`prefix29`.
|
||||
* The values that we append will be fixed 32KB length, but they will
|
||||
be chosen from a random byte string of 2,111,000 bytes.
|
||||
|
||||
There are many other options for `basho_bench`, especially for the
|
||||
`key_generator` and `value_generator` options. Please see the
|
||||
`basho_bench` docs for further information.
|
||||
|
||||
## Running basho_bench
|
||||
|
||||
You can run `basho_bench` using the command:
|
||||
|
||||
/some/nice/dev/place/basho_bench/basho_bench /path/to/config/file
|
||||
|
||||
... where `/path/to/config/file` is the path to your config file. (If
|
||||
you use an example from the `priv` dir, we recommend that you make a
|
||||
copy elsewhere, edit the copy, and then use the copy to run
|
||||
`basho_bench`.)
|
||||
|
||||
You'll create a stats output directory, called `tests`, in the current
|
||||
working directory. (Add `{results_dir, "/some/output/dir"}.` to change
|
||||
the default!)
|
||||
|
||||
Each time `basho_bench` is run, a new output stats directory is
|
||||
created in the `tests` directory. The symbolic link `tests/current`
|
||||
will always point to the last `basho_bench` run's output. But all
|
||||
prior results are always accessible! Take a look in this directory
|
||||
for all of the output.
|
||||
|
||||
## Generating some pretty graphs
|
||||
|
||||
If you are using R, then the following command will create a graph:
|
||||
|
||||
Rscript --vanilla /some/nice/dev/place/basho_bench/basho_bench/priv/summary.r -i $CWD/tests/current
|
||||
|
||||
If the `tests` directory is not in your current working dir (i.e. not
|
||||
in `$CWD`), then please alter the command accordingly.
|
||||
|
||||
R will create the final results graph in `$CWD/tests/current/summary.png`.
|
||||
|
||||
If you are using gnuplot, please look at
|
||||
`/some/nice/dev/place/basho_bench/basho_bench/Makefile` to see how to
|
||||
use gnuplot to create the final results graph.
|
||||
|
||||
## An example graph
|
||||
|
||||
So, without a lot of context about the **Machi system** or about the
|
||||
**basho_bench system** or about the ops being performed, here is an
|
||||
example graph that was created by R:
|
||||
|
||||
|
||||
|
||||
**Without context??* How do I remember the context?
|
||||
|
||||
My recommendation is: always keep the `.config` file together with the
|
||||
graph file. In the `tests` directory, `basho_bench` will always make
|
||||
a copy of the config file used to generate the test data.
|
||||
|
||||
This config tells you very little about the environment of the load
|
||||
generator machine or the Machi cluster, but ... you need to maintain
|
||||
that documentation yourself, please! You'll thank me for that advice,
|
||||
someday, 11 months from now when you can't remember the details of
|
||||
that important test that you ran so very long ago.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Really, we don't recommend using `basho_bench` for any serious
|
||||
performance measurement of Machi yet: Machi needs more maturity before
|
||||
it's reasonable to measure & judge its performance. But stress
|
||||
testing is indeed useful for reasons other than measuring
|
||||
Nth-percentile latency of operation `flarfbnitz`. We hope that this
|
||||
tutorial has been helpful!
|
||||
|
||||
If you encounter any difficulty with this tutorial or with Machi,
|
||||
please open an issue/ticket at [GH Issues for
|
||||
Machi](https://github.com/basho/machi/issues) ... use the green "New
|
||||
issue" button. There are bugs and misfeatures in the `basho_bench`
|
||||
plugin, sorry, but please help us fix them.
|
||||
|
||||
> -Scott Lystig Fritchie,
|
||||
> Machi Team @ Basho
|
||||
|
|
@ -4,11 +4,21 @@
|
|||
#+STARTUP: lognotedone hidestars indent showall inlineimages
|
||||
#+SEQ_TODO: TODO WORKING WAITING DONE
|
||||
|
||||
* 1. Abstract
|
||||
The high level design of the Machi "chain manager" has moved to the
|
||||
[[high-level-chain-manager.pdf][Machi chain manager high level design]] document.
|
||||
* Abstract
|
||||
Yo, this is the first draft of a document that attempts to describe a
|
||||
proposed self-management algorithm for Machi's chain replication.
|
||||
Welcome! Sit back and enjoy the disjointed prose.
|
||||
|
||||
We try to discuss the network partition simulator that the
|
||||
We attempt to describe first the self-management and self-reliance
|
||||
goals of the algorithm. Then we make a side trip to talk about
|
||||
write-once registers and how they're used by Machi, but we don't
|
||||
really fully explain exactly why write-once is so critical (why not
|
||||
general purpose registers?) ... but they are indeed critical. Then we
|
||||
sketch the algorithm by providing detailed annotation of a flowchart,
|
||||
then let the flowchart speak for itself, because writing good prose is
|
||||
prose is damn hard, but flowcharts are very specific and concise.
|
||||
|
||||
Finally, we try to discuss the network partition simulator that the
|
||||
algorithm runs in and how the algorithm behaves in both symmetric and
|
||||
asymmetric network partition scenarios. The symmetric partition cases
|
||||
are all working well (surprising in a good way), and the asymmetric
|
||||
|
|
@ -16,9 +26,7 @@ partition cases are working well (in a damn mystifying kind of way).
|
|||
It'd be really, *really* great to get more review of the algorithm and
|
||||
the simulator.
|
||||
|
||||
* 2. Copyright
|
||||
|
||||
#+BEGIN_SRC
|
||||
* Copyright
|
||||
%% Copyright (c) 2015 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -34,38 +42,442 @@ the simulator.
|
|||
%% KIND, either express or implied. See the License for the
|
||||
%% specific language governing permissions and limitations
|
||||
%% under the License.
|
||||
|
||||
* TODO Naming: possible ideas
|
||||
** Humming consensus?
|
||||
|
||||
See [[https://tools.ietf.org/html/rfc7282][On Consensus and Humming in the IETF]], RFC 7282.
|
||||
|
||||
** Tunesmith?
|
||||
|
||||
A mix of orchestral conducting, music composition, humming?
|
||||
|
||||
** Foggy consensus?
|
||||
|
||||
CORFU-like consensus between mist-shrouded islands of network
|
||||
partitions
|
||||
|
||||
** Rough consensus
|
||||
|
||||
This is my favorite, but it might be too close to handwavy/vagueness
|
||||
of English language, even with a precise definition and proof
|
||||
sketching?
|
||||
|
||||
** Let the bikeshed continue!
|
||||
|
||||
I agree with Chris: there may already be a definition that's close
|
||||
enough to "rough consensus" to continue using that existing tag than
|
||||
to invent a new one. TODO: more research required
|
||||
|
||||
* What does "self-management" mean in this context?
|
||||
|
||||
For the purposes of this document, chain replication self-management
|
||||
is the ability for the N nodes in an N-length chain replication chain
|
||||
to manage the state of the chain without requiring an external party
|
||||
to participate. Chain state includes:
|
||||
|
||||
1. Preserve data integrity of all data stored within the chain. Data
|
||||
loss is not an option.
|
||||
2. Stably preserve knowledge of chain membership (i.e. all nodes in
|
||||
the chain, regardless of operational status). A systems
|
||||
administrators is expected to make "permanent" decisions about
|
||||
chain membership.
|
||||
3. Use passive and/or active techniques to track operational
|
||||
state/status, e.g., up, down, restarting, full data sync, partial
|
||||
data sync, etc.
|
||||
4. Choose the run-time replica ordering/state of the chain, based on
|
||||
current member status and past operational history. All chain
|
||||
state transitions must be done safely and without data loss or
|
||||
corruption.
|
||||
5. As a new node is added to the chain administratively or old node is
|
||||
restarted, add the node to the chain safely and perform any data
|
||||
synchronization/"repair" required to bring the node's data into
|
||||
full synchronization with the other nodes.
|
||||
|
||||
* Goals
|
||||
** Better than state-of-the-art: Chain Replication self-management
|
||||
|
||||
We hope/believe that this new self-management algorithem can improve
|
||||
the current state-of-the-art by eliminating all external management
|
||||
entities. Current state-of-the-art for management of chain
|
||||
replication chains is discussed below, to provide historical context.
|
||||
|
||||
*** "Leveraging Sharding in the Design of Scalable Replication Protocols" by Abu-Libdeh, van Renesse, and Vigfusson.
|
||||
|
||||
Multiple chains are arranged in a ring (called a "band" in the paper).
|
||||
The responsibility for managing the chain at position N is delegated
|
||||
to chain N-1. As long as at least one chain is running, that is
|
||||
sufficient to start/bootstrap the next chain, and so on until all
|
||||
chains are running. (The paper then estimates mean-time-to-failure
|
||||
(MTTF) and suggests a "band of bands" topology to handle very large
|
||||
clusters while maintaining an MTTF that is as good or better than
|
||||
other management techniques.)
|
||||
|
||||
If the chain self-management method proposed for Machi does not
|
||||
succeed, this paper's technique is our best fallback recommendation.
|
||||
|
||||
*** An external management oracle, implemented by ZooKeeper
|
||||
|
||||
This is not a recommendation for Machi: we wish to avoid using ZooKeeper.
|
||||
However, many other open and closed source software products use
|
||||
ZooKeeper for exactly this kind of data replica management problem.
|
||||
|
||||
*** An external management oracle, implemented by Riak Ensemble
|
||||
|
||||
This is a much more palatable choice than option #2 above. We also
|
||||
wish to avoid an external dependency on something as big as Riak
|
||||
Ensemble. However, if it comes between choosing Riak Ensemble or
|
||||
choosing ZooKeeper, the choice feels quite clear: Riak Ensemble will
|
||||
win, unless there is some critical feature missing from Riak
|
||||
Ensemble. If such an unforseen missing feature is discovered, it
|
||||
would probably be preferable to add the feature to Riak Ensemble
|
||||
rather than to use ZooKeeper (and document it and provide product
|
||||
support for it and so on...).
|
||||
|
||||
** Support both eventually consistent & strongly consistent modes of operation
|
||||
|
||||
Machi's first use case is for Riak CS, as an eventually consistent
|
||||
store for CS's "block" storage. Today, Riak KV is used for "block"
|
||||
storage. Riak KV is an AP-style key-value store; using Machi in an
|
||||
AP-style mode would match CS's current behavior from points of view of
|
||||
both code/execution and human administrator exectations.
|
||||
|
||||
Later, we wish the option of using CP support to replace other data
|
||||
store services that Riak KV provides today. (Scope and timing of such
|
||||
replacement TBD.)
|
||||
|
||||
We believe this algorithm allows a Machi cluster to fragment into
|
||||
arbitrary islands of network partition, all the way down to 100% of
|
||||
members running in complete network isolation from each other.
|
||||
Furthermore, it provides enough agreement to allow
|
||||
formerly-partitioned members to coordinate the reintegration &
|
||||
reconciliation of their data when partitions are healed.
|
||||
|
||||
** Preserve data integrity of Chain Replicated data
|
||||
|
||||
While listed last in this section, preservation of data integrity is
|
||||
paramount to any chain state management technique for Machi.
|
||||
|
||||
** Anti-goal: minimize churn
|
||||
|
||||
This algorithm's focus is data safety and not availability. If
|
||||
participants have differing notions of time, e.g., running on
|
||||
extremely fast or extremely slow hardware, then this algorithm will
|
||||
"churn" in different states where the chain's data would be
|
||||
effectively unavailable.
|
||||
|
||||
In practice, however, any series of network partition changes that
|
||||
case this algorithm to churn will cause other management techniques
|
||||
(such as an external "oracle") similar problems. [Proof by handwaving
|
||||
assertion.] See also: "time model" assumptions (below).
|
||||
|
||||
* Assumptions
|
||||
** Introduction to assumptions, why they differ from other consensus algorithms
|
||||
|
||||
Given a long history of consensus algorithms (viewstamped replication,
|
||||
Paxos, Raft, et al.), why bother with a slightly different set of
|
||||
assumptions and a slightly different protocol?
|
||||
|
||||
The answer lies in one of our explicit goals: to have an option of
|
||||
running in an "eventually consistent" manner. We wish to be able to
|
||||
make progress, i.e., remain available in the CAP sense, even if we are
|
||||
partitioned down to a single isolated node. VR, Paxos, and Raft
|
||||
alone are not sufficient to coordinate service availability at such
|
||||
small scale.
|
||||
|
||||
** The CORFU protocol is correct
|
||||
|
||||
This work relies tremendously on the correctness of the CORFU
|
||||
protocol, a cousin of the Paxos protocol. If the implementation of
|
||||
this self-management protocol breaks an assumption or prerequisite of
|
||||
CORFU, then we expect that the implementation will be flawed.
|
||||
|
||||
** Communication model: Asyncronous message passing
|
||||
*** Unreliable network: messages may be arbitrarily dropped and/or reordered
|
||||
**** Network partitions may occur at any time
|
||||
**** Network partitions may be asymmetric: msg A->B is ok but B->A fails
|
||||
*** Messages may be corrupted in-transit
|
||||
**** Assume that message MAC/checksums are sufficient to detect corruption
|
||||
**** Receiver informs sender of message corruption
|
||||
**** Sender may resend, if/when desired
|
||||
*** System particpants may be buggy but not actively malicious/Byzantine
|
||||
** Time model: per-node clocks, loosely synchronized (e.g. NTP)
|
||||
|
||||
The protocol & algorithm presented here do not specify or require any
|
||||
timestamps, physical or logical. Any mention of time inside of data
|
||||
structures are for human/historic/diagnostic purposes only.
|
||||
|
||||
Having said that, some notion of physical time is suggested for
|
||||
purposes of efficiency. It's recommended that there be some "sleep
|
||||
time" between iterations of the algorithm: there is no need to "busy
|
||||
wait" by executing the algorithm as quickly as possible. See below,
|
||||
"sleep intervals between executions".
|
||||
|
||||
** Failure detector model: weak, fallible, boolean
|
||||
|
||||
We assume that the failure detector that the algorithm uses is weak,
|
||||
it's fallible, and it informs the algorithm in boolean status
|
||||
updates/toggles as a node becomes available or not.
|
||||
|
||||
If the failure detector is fallible and tells us a mistaken status
|
||||
change, then the algorithm will "churn" the operational state of the
|
||||
chain, e.g. by removing the failed node from the chain or adding a
|
||||
(re)started node (that may not be alive) to the end of the chain.
|
||||
Such extra churn is regrettable and will cause periods of delay as the
|
||||
"rough consensus" (decribed below) decision is made. However, the
|
||||
churn cannot (we assert/believe) cause data loss.
|
||||
|
||||
** The "wedge state", as described by the Machi RFC & CORFU
|
||||
|
||||
A chain member enters "wedge state" when it receives information that
|
||||
a newer projection (i.e., run-time chain state reconfiguration) is
|
||||
available. The new projection may be created by a system
|
||||
administrator or calculated by the self-management algorithm.
|
||||
Notification may arrive via the projection store API or via the file
|
||||
I/O API.
|
||||
|
||||
When in wedge state, the server/FLU will refuse all file write I/O API
|
||||
requests until the self-management algorithm has determined that
|
||||
"rough consensus" has been decided (see next bullet item). The server
|
||||
may also refuse file read I/O API requests, depending on its CP/AP
|
||||
operation mode.
|
||||
|
||||
See the Machi RFC for more detail of the wedge state and also the
|
||||
CORFU papers.
|
||||
|
||||
** "Rough consensus": consensus built upon data that is *visible now*
|
||||
|
||||
CS literature uses the word "consensus" in the context of the problem
|
||||
description at
|
||||
[[http://en.wikipedia.org/wiki/Consensus_(computer_science)#Problem_description]].
|
||||
This traditional definition differs from what is described in this
|
||||
document.
|
||||
|
||||
The phrase "rough consensus" will be used to describe
|
||||
consensus derived only from data that is visible/known at the current
|
||||
time. This implies that a network partition may be in effect and that
|
||||
not all chain members are reachable. The algorithm will calculate
|
||||
"rough consensus" despite not having input from all/majority/minority
|
||||
of chain members. "Rough consensus" may proceed to make a
|
||||
decision based on data from only a single participant, i.e., the local
|
||||
node alone.
|
||||
|
||||
When operating in AP mode, i.e., in eventual consistency mode, "rough
|
||||
consensus" could mean that an chain of length N could split into N
|
||||
independent chains of length 1. When a network partition heals, the
|
||||
rough consensus is sufficient to manage the chain so that each
|
||||
replica's data can be repaired/merged/reconciled safely.
|
||||
(Other features of the Machi system are designed to assist such
|
||||
repair safely.)
|
||||
|
||||
When operating in CP mode, i.e., in strong consistency mode, "rough
|
||||
consensus" would require additional supplements. For example, any
|
||||
chain that didn't have a minimum length of the quorum majority size of
|
||||
all members would be invalid and therefore would not move itself out
|
||||
of wedged state. In very general terms, this requirement for a quorum
|
||||
majority of surviving participants is also a requirement for Paxos,
|
||||
Raft, and ZAB.
|
||||
|
||||
(Aside: The Machi RFC also proposes using "witness" chain members to
|
||||
make service more available, e.g. quorum majority of "real" plus
|
||||
"witness" nodes *and* at least one member must be a "real" node. See
|
||||
the Machi RFC for more details.)
|
||||
|
||||
** Heavy reliance on a key-value store that maps write-once registers
|
||||
|
||||
The projection store is implemented using "write-once registers"
|
||||
inside a key-value store: for every key in the store, the value must
|
||||
be either of:
|
||||
|
||||
- The special 'unwritten' value
|
||||
- An application-specific binary blob that is immutable thereafter
|
||||
|
||||
* The projection store, built with write-once registers
|
||||
|
||||
- NOTE to the reader: The notion of "public" vs. "private" projection
|
||||
stores does not appear in the Machi RFC.
|
||||
|
||||
Each participating chain node has its own "projection store", which is
|
||||
a specialized key-value store. As a whole, a node's projection store
|
||||
is implemented using two different key-value stores:
|
||||
|
||||
- A publicly-writable KV store of write-once registers
|
||||
- A privately-writable KV store of write-once registers
|
||||
|
||||
Both stores may be read by any cluster member.
|
||||
|
||||
The store's key is a positive integer; the integer represents the
|
||||
epoch number of the projection. The store's value is an opaque
|
||||
binary blob whose meaning is meaningful only to the store's clients.
|
||||
|
||||
See the Machi RFC for more detail on projections and epoch numbers.
|
||||
|
||||
** The publicly-writable half of the projection store
|
||||
|
||||
The publicly-writable projection store is used to share information
|
||||
during the first half of the self-management algorithm. Any chain
|
||||
member may write a projection to this store.
|
||||
|
||||
** The privately-writable half of the projection store
|
||||
|
||||
The privately-writable projection store is used to store the "rough
|
||||
consensus" result that has been calculated by the local node. Only
|
||||
the local server/FLU may write values into this store.
|
||||
|
||||
The private projection store serves multiple purposes, including:
|
||||
|
||||
- remove/clear the local server from "wedge state"
|
||||
- act as the store of record for chain state transitions
|
||||
- communicate to remote nodes the past states and current operational
|
||||
state of the local node
|
||||
|
||||
* Modification of CORFU-style epoch numbering and "wedge state" triggers
|
||||
|
||||
According to the CORFU research papers, if a server node N or client
|
||||
node C believes that epoch E is the latest epoch, then any information
|
||||
that N or C receives from any source that an epoch E+delta (where
|
||||
delta > 0) exists will push N into the "wedge" state and C into a mode
|
||||
of searching for the projection definition for the newest epoch.
|
||||
|
||||
In the algorithm sketch below, it should become clear that it's
|
||||
possible to have a race where two nodes may attempt to make proposals
|
||||
for a single epoch number. In the simplest case, assume a chain of
|
||||
nodes A & B. Assume that a symmetric network partition between A & B
|
||||
happens, and assume we're operating in AP/eventually consistent mode.
|
||||
|
||||
On A's network partitioned island, A can choose a UPI list of `[A]'.
|
||||
Similarly B can choose a UPI list of `[B]'. Both might choose the
|
||||
epoch for their proposal to be #42. Because each are separated by
|
||||
network partition, neither can realize the conflict. However, when
|
||||
the network partition heals, it can become obvious that there are
|
||||
conflicting values for epoch #42 ... but if we use CORFU's protocol
|
||||
design, which identifies the epoch identifier as an integer only, then
|
||||
the integer 42 alone is not sufficient to discern the differences
|
||||
between the two projections.
|
||||
|
||||
The proposal modifies all use of CORFU's projection identifier
|
||||
to use the identifier below instead. (A later section of this
|
||||
document presents a detailed example.)
|
||||
|
||||
#+BEGIN_SRC
|
||||
{epoch #, hash of the entire projection (minus hash field itself)}
|
||||
#+END_SRC
|
||||
|
||||
* Sketch of the self-management algorithm
|
||||
** Introduction
|
||||
See also, the diagram (((Diagram1.eps))), a flowchart of the
|
||||
algorithm. The code is structured as a state machine where function
|
||||
executing for the flowchart's state is named by the approximate
|
||||
location of the state within the flowchart. The flowchart has three
|
||||
columns:
|
||||
|
||||
* 3. Document restructuring
|
||||
1. Column A: Any reason to change?
|
||||
2. Column B: Do I act?
|
||||
3. Column C: How do I act?
|
||||
|
||||
Much of the text previously appearing in this document has moved to the
|
||||
[[high-level-chain-manager.pdf][Machi chain manager high level design]] document.
|
||||
States in each column are numbered in increasing order, top-to-bottom.
|
||||
|
||||
* 4. Diagram of the self-management algorithm
|
||||
** Flowchart notation
|
||||
- Author: a function that returns the author of a projection, i.e.,
|
||||
the node name of the server that proposed the projection.
|
||||
|
||||
** WARNING: This section is now deprecated
|
||||
- Rank: assigns a numeric score to a projection. Rank is based on the
|
||||
epoch number (higher wins), chain length (larger wins), number &
|
||||
state of any repairing members of the chain (larger wins), and node
|
||||
name of the author server (as a tie-breaking criteria).
|
||||
|
||||
The definitive text for this section has moved to the [[high-level-chain-manager.pdf][Machi chain
|
||||
manager high level design]] document.
|
||||
- E: the epoch number of a projection.
|
||||
|
||||
- UPI: "Update Propagation Invariant". The UPI part of the projection
|
||||
is the ordered list of chain members where the UPI is preserved,
|
||||
i.e., all UPI list members have their data fully synchronized
|
||||
(except for updates in-process at the current instant in time).
|
||||
|
||||
- Repairing: the ordered list of nodes that are in "repair mode",
|
||||
i.e., synchronizing their data with the UPI members of the chain.
|
||||
|
||||
- Down: the list of chain members believed to be down, from the
|
||||
perspective of the author. This list may be constructed from
|
||||
information from the failure detector and/or by status of recent
|
||||
attempts to read/write to other nodes' public projection store(s).
|
||||
|
||||
- P_current: local node's projection that is actively used. By
|
||||
definition, P_current is the latest projection (i.e. with largest
|
||||
epoch #) in the local node's private projection store.
|
||||
|
||||
- P_newprop: the new projection proposal that is calculated locally,
|
||||
based on local failure detector info & other data (e.g.,
|
||||
success/failure status when reading from/writing to remote nodes'
|
||||
projection stores).
|
||||
|
||||
- P_latest: this is the highest-ranked projection with the largest
|
||||
single epoch # that has been read from all available public
|
||||
projection stores, including the local node's public store.
|
||||
|
||||
- Unanimous: The P_latest projections are unanimous if they are
|
||||
effectively identical. Minor differences such as creation time may
|
||||
be ignored, but elements such as the UPI list must not be ignored.
|
||||
NOTE: "unanimous" has nothing to do with the number of projections
|
||||
compared, "unanimous" is *not* the same as a "quorum majority".
|
||||
|
||||
- P_current -> P_latest transition safe?: A predicate function to
|
||||
check the sanity & safety of the transition from the local node's
|
||||
P_current to the P_newprop, which must be unanimous at state C100.
|
||||
|
||||
- Stop state: one iteration of the self-management algorithm has
|
||||
finished on the local node. The local node may execute a new
|
||||
iteration at any time.
|
||||
|
||||
** Column A: Any reason to change?
|
||||
*** A10: Set retry counter to 0
|
||||
*** A20: Create a new proposed projection based on the current projection
|
||||
*** A30: Read copies of the latest/largest epoch # from all nodes
|
||||
*** A40: Decide if the local proposal P_newprop is "better" than P_latest
|
||||
** Column B: Do I act?
|
||||
*** B10: 1. Is the latest proposal unanimous for the largest epoch #?
|
||||
*** B10: 2. Is the retry counter too big?
|
||||
*** B10: 3. Is another node's proposal "ranked" equal or higher to mine?
|
||||
** Column C: How to act?
|
||||
*** C1xx: Save latest proposal to local private store, unwedge, stop.
|
||||
*** C2xx: Ping author of latest to try again, then wait, then repeat alg.
|
||||
*** C3xx: My new proposal appears best: write @ all public stores, repeat alg
|
||||
|
||||
** Flowchart notes
|
||||
|
||||
*** Algorithm execution rates / sleep intervals between executions
|
||||
|
||||
Due to the ranking algorithm's preference for author node names that
|
||||
are large (lexicographically), nodes with larger node names should
|
||||
are small (lexicographically), nodes with smaller node names should
|
||||
execute the algorithm more frequently than other nodes. The reason
|
||||
for this is to try to avoid churn: a proposal by a "small" node may
|
||||
propose a UPI list of L at epoch 10, and a few moments later a "big"
|
||||
for this is to try to avoid churn: a proposal by a "big" node may
|
||||
propose a UPI list of L at epoch 10, and a few moments later a "small"
|
||||
node may propose the same UPI list L at epoch 11. In this case, there
|
||||
would be two chain state transitions: the epoch 11 projection would be
|
||||
ranked higher than epoch 10's projection. If the "big" node
|
||||
executed more frequently than the "small" node, then it's more likely
|
||||
that epoch 10 would be written by the "big" node, which would then
|
||||
cause the "small" node to stop at state A40 and avoid any
|
||||
ranked higher than epoch 10's projeciton. If the "small" node
|
||||
executed more frequently than the "big" node, then it's more likely
|
||||
that epoch 10 would be written by the "small" node, which would then
|
||||
cause the "big" node to stop at state A40 and avoid any
|
||||
externally-visible action.
|
||||
|
||||
*** Transition safety checking
|
||||
|
||||
In state C100, the transition from P_current -> P_latest is checked
|
||||
for safety and sanity. The conditions used for the check include:
|
||||
|
||||
1. The Erlang data types of all record members are correct.
|
||||
2. UPI, down, & repairing lists contain no duplicates and are in fact
|
||||
mutually disjoint.
|
||||
3. The author node is not down (as far as we can tell).
|
||||
4. Any additions in P_latest in the UPI list must appear in the tail
|
||||
of the UPI list and were formerly in P_current's repairing list.
|
||||
5. No re-ordering of the UPI list members: P_latest's UPI list prefix
|
||||
must be exactly equal to P_current's UPI prefix, and any P_latest's
|
||||
UPI list suffix must in the same order as they appeared in
|
||||
P_current's repairing list.
|
||||
|
||||
The safety check may be performed pair-wise once or pair-wise across
|
||||
the entire history sequence of a server/FLU's private projection
|
||||
store.
|
||||
|
||||
*** A simple example race between two participants noting a 3rd's failure
|
||||
|
||||
Assume a chain of three nodes, A, B, and C. In a projection at epoch
|
||||
|
|
@ -145,7 +557,7 @@ look like this:
|
|||
| E+2 | UPI=[A,B] | UPI=[A,B] | UPI=[C] |
|
||||
| | Repairing=[] | Repairing=[] | Repairing=[] |
|
||||
| | Down=[C] | Down=[C] | Down=[A,B] |
|
||||
| | Author=A | Author=A | Author=C |
|
||||
| | Author=A | Author=A | |
|
||||
|-----+--------------+--------------+--------------|
|
||||
|
||||
Now we're in a pickle where a client C could read the latest
|
||||
|
|
@ -164,7 +576,7 @@ use of quorum majority for UPI members is out of scope of this
|
|||
document. Also out of scope is the use of "witness servers" to
|
||||
augment the quorum majority UPI scheme.)
|
||||
|
||||
* 5. The Network Partition Simulator
|
||||
* The Simulator
|
||||
** Overview
|
||||
The function machi_chain_manager1_test:convergence_demo_test()
|
||||
executes the following in a simulated network environment within a
|
||||
|
|
@ -210,42 +622,51 @@ self-management algorithm and verify its correctness.
|
|||
|
||||
** Behavior in asymmetric network partitions
|
||||
|
||||
Text has moved to the [[high-level-chain-manager.pdf][Machi chain manager high level design]] document.
|
||||
The simulator's behavior during stable periods where at least one node
|
||||
is the victim of an asymmetric network partition is ... weird,
|
||||
wonderful, and something I don't completely understand yet. This is
|
||||
another place where we need more eyes reviewing and trying to poke
|
||||
holes in the algorithm.
|
||||
|
||||
* Prototype notes
|
||||
In cases where any node is a victim of an asymmetric network
|
||||
partition, the algorithm oscillates in a very predictable way: each
|
||||
node X makes the same P_newprop projection at epoch E that X made
|
||||
during a previous recent epoch E-delta (where delta is small, usually
|
||||
much less than 10). However, at least one node makes a proposal that
|
||||
makes unanimous results impossible. When any epoch E is not
|
||||
unanimous, the result is one or more new rounds of proposals.
|
||||
However, because any node N's proposal doesn't change, the system
|
||||
spirals into an infinite loop of never-fully-unanimous proposals.
|
||||
|
||||
** Mid-April 2015
|
||||
From the sole perspective of any single participant node, the pattern
|
||||
of this infinite loop is easy to detect. When detected, the local
|
||||
node moves to a slightly different mode of operation: it starts
|
||||
suspecting that a "proposal flapping" series of events is happening.
|
||||
(The name "flap" is taken from IP network routing, where a "flapping
|
||||
route" is an oscillating state of churn within the routing fabric
|
||||
where one or more routes change, usually in a rapid & very disruptive
|
||||
manner.)
|
||||
|
||||
I've finished moving the chain manager plus the inner/nested
|
||||
projection code into the top-level 'src' dir of this repo. The idea
|
||||
is working very well under simulation, more than well enough to gamble
|
||||
on for initial use.
|
||||
If flapping is suspected, then the count of number of flap cycles is
|
||||
counted. If the local node sees all participants (including itself)
|
||||
flappign with the same relative proposed projection for 5 times in a
|
||||
row, then the local node has firm evidence that there is an asymmetric
|
||||
network partition somewhere in the system. The pattern of proposals
|
||||
is analyzed, and the local node makes a decision:
|
||||
|
||||
Stronger validation work will continue through 2015, ideally using a
|
||||
tool like TLA+.
|
||||
1. The local node is directly affected by the network partition. The
|
||||
result: stop making new projection proposals until the failure
|
||||
detector belives that a new status change has taken place.
|
||||
|
||||
** Mid-March 2015
|
||||
2. The local node is not directly affected by the network partition.
|
||||
The result: continue participating in the system by continuing new
|
||||
self-management algorithm iterations.
|
||||
|
||||
I've come to realize that the property that causes the nice property
|
||||
of "Were my last 2L proposals identical?" also requires that the
|
||||
proposals be *stable*. If a participant notices, "Hey, there's
|
||||
flapping happening, so I'll propose a different projection
|
||||
P_different", then the very act of proposing P_different disrupts the
|
||||
"last 2L proposals identical" cycle the enables us to detect
|
||||
flapping. We kill the goose that's laying our golden egg.
|
||||
After the asymmetric partition victims have "taken themselves out of
|
||||
the game" temporarily, then the remaining participants rapidly
|
||||
converge to rough consensus and then a visibly unanimous proposal.
|
||||
For as long as the network remains partitioned but stable, any new
|
||||
iteration of the self-management algorithm stops without
|
||||
externally-visible effects. (I.e., it stops at the bottom of the
|
||||
flowchart's Column A.)
|
||||
|
||||
I've been working on the idea of "nested" projections, namely an
|
||||
"outer" and "inner" projection. Only the "outer projection" is used
|
||||
for cycle detection. The "inner projection" is the same as the outer
|
||||
projection when flapping is not detected. When flapping is detected,
|
||||
then the inner projection is one that excludes all nodes that the
|
||||
outer projection has identified as victims of asymmetric partition.
|
||||
|
||||
This inner projection technique may or may not work well enough to
|
||||
use? It would require constant flapping of the outer proposal, which
|
||||
is going to consume CPU and also chew up projection store keys with
|
||||
the flapping churn. That churn would continue as long as an
|
||||
asymmetric partition exists. The simplest way to cope with this would
|
||||
be to reduce proposal rates significantly, say 10x or 50x slower, to
|
||||
slow churn down to proposals from several-per-second to perhaps
|
||||
several-per-minute?
|
||||
|
|
|
|||
|
|
@ -1,103 +0,0 @@
|
|||
#FIG 3.2 Produced by xfig version 3.2.5b
|
||||
Landscape
|
||||
Center
|
||||
Inches
|
||||
Letter
|
||||
94.00
|
||||
Single
|
||||
-2
|
||||
1200 2
|
||||
6 7425 2700 8700 3300
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 645 7425 2895 After\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 255 1215 7425 3210 Migration\001
|
||||
-6
|
||||
6 7425 450 8700 1050
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 780 7425 675 Before\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 255 1215 7425 990 Migration\001
|
||||
-6
|
||||
6 75 1425 6900 2325
|
||||
6 4875 1425 6900 2325
|
||||
6 5400 1575 6375 2175
|
||||
4 0 0 50 -1 2 14 0.0000 4 165 390 5400 1800 Not\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 225 945 5400 2100 migrated\001
|
||||
-6
|
||||
2 2 1 2 0 7 50 -1 -1 6.000 0 0 -1 0 0 5
|
||||
4950 1500 6825 1500 6825 2250 4950 2250 4950 1500
|
||||
-6
|
||||
6 2475 1425 4500 2325
|
||||
6 3000 1575 3975 2175
|
||||
4 0 0 50 -1 2 14 0.0000 4 165 390 3000 1800 Not\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 225 945 3000 2100 migrated\001
|
||||
-6
|
||||
2 2 1 2 0 7 50 -1 -1 6.000 0 0 -1 0 0 5
|
||||
2550 1500 4425 1500 4425 2250 2550 2250 2550 1500
|
||||
-6
|
||||
6 75 1425 2100 2325
|
||||
6 600 1575 1575 2175
|
||||
4 0 0 50 -1 2 14 0.0000 4 165 390 600 1800 Not\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 225 945 600 2100 migrated\001
|
||||
-6
|
||||
2 2 1 2 0 7 50 -1 -1 6.000 0 0 -1 0 0 5
|
||||
150 1500 2025 1500 2025 2250 150 2250 150 1500
|
||||
-6
|
||||
-6
|
||||
2 1 0 2 0 7 50 -1 -1 6.000 0 0 -1 1 0 2
|
||||
1 1 3.00 60.00 120.00
|
||||
150 4200 150 3750
|
||||
2 1 0 2 0 7 50 -1 -1 6.000 0 0 -1 1 0 2
|
||||
1 1 3.00 60.00 120.00
|
||||
3750 4200 3750 3750
|
||||
2 1 0 2 0 7 50 -1 -1 6.000 0 0 -1 1 0 2
|
||||
1 1 3.00 60.00 120.00
|
||||
2025 4200 2025 3750
|
||||
2 1 0 2 0 7 50 -1 -1 6.000 0 0 -1 1 0 2
|
||||
1 1 3.00 60.00 120.00
|
||||
7350 4200 7350 3750
|
||||
2 1 0 2 0 7 50 -1 -1 6.000 0 0 -1 1 0 2
|
||||
1 1 3.00 60.00 120.00
|
||||
5550 4200 5550 3750
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
2550 0 2550 1500 150 1500 150 0 2550 0
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
4950 0 4950 1500 2550 1500 2550 0 4950 0
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
7350 0 7350 1500 4950 1500 4950 0 7350 0
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
150 2250 2025 2250 2025 3750 150 3750 150 2250
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
4425 2250 4950 2250 4950 3750 4425 3750 4425 2250
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
4950 2250 6825 2250 6825 3750 4950 3750 4950 2250
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
6825 2250 7350 2250 7350 3750 6825 3750 6825 2250
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
2025 2250 2550 2250 2550 3750 2025 3750 2025 2250
|
||||
2 2 0 3 0 7 50 -1 -1 0.000 0 0 -1 0 0 5
|
||||
2550 2250 4425 2250 4425 3750 2550 3750 2550 2250
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 480 75 4500 0.00\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 480 6825 4500 1.00\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 480 1725 4500 0.25\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 480 3525 4500 0.50\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 195 480 5250 4500 0.75\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 240 1710 450 1275 ~33% total keys\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 240 1710 2925 1275 ~33% total keys\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 240 1710 5250 1275 ~33% total keys\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 180 495 2025 3525 ~8%\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 240 1710 300 3525 ~25% total keys\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 240 1710 2625 3525 ~25% total keys\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 180 495 4425 3525 ~8%\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 240 1710 5025 3525 ~25% total keys\001
|
||||
4 0 0 50 -1 2 14 0.0000 4 180 495 6825 3525 ~8%\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 195 2175 3075 4\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 195 4575 3075 4\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 195 6975 3075 4\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 1245 600 600 Chain1\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 1245 3000 600 Chain2\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 1245 5400 600 Chain3\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 285 2100 2625 C\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 285 4500 2625 C\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 285 6900 2625 C\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 1245 525 2850 Chain1\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 1245 2925 2850 Chain2\001
|
||||
4 0 0 50 -1 2 24 0.0000 4 270 1245 5325 2850 Chain3\001
|
||||
4 0 0 50 -1 2 18 0.0000 4 240 4350 1350 4875 Cluster locator, on the unit interval\001
|
||||
{kind=link}
|
Before Width: | Height: | Size: 7.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.4 KiB |
|
|
@ -1,481 +0,0 @@
|
|||
-*- mode: org; -*-
|
||||
#+TITLE: Machi cluster "name game" sketch
|
||||
#+AUTHOR: Scott
|
||||
#+STARTUP: lognotedone hidestars indent showall inlineimages
|
||||
#+SEQ_TODO: TODO WORKING WAITING DONE
|
||||
#+COMMENT: M-x visual-line-mode
|
||||
#+COMMENT: Also, disable auto-fill-mode
|
||||
|
||||
* 1. "Name Games" with random-slicing style consistent hashing
|
||||
|
||||
Our goal: to distribute lots of files very evenly across a large
|
||||
collection of individual, small Machi chains.
|
||||
|
||||
* 2. Assumptions
|
||||
|
||||
** Basic familiarity with Machi high level design and Machi's "projection"
|
||||
|
||||
The [[https://github.com/basho/machi/blob/master/doc/high-level-machi.pdf][Machi high level design document]] contains all of the basic
|
||||
background assumed by the rest of this document.
|
||||
|
||||
** Analogy: "neighborhood : city :: Machi chain : Machi cluster"
|
||||
|
||||
Analogy: The word "machi" in Japanese means small town or
|
||||
neighborhood. As the Tokyo Metropolitan Area is built from many
|
||||
machis and smaller cities, therefore a big, partitioned file store can
|
||||
be built out of many small Machi chains.
|
||||
|
||||
** Familiarity with the Machi chain concept
|
||||
|
||||
It's clear (I hope!) from
|
||||
the [[https://github.com/basho/machi/blob/master/doc/high-level-machi.pdf][Machi high level design document]] that Machi alone does not support
|
||||
any kind of file partitioning/distribution/sharding across multiple
|
||||
small Machi chains. There must be another layer above a Machi chain to
|
||||
provide such partitioning services.
|
||||
|
||||
Using the [[https://github.com/basho/machi/tree/master/prototype/demo-day-hack][cluster quick-and-dirty prototype]] as an
|
||||
architecture sketch, let's now assume that we have ~n~ independent Machi
|
||||
chains. We assume that each of these chains has the same
|
||||
chain length in the nominal case, e.g. chain length of 3.
|
||||
We wish to provide partitioned/distributed file storage
|
||||
across all ~n~ chains. We call the entire collection of ~n~ Machi
|
||||
chains a "cluster".
|
||||
|
||||
We may wish to have several types of Machi clusters. For example:
|
||||
|
||||
+ Chain length of 1 for "don't care if it gets lost,
|
||||
store stuff very very cheaply" data.
|
||||
+ Chain length of 2 for normal data.
|
||||
+ Equivalent to quorum replication's reliability with 3 copies.
|
||||
+ Chain length of 7 for critical, unreplaceable data.
|
||||
+ Equivalent to quorum replication's reliability with 15 copies.
|
||||
|
||||
Each of these types of chains will have a name ~N~ in the
|
||||
namespace. The role of the cluster namespace will be demonstrated in
|
||||
Section 3 below.
|
||||
|
||||
** Continue an early assumption: a Machi chain is unaware of clustering
|
||||
|
||||
Let's continue with an assumption that an individual Machi chain
|
||||
inside of a cluster is completely unaware of the cluster layer.
|
||||
|
||||
** The reader is familiar with the random slicing technique
|
||||
|
||||
I'd done something very-very-nearly-like-this for the Hibari database
|
||||
6 years ago. But the Hibari technique was based on stuff I did at
|
||||
Sendmail, Inc, in 2000, so this technique feels like old news to me.
|
||||
{shrug}
|
||||
|
||||
The following section provides an illustrated example.
|
||||
Very quickly, the random slicing algorithm is:
|
||||
|
||||
- Hash a string onto the unit interval [0.0, 1.0)
|
||||
- Calculate h(unit interval point, Map) -> bin, where ~Map~ divides
|
||||
the unit interval into bins (or partitions or shards).
|
||||
|
||||
Machi's adaptation is in step 1: we do not hash any strings. Instead, we
|
||||
simply choose a number on the unit interval. This number is called
|
||||
the "cluster locator number".
|
||||
|
||||
As described later in this doc, Machi file names are structured into
|
||||
several components. One component of the file name contains the cluster
|
||||
locator number; we use the number as-is for step 2 above.
|
||||
|
||||
*** For more information about Random Slicing
|
||||
|
||||
For a comprehensive description of random slicing, please see the
|
||||
first two papers. For a quicker summary, please see the third
|
||||
reference.
|
||||
|
||||
#+BEGIN_QUOTE
|
||||
Reliable and Randomized Data Distribution Strategies for Large Scale Storage Systems
|
||||
Alberto Miranda et al.
|
||||
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.226.5609
|
||||
(short version, HIPC'11)
|
||||
|
||||
Random Slicing: Efficient and Scalable Data Placement for Large-Scale
|
||||
Storage Systems
|
||||
Alberto Miranda et al.
|
||||
DOI: http://dx.doi.org/10.1145/2632230 (long version, ACM Transactions
|
||||
on Storage, Vol. 10, No. 3, Article 9, 2014)
|
||||
|
||||
[[http://hibari.github.io/hibari-doc/hibari-sysadmin-guide.en.html#chain-migration][Hibari Sysadmin Guide, chain migration section]].
|
||||
http://hibari.github.io/hibari-doc/hibari-sysadmin-guide.en.html#chain-migration
|
||||
#+END_QUOTE
|
||||
|
||||
* 3. A simple illustration
|
||||
|
||||
We use a variation of the Random Slicing hash that we will call
|
||||
~rs_hash_with_float()~. The Erlang-style function type is shown
|
||||
below.
|
||||
|
||||
#+BEGIN_SRC erlang
|
||||
%% type specs, Erlang-style
|
||||
-spec rs_hash_with_float(float(), rs_hash:map()) -> rs_hash:chain_id().
|
||||
#+END_SRC
|
||||
|
||||
I'm borrowing an illustration from the HibariDB documentation here,
|
||||
but it fits my purposes quite well. (I am the original creator of that
|
||||
image, and also the use license is compatible.)
|
||||
|
||||
#+CAPTION: Illustration of 'Map', using four Machi chains
|
||||
|
||||
[[./migration-4.png]]
|
||||
|
||||
Assume that we have a random slicing map called ~Map~. This particular
|
||||
~Map~ maps the unit interval onto 4 Machi chains:
|
||||
|
||||
| Hash range | Chain ID |
|
||||
|-------------+----------|
|
||||
| 0.00 - 0.25 | Chain1 |
|
||||
| 0.25 - 0.33 | Chain4 |
|
||||
| 0.33 - 0.58 | Chain2 |
|
||||
| 0.58 - 0.66 | Chain4 |
|
||||
| 0.66 - 0.91 | Chain3 |
|
||||
| 0.91 - 1.00 | Chain4 |
|
||||
|
||||
Assume that the system chooses a cluster locator of 0.05.
|
||||
According to ~Map~, the value of
|
||||
~rs_hash_with_float(0.05,Map) = Chain1~.
|
||||
Similarly, ~rs_hash_with_float(0.26,Map) = Chain4~.
|
||||
|
||||
This example should look very similar to Hibari's technique.
|
||||
The Hibari documentation has a brief photo illustration of how random
|
||||
slicing works, see [[http://hibari.github.io/hibari-doc/hibari-sysadmin-guide.en.html#chain-migration][Hibari Sysadmin Guide, chain migration]].
|
||||
|
||||
* 4. Use of the cluster namespace: name separation plus chain type
|
||||
|
||||
Let us assume that the cluster framework provides several different types
|
||||
of chains:
|
||||
|
||||
| Chain length | Namespace | Consistency Mode | Comment |
|
||||
|--------------+--------------+------------------+----------------------------------|
|
||||
| 3 | ~normal~ | eventual | Normal storage redundancy & cost |
|
||||
| 2 | ~reduced~ | eventual | Reduced cost storage |
|
||||
| 1 | ~risky~ | eventual | Really, really cheap storage |
|
||||
| 7 | ~paranoid~ | eventual | Safety-critical storage |
|
||||
| 3 | ~sequential~ | strong | Strong consistency |
|
||||
|--------------+--------------+------------------+----------------------------------|
|
||||
|
||||
The client may want to choose the amount of redundancy that its
|
||||
application requires: normal, reduced cost, or perhaps even a single
|
||||
copy. The cluster namespace is used by the client to signal this
|
||||
intention.
|
||||
|
||||
Further, the cluster administrators may wish to use the namespace to
|
||||
provide separate storage for different applications. Jane's
|
||||
application may use the namespace "jane-normal" and Bob's app uses
|
||||
"bob-reduced". Administrators may definine separate groups of
|
||||
chains on separate servers to serve these two applications.
|
||||
|
||||
* 5. In its lifetime, a file may be moved to different chains
|
||||
|
||||
The cluster management scheme may decide that files need to migrate to
|
||||
other chains -- i.e., file that is initially created on chain ID ~X~
|
||||
has been moved to chain ID ~Y~.
|
||||
|
||||
+ For storage load or I/O load balancing reasons.
|
||||
+ Because a chain is being decommissioned by the sysadmin.
|
||||
|
||||
* 6. Floating point is not required ... it is merely convenient for explanation
|
||||
|
||||
NOTE: Use of floating point terms is not required. For example,
|
||||
integer arithmetic could be used, if using a sufficiently large
|
||||
interval to create an even & smooth distribution of hashes across the
|
||||
expected maximum number of chains.
|
||||
|
||||
For example, if the maximum cluster size would be 4,000 individual
|
||||
Machi chains, then a minimum of 12 bits of integer space is required
|
||||
to assign one integer per Machi chain. However, for load balancing
|
||||
purposes, a finer grain of (for example) 100 integers per Machi
|
||||
chain would permit file migration to move increments of
|
||||
approximately 1% of single Machi chain's storage capacity. A
|
||||
minimum of 12+7=19 bits of hash space would be necessary to accommodate
|
||||
these constraints.
|
||||
|
||||
It is likely that Machi's final implementation will choose a 24 bit
|
||||
integer (or perhaps 32 bits) to represent the cluster locator.
|
||||
|
||||
* 7. Proposal: Break the opacity of Machi file names, slightly.
|
||||
|
||||
Machi assigns file names based on:
|
||||
|
||||
~ClientSuppliedPrefix ++ "^" ++ SomeOpaqueFileNameSuffix~
|
||||
|
||||
What if some parts of the system could peek inside of the opaque file name
|
||||
suffix in order to look at the cluster location information that we might
|
||||
code in the filename suffix?
|
||||
|
||||
We break the system into parts that speak two levels of protocols,
|
||||
"high" and "low".
|
||||
|
||||
+ The high level protocol is used outside of the Machi cluster
|
||||
+ The low level protocol is used inside of the Machi cluster
|
||||
|
||||
Both protocols are based on a Protocol Buffers specification and
|
||||
implementation. Other protocols, such as HTTP, will be added later.
|
||||
|
||||
#+BEGIN_SRC
|
||||
+-----------------------+
|
||||
| Machi external client |
|
||||
| e.g. Riak CS |
|
||||
+-----------------------+
|
||||
^
|
||||
| Machi "high" API
|
||||
| ProtoBuffs protocol Machi cluster boundary: outside
|
||||
.........................................................................
|
||||
| Machi cluster boundary: inside
|
||||
v
|
||||
+--------------------------+ +------------------------+
|
||||
| Machi "high" API service | | Machi HTTP API service |
|
||||
+--------------------------+ +------------------------+
|
||||
^ |
|
||||
| +------------------------+
|
||||
v v
|
||||
+------------------------+
|
||||
| Cluster bridge service |
|
||||
+------------------------+
|
||||
^
|
||||
| Machi "low" API
|
||||
| ProtoBuffs protocol
|
||||
+----------------------------------------+----+----+
|
||||
| | | |
|
||||
v v v v
|
||||
+-------------------------+ ... other chains...
|
||||
| Chain C1 (logical view) |
|
||||
| +--------------+ |
|
||||
| | FLU server 1 | |
|
||||
| | +--------------+ |
|
||||
| +--| FLU server 2 | |
|
||||
| +--------------+ | In reality, API bridge talks directly
|
||||
+-------------------------+ to each FLU server in a chain.
|
||||
#+END_SRC
|
||||
|
||||
** The notation we use
|
||||
|
||||
- ~N~ = the cluster namespace, chosen by the client.
|
||||
- ~p~ = file prefix, chosen by the client.
|
||||
- ~L~ = the cluster locator (a number, type is implementation-dependent)
|
||||
- ~Map~ = a mapping of cluster locators to chains
|
||||
- ~T~ = the target chain ID/name
|
||||
- ~u~ = a unique opaque file name suffix, e.g. a GUID string
|
||||
- ~F~ = a Machi file name, i.e., a concatenation of ~p^L^N^u~
|
||||
|
||||
** The details: cluster file append
|
||||
|
||||
0. Cluster client chooses ~N~ and ~p~ (i.e., cluster namespace and
|
||||
file prefix) and sends the append request to a Machi cluster member
|
||||
via the Protocol Buffers "high" API.
|
||||
1. Cluster bridge chooses ~T~ (i.e., target chain), based on criteria
|
||||
such as disk utilization percentage.
|
||||
2. Cluster bridge knows the cluster ~Map~ for namespace ~N~.
|
||||
3. Cluster bridge choose some cluster locator value ~L~ such that
|
||||
~rs_hash_with_float(L,Map) = T~ (see algorithm below).
|
||||
4. Cluster bridge sends its request to chain
|
||||
~T~: ~append_chunk(p,L,N,...) -> {ok,p^L^N^u,ByteOffset}~
|
||||
5. Cluster bridge forwards the reply tuple to the client.
|
||||
6. Client stores/uses the file name ~F = p^L^N^u~.
|
||||
|
||||
** The details: Cluster file read
|
||||
|
||||
0. Cluster client sends the read request to a Machi cluster member via
|
||||
the Protocol Buffers "high" API.
|
||||
1. Cluster bridge parses the file name ~F~ to find
|
||||
the values of ~L~ and ~N~ (recall, ~F = p^L^N^u~).
|
||||
2. Cluster bridge knows the Cluster ~Map~ for type ~N~.
|
||||
3. Cluster bridge calculates ~rs_hash_with_float(L,Map) = T~
|
||||
4. Cluster bridge sends request to chain ~T~:
|
||||
~read_chunk(F,...) ->~ ... reply
|
||||
5. Cluster bridge forwards the reply to the client.
|
||||
|
||||
** The details: calculating 'L' (the cluster locator number) to match a desired target chain
|
||||
|
||||
1. We know ~Map~, the current cluster mapping for a cluster namespace ~N~.
|
||||
2. We look inside of ~Map~, and we find all of the unit interval ranges
|
||||
that map to our desired target chain ~T~. Let's call this list
|
||||
~MapList = [Range1=(start,end],Range2=(start,end],...]~.
|
||||
3. In our example, ~T=Chain2~. The example ~Map~ contains a single
|
||||
unit interval range for ~Chain2~, ~[(0.33,0.58]]~.
|
||||
4. Choose a uniformly random number ~r~ on the unit interval.
|
||||
5. Calculate the cluster locator ~L~ by mapping ~r~ onto the concatenation
|
||||
of the cluster hash space range intervals in ~MapList~. For example,
|
||||
if ~r=0.5~, then ~L = 0.33 + 0.5*(0.58-0.33) = 0.455~, which is
|
||||
exactly in the middle of the ~(0.33,0.58]~ interval.
|
||||
|
||||
** A bit more about the cluster namespaces's meaning and use
|
||||
|
||||
For use by Riak CS, for example, we'd likely start with the following
|
||||
namespaces ... working our way down the list as we add new features
|
||||
and/or re-implement existing CS features.
|
||||
|
||||
- "standard" = Chain length = 3, eventually consistency mode
|
||||
- "reduced" = Chain length = 2, eventually consistency mode.
|
||||
- "stanchion7" = Chain length = 7, strong consistency mode. Perhaps
|
||||
use this namespace for the metadata required to re-implement the
|
||||
operations that are performed by today's Stanchion application.
|
||||
|
||||
We want the cluster framework to:
|
||||
|
||||
- provide means of creating and managing
|
||||
chains of different types, e.g., chain length, consistency mode.
|
||||
- manage the mapping of cluster namespace
|
||||
names to the chains in the system.
|
||||
- provide query functions to map a cluster
|
||||
namespace name to a cluster map,
|
||||
e.g. ~get_cluster_latest_map("reduced") -> Map{generation=7,...}~.
|
||||
|
||||
* 8. File migration (a.k.a. rebalancing/reparitioning/resharding/redistribution)
|
||||
|
||||
** What is "migration"?
|
||||
|
||||
This section describes Machi's file migration. Other storage systems
|
||||
call this process as "rebalancing", "repartitioning", "resharding" or
|
||||
"redistribution".
|
||||
For Riak Core applications, it is called "handoff" and "ring resizing"
|
||||
(depending on the context).
|
||||
See also the [[http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html#Balancer][Hadoop file balancer]] for another example of a data
|
||||
migration process.
|
||||
|
||||
As discussed in section 5, the client can have good reason for wanting
|
||||
to have some control of the initial location of the file within the
|
||||
chain. However, the chain manager has an ongoing interest in
|
||||
balancing resources throughout the lifetime of the file. Disks will
|
||||
get full, hardware will change, read workload will fluctuate,
|
||||
etc etc.
|
||||
|
||||
This document uses the word "migration" to describe moving data from
|
||||
one Machi chain to another chain within a cluster system.
|
||||
|
||||
A simple variation of the Random Slicing hash algorithm can easily
|
||||
accommodate Machi's need to migrate files without interfering with
|
||||
availability. Machi's migration task is much simpler due to the
|
||||
immutable nature of Machi file data.
|
||||
|
||||
** Change to Random Slicing
|
||||
|
||||
The map used by the Random Slicing hash algorithm needs a few simple
|
||||
changes to make file migration straightforward.
|
||||
|
||||
- Add a "generation number", a strictly increasing number (similar to
|
||||
a Machi chain's "epoch number") that reflects the history of
|
||||
changes made to the Random Slicing map
|
||||
- Use a list of Random Slicing maps instead of a single map, one map
|
||||
per chance that files may not have been migrated yet out of
|
||||
that map.
|
||||
|
||||
As an example:
|
||||
|
||||
#+CAPTION: Illustration of 'Map', using four Machi chains
|
||||
|
||||
[[./migration-3to4.png]]
|
||||
|
||||
And the new Random Slicing map for some cluster namespace ~N~ might look
|
||||
like this:
|
||||
|
||||
| Generation number / Namespace | 7 / reduced |
|
||||
|-------------------------------+-------------|
|
||||
| SubMap | 1 |
|
||||
|-------------------------------+-------------|
|
||||
| Hash range | Chain ID |
|
||||
|-------------------------------+-------------|
|
||||
| 0.00 - 0.33 | Chain1 |
|
||||
| 0.33 - 0.66 | Chain2 |
|
||||
| 0.66 - 1.00 | Chain3 |
|
||||
|-------------------------------+-------------|
|
||||
| SubMap | 2 |
|
||||
|-------------------------------+-------------|
|
||||
| Hash range | Chain ID |
|
||||
|-------------------------------+-------------|
|
||||
| 0.00 - 0.25 | Chain1 |
|
||||
| 0.25 - 0.33 | Chain4 |
|
||||
| 0.33 - 0.58 | Chain2 |
|
||||
| 0.58 - 0.66 | Chain4 |
|
||||
| 0.66 - 0.91 | Chain3 |
|
||||
| 0.91 - 1.00 | Chain4 |
|
||||
|
||||
When a new Random Slicing map contains a single submap, then its use
|
||||
is identical to the original Random Slicing algorithm. If the map
|
||||
contains multiple submaps, then the access rules change a bit:
|
||||
|
||||
- Write operations always go to the newest/largest submap.
|
||||
- Read operations attempt to read from all unique submaps.
|
||||
- Skip searching submaps that refer to the same chain ID.
|
||||
- In this example, unit interval value 0.10 is mapped to Chain1
|
||||
by both submaps.
|
||||
- Read from newest/largest submap to oldest/smallest submap.
|
||||
- If not found in any submap, search a second time (to handle races
|
||||
with file copying between submaps).
|
||||
- If the requested data is found, optionally copy it directly to the
|
||||
newest submap. (This is a variation of read repair (RR). RR here
|
||||
accelerates the migration process and can reduce the number of
|
||||
operations required to query servers in multiple submaps).
|
||||
|
||||
The cluster manager is responsible for:
|
||||
|
||||
- Managing the various generations of the cluster Random Slicing maps for
|
||||
all namespaces.
|
||||
- Distributing namespace maps to cluster bridges.
|
||||
- Managing the processes that are responsible for copying "cold" data,
|
||||
i.e., files data that is not regularly accessed, to its new submap
|
||||
location.
|
||||
- When migration of a file to its new chain is confirmed successful,
|
||||
delete it from the old chain.
|
||||
|
||||
In example map #7, the cluster manager will copy files with unit interval
|
||||
assignments in ~(0.25,0.33]~, ~(0.58,0.66]~, and ~(0.91,1.00]~ from their
|
||||
old locations in chain IDs Chain1/2/3 to their new chain,
|
||||
Chain4. When the cluster manager is satisfied that all such files have
|
||||
been copied to Chain4, then the cluster manager can create and
|
||||
distribute a new map, such as:
|
||||
|
||||
| Generation number / Namespace | 8 / reduced |
|
||||
|-------------------------------+-------------|
|
||||
| SubMap | 1 |
|
||||
|-------------------------------+-------------|
|
||||
| Hash range | Chain ID |
|
||||
|-------------------------------+-------------|
|
||||
| 0.00 - 0.25 | Chain1 |
|
||||
| 0.25 - 0.33 | Chain4 |
|
||||
| 0.33 - 0.58 | Chain2 |
|
||||
| 0.58 - 0.66 | Chain4 |
|
||||
| 0.66 - 0.91 | Chain3 |
|
||||
| 0.91 - 1.00 | Chain4 |
|
||||
|
||||
The HibariDB system performs data migrations in almost exactly this
|
||||
manner. However, one important
|
||||
limitation of HibariDB is not being able to
|
||||
perform more than one migration at a time. HibariDB's data is
|
||||
mutable. Mutation causes many problems when migrating data
|
||||
across two submaps; three or more submaps was too complex to implement
|
||||
quickly and correctly.
|
||||
|
||||
Fortunately for Machi, its file data is immutable and therefore can
|
||||
easily manage many migrations in parallel, i.e., its submap list may
|
||||
be several maps long, each one for an in-progress file migration.
|
||||
|
||||
* 9. Other considerations for FLU/sequencer implementations
|
||||
|
||||
** Append to existing file when possible
|
||||
|
||||
The sequencer should always assign new offsets to the latest/newest
|
||||
file for any prefix, as long as all prerequisites are also true,
|
||||
|
||||
- The epoch has not changed. (In AP mode, epoch change -> mandatory
|
||||
file name suffix change.)
|
||||
- The cluster locator number is stable.
|
||||
- The latest file for prefix ~p~ is smaller than maximum file size for
|
||||
a FLU's configuration.
|
||||
|
||||
The stability of the cluster locator number is an implementation detail that
|
||||
must be managed by the cluster bridge.
|
||||
|
||||
Reuse of the same file is not possible if the bridge always chooses a
|
||||
different cluster locator number ~L~ or if the client always uses a unique
|
||||
file prefix ~p~. The latter is a sign of a misbehaved client; the
|
||||
former is a poorly-implemented bridge.
|
||||
|
||||
* 10. Acknowledgments
|
||||
|
||||
The original source for the "migration-4.png" and "migration-3to4.png" images
|
||||
come from the [[http://hibari.github.io/hibari-doc/images/migration-3to4.png][HibariDB documentation]].
|
||||
|
||||
|
|
@ -1,30 +0,0 @@
|
|||
# Clone and compile Machi
|
||||
|
||||
Clone the Machi source repo and compile the source and test code. Run
|
||||
the following commands at your login shell:
|
||||
|
||||
cd /tmp
|
||||
git clone https://github.com/basho/machi.git
|
||||
cd machi
|
||||
git checkout master
|
||||
make # or 'gmake' if GNU make uses an alternate name
|
||||
|
||||
Then run the unit test suite. This may take up to two minutes or so
|
||||
to finish.
|
||||
|
||||
make test
|
||||
|
||||
At the end, the test suite should report that all tests passed. The
|
||||
actual number of tests shown in the "All `X` tests passed" line may be
|
||||
different than the example below.
|
||||
|
||||
[... many lines omitted ...]
|
||||
module 'event_logger'
|
||||
module 'chain_mgr_legacy'
|
||||
=======================================================
|
||||
All 90 tests passed.
|
||||
|
||||
If you had a test failure, a likely cause may be a limit on the number
|
||||
of file descriptors available to your user process. (Recent releases
|
||||
of OS X have a limit of 1024 file descriptors, which may be too slow.)
|
||||
The output of the `limit -n` will tell you your file descriptor limit.
|
||||
|
|
@ -1,38 +0,0 @@
|
|||
## Machi developer environment prerequisites
|
||||
|
||||
1. Machi requires an 64-bit variant of UNIX: OS X, FreeBSD, Linux, or
|
||||
Solaris machine is a standard developer environment for C and C++
|
||||
applications (64-bit versions).
|
||||
2. You'll need the `git` source management utility.
|
||||
3. You'll need the 64-bit Erlang/OTP 17 runtime environment. Please
|
||||
don't use earlier or later versions until we have a chance to fix
|
||||
the compilation warnings that versions R16B and 18 will trigger.
|
||||
Also, please verify that you are not using a 32-bit Erlang/OTP
|
||||
runtime package.
|
||||
|
||||
For `git` and the Erlang runtime, please use your OS-specific
|
||||
package manager to install these. If your package manager doesn't
|
||||
have 64-bit Erlang/OTP version 17 available, then we recommend using the
|
||||
[precompiled packages available at Erlang Solutions](https://www.erlang-solutions.com/resources/download.html).
|
||||
|
||||
Also, please verify that you have enough file descriptors available to
|
||||
your user processes. The output of `ulimit -n` should report at least
|
||||
4,000 file descriptors available. If your limit is lower (a frequent
|
||||
problem for OS X users), please increase it to at least 4,000.
|
||||
|
||||
# Using Vagrant to set up a developer environment for Machi
|
||||
|
||||
The Machi source directory contains a `Vagrantfile` for creating an
|
||||
Ubuntu Linux-based virtual machine for compiling and running Machi.
|
||||
This file is in the
|
||||
[$SRC_TOP/priv/humming-consensus-demo.vagrant](../priv/humming-consensus-demo.vagrant)
|
||||
directory.
|
||||
|
||||
If used as-is, the virtual machine specification is modest.
|
||||
|
||||
* 1 virtual CPU
|
||||
* 512MB virtual memory
|
||||
* 768MB swap space
|
||||
* 79GB sparse virtual disk image. After installing prerequisites and
|
||||
compiling Machi, the root file system uses approximately 2.7 GBytes.
|
||||
|
||||
|
|
@ -1,617 +0,0 @@
|
|||
FLU and Chain Life Cycle Management -*- mode: org; -*-
|
||||
#+STARTUP: lognotedone hidestars indent showall inlineimages
|
||||
#+COMMENT: To generate the outline section: egrep '^\*[*]* ' doc/flu-and-chain-lifecycle.org | egrep -v '^\* Outline' | sed -e 's/^\*\*\* / + /' -e 's/^\*\* / + /' -e 's/^\* /+ /'
|
||||
|
||||
* FLU and Chain Life Cycle Management
|
||||
|
||||
In an ideal world, we (the Machi development team) would have a full
|
||||
vision of how Machi would be managed, down to the last detail of
|
||||
beautiful CLI character and network protocol bit. Our vision isn't
|
||||
complete yet, so we are working one small step at a time.
|
||||
|
||||
* Outline
|
||||
|
||||
+ FLU and Chain Life Cycle Management
|
||||
+ Terminology review
|
||||
+ Terminology: Machi run-time components/services/thingies
|
||||
+ Terminology: Machi chain data structures
|
||||
+ Terminology: Machi cluster data structures
|
||||
+ Overview of administrative life cycles
|
||||
+ Cluster administrative life cycle
|
||||
+ Chain administrative life cycle
|
||||
+ FLU server administrative life cycle
|
||||
+ Quick admin: declarative management of Machi FLU and chain life cycles
|
||||
+ Quick admin uses the "rc.d" config scheme for life cycle management
|
||||
+ Quick admin's declarative "language": an Erlang-flavored AST
|
||||
+ Term 'host': define a new host for FLU services
|
||||
+ Term 'flu': define a new FLU
|
||||
+ Term 'chain': define or reconfigure a chain
|
||||
+ Executing quick admin AST files via the 'machi-admin' utility
|
||||
+ Checking the syntax of an AST file
|
||||
+ Executing an AST file
|
||||
+ Using quick admin to manage multiple machines
|
||||
+ The "rc.d" style configuration file scheme
|
||||
+ Riak had a similar configuration file editing problem (and its solution)
|
||||
+ Machi's "rc.d" file scheme.
|
||||
+ FLU life cycle management using "rc.d" style files
|
||||
+ The key configuration components of a FLU
|
||||
+ Chain life cycle management using "rc.d" style files
|
||||
+ The key configuration components of a chain
|
||||
|
||||
* Terminology review
|
||||
|
||||
** Terminology: Machi run-time components/services/thingies
|
||||
|
||||
+ FLU: a basic Machi server, responsible for managing a collection of
|
||||
files.
|
||||
|
||||
+ Chain: a small collection of FLUs that maintain replicas of the same
|
||||
collection of files. A chain is usually small, 1-3 servers, where
|
||||
more than 3 would be used only in cases when availability of
|
||||
certain data is critical despite failures of several machines.
|
||||
+ The length of a chain is directly proportional to its
|
||||
replication factor, e.g., a chain length=3 will maintain
|
||||
(nominally) 3 replicas of each file.
|
||||
+ To maintain file availability when ~F~ failures have occurred, a
|
||||
chain must be at least ~F+1~ members long. (In comparison, the
|
||||
quorum replication technique requires ~2F+1~ members in the
|
||||
general case.)
|
||||
|
||||
+ Cluster: A collection of Machi chains that are used to store files
|
||||
in a horizontally partitioned/sharded/distributed manner.
|
||||
|
||||
** Terminology: Machi data structures
|
||||
|
||||
+ Projection: used to define a single chain: the chain's consistency
|
||||
mode (strong or eventual consistency), all members (from an
|
||||
administrative point of view), all active members (from a runtime,
|
||||
automatically-managed point of view), repairing/file-syncing members
|
||||
(also runtime, auto-managed), and so on
|
||||
|
||||
+ Epoch: A version number of a projection. The epoch number is used
|
||||
by both clients & servers to manage transitions from one projection
|
||||
to another, e.g., when the chain is temporarily shortened by the
|
||||
failure of a member FLU server.
|
||||
|
||||
** Terminology: Machi cluster data structures
|
||||
|
||||
+ Namespace: A collection of human-friendly names that are mapped to
|
||||
groups of Machi chains that provide the same type of storage
|
||||
service: consistency mode, replication policy, etc.
|
||||
+ A single namespace name, e.g. ~normal-ec~, is paired with a single
|
||||
cluster map (see below).
|
||||
+ Example: ~normal-ec~ might be a collection of Machi chains in
|
||||
eventually-consistent mode that are of length=3.
|
||||
+ Example: ~risky-ec~ might be a collection of Machi chains in
|
||||
eventually-consistent mode that are of length=1.
|
||||
+ Example: ~mgmt-critical~ might be a collection of Machi chains in
|
||||
strongly-consistent mode that are of length=7.
|
||||
|
||||
+ Cluster map: Encodes the rules which partition/shard/distribute
|
||||
the files stored in a particular namespace across a group of chains
|
||||
that collectively store the namespace's files.
|
||||
|
||||
+ Chain weight: A value assigned to each chain within a cluster map
|
||||
structure that defines the relative storage capacity of a chain
|
||||
within the namespace. For example, a chain weight=150 has 50% more
|
||||
capacity than a chain weight=100.
|
||||
|
||||
+ Cluster map epoch: The version number assigned to a cluster map.
|
||||
|
||||
* Overview of administrative life cycles
|
||||
|
||||
** Cluster administrative life cycle
|
||||
|
||||
+ Cluster is first created
|
||||
+ Adds namespaces (e.g. consistency policy + chain length policy) to
|
||||
the cluster
|
||||
+ Chains are added to/removed from a namespace to increase/decrease the
|
||||
namespace's storage capacity.
|
||||
+ Adjust chain weights within a namespace, e.g., to shift files
|
||||
within the namespace to chains with greater storage capacity
|
||||
resources and/or runtime I/O resources.
|
||||
|
||||
A cluster "file migration" is the process of moving files from one
|
||||
namespace member chain to another for purposes of shifting &
|
||||
re-balancing storage capacity and/or runtime I/O capacity.
|
||||
|
||||
** Chain administrative life cycle
|
||||
|
||||
+ A chain is created with an initial FLU membership list.
|
||||
+ Chain may be administratively modified zero or more times to
|
||||
add/remove member FLU servers.
|
||||
+ A chain may be decommissioned.
|
||||
|
||||
See also: http://basho.github.io/machi/edoc/machi_lifecycle_mgr.html
|
||||
|
||||
** FLU server administrative life cycle
|
||||
|
||||
+ A FLU is created after an administrator chooses the FLU's runtime
|
||||
location is selected by the administrator: which machine/virtual
|
||||
machine, IP address and TCP port allocation, etc.
|
||||
+ An unassigned FLU may be added to a chain by chain administrative
|
||||
policy.
|
||||
+ A FLU that is assigned to a chain may be removed from that chain by
|
||||
chain administrative policy.
|
||||
+ In the current implementation, the FLU's Erlang processes will be
|
||||
halted. Then the FLU's data and metadata files will be moved to
|
||||
another area of the disk for safekeeping. Later, a "garbage
|
||||
collection" process can be used for reclaiming disk space used by
|
||||
halted FLU servers.
|
||||
|
||||
See also: http://basho.github.io/machi/edoc/machi_lifecycle_mgr.html
|
||||
|
||||
* Quick admin: declarative management of Machi FLU and chain life cycles
|
||||
|
||||
The "quick admin" scheme is a temporary (?) tool for managing Machi
|
||||
FLU server and chain life cycles in a declarative manner. The API is
|
||||
described in this section.
|
||||
|
||||
** Quick admin uses the "rc.d" config scheme for life cycle management
|
||||
|
||||
As described at the top of
|
||||
http://basho.github.io/machi/edoc/machi_lifecycle_mgr.html, the "rc.d"
|
||||
config files do not manage "policy". "Policy" is doing the right
|
||||
thing with a Machi cluster from a systems administrator's
|
||||
point of view. The "rc.d" config files can only implement decisions
|
||||
made according to policy.
|
||||
|
||||
The "quick admin" tool is a first attempt at automating policy
|
||||
decisions in a safe way (we hope) that is also easy to implement (we
|
||||
hope) with a variety of systems management tools, e.g. Chef, Puppet,
|
||||
Ansible, Saltstack, or plain-old-human-at-a-keyboard.
|
||||
|
||||
** Quick admin's declarative "language": an Erlang-flavored AST
|
||||
|
||||
The "language" that an administrator uses to express desired policy
|
||||
changes is not (yet) a true language. As a quick implementation hack,
|
||||
the current language is an Erlang-flavored abstract syntax tree
|
||||
(AST). The tree isn't very deep, either, frequently just one
|
||||
element tall. (Not much of a tree, is it?)
|
||||
|
||||
There are three terms in the language currently:
|
||||
|
||||
+ ~host~, define a new host that can execute FLU servers
|
||||
+ ~flu~, define a new FLU
|
||||
+ ~chain~, define a new chain or re-configure an existing chain with
|
||||
the same name
|
||||
|
||||
*** Term 'host': define a new host for FLU services
|
||||
|
||||
In this context, a host is a machine, virtual machine, or container
|
||||
that can execute the Machi application and can therefore provide FLU
|
||||
services, i.e. file service, Humming Consensus management.
|
||||
|
||||
Two formats may be used to define a new host:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{host, Name, Props}.
|
||||
{host, Name, AdminI, ClientI, Props}.
|
||||
#+END_SRC
|
||||
|
||||
The shorter tuple is shorthand notation for the latter. If the
|
||||
shorthand form is used, then it will be converted automatically to the
|
||||
long form as:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{host, Name, AdminI=Name, ClientI=Name, Props}.
|
||||
#+END_SRC
|
||||
|
||||
Type information, description, and restrictions:
|
||||
|
||||
+ ~Name::string()~ The ~Name~ attribute must be unique. Note that it
|
||||
is possible to define two different hosts, one using a DNS hostname
|
||||
and one using an IP address. The user must avoid this
|
||||
double-definition because it is not enforced by quick admin.
|
||||
+ The ~Name~ field is used for cross-reference purposes with other
|
||||
terms, e.g., ~flu~ and ~chain~.
|
||||
+ There is no syntax yet for removing a host definition.
|
||||
|
||||
+ ~AdminI::string()~ A DNS hostname or IP address for cluster
|
||||
administration purposes, e.g. SSH access.
|
||||
+ This field is unused at the present time.
|
||||
|
||||
+ ~ClientI::string()~ A DNS hostname or IP address for Machi's client
|
||||
protocol access, e.g., Protocol Buffers network API service.
|
||||
+ This field is unused at the present time.
|
||||
|
||||
+ ~props::proplist()~ is an Erlang-style property list for specifying
|
||||
additional configuration options, debugging information, sysadmin
|
||||
comments, etc.
|
||||
|
||||
+ A full-featured admin tool should also include managing several
|
||||
other aspects of configuration related to a "host". For example,
|
||||
for any single IP address, quick admin assumes that there will be
|
||||
exactly one Erlang VM that is running the Machi application. Of
|
||||
course, it is possible to have dozens of Erlang VMs on the same
|
||||
(let's assume for clarity) hardware machine and all running Machi
|
||||
... but there are additional aspects of such a machine that quick
|
||||
admin does not account for
|
||||
+ multiple IP addresses per machine
|
||||
+ multiple Machi package installation paths
|
||||
+ multiple Machi config files (e.g. cuttlefish config, ~etc.conf~,
|
||||
~vm.args~)
|
||||
+ multiple data directories/file system mount points
|
||||
+ This is also a management problem for quick admin for a single
|
||||
Machi package on a machine to take advantage of bulk data
|
||||
storage using multiple multiple file system mount points.
|
||||
+ multiple Erlang VM host names, required for distributed Erlang,
|
||||
which is used for communication with ~machi~ and ~machi-admin~
|
||||
command line utilities.
|
||||
+ and others....
|
||||
|
||||
*** Term 'flu': define a new FLU
|
||||
|
||||
A new FLU is defined relative to a previously-defined ~host~ entities;
|
||||
an exception will be thrown if the ~host~ cannot be cross-referenced.
|
||||
|
||||
#+BEGIN_SRC
|
||||
{flu, Name, HostName, Port, Props}
|
||||
#+END_SRC
|
||||
|
||||
Type information, description, and restrictions:
|
||||
|
||||
+ ~Name::atom()~ The name of the FLU, as a human-friendly name and
|
||||
also for internal management use; please note the ~atom()~ type.
|
||||
This name must be unique.
|
||||
+ The ~Name~ field is used for cross-reference purposes with the
|
||||
~chain~ term.
|
||||
+ There is no syntax yet for removing a FLU definition.
|
||||
|
||||
+ ~Hostname::string()~ The cross-reference name of the ~host~ that
|
||||
this FLU should run on.
|
||||
|
||||
+ ~Port::non_neg_integer()~ The TCP port used by this FLU server's
|
||||
Protocol Buffers network API listener service
|
||||
|
||||
+ ~props::proplist()~ is an Erlang-style property list for specifying
|
||||
additional configuration options, debugging information, sysadmin
|
||||
comments, etc.
|
||||
|
||||
*** Term 'chain': define or reconfigure a chain
|
||||
|
||||
A chain is defined relative to zero or more previously-defined ~flu~
|
||||
entities; an exception will be thrown if any ~flu~ cannot be
|
||||
cross-referenced.
|
||||
|
||||
Two formats may be used to define/reconfigure a chain:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{chain, Name, FullList, Props}.
|
||||
{chain, Name, CMode, FullList, Witnesses, Props}.
|
||||
#+END_SRC
|
||||
|
||||
The shorter tuple is shorthand notation for the latter. If the
|
||||
shorthand form is used, then it will be converted automatically to the
|
||||
long form as:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{chain, Name, ap_mode, FullList, [], Props}.
|
||||
#+END_SRC
|
||||
|
||||
Type information, description, and restrictions:
|
||||
|
||||
+ ~Name::atom()~ The name of the chain, as a human-friendly name and
|
||||
also for internal management use; please note the ~atom()~ type.
|
||||
This name must be unique.
|
||||
+ There is no syntax yet for removing a chain definition.
|
||||
|
||||
+ ~CMode::'ap_mode'|'cp_mode'~ Defines the consistency mode of the
|
||||
chain, either eventual consistency or strong consistency,
|
||||
respectively.
|
||||
+ A chain cannot change consistency mode, e.g., from
|
||||
strong~->~eventual consistency.
|
||||
|
||||
+ ~FullList::list(atom())~ Specifies the list of full-service FLU
|
||||
servers, i.e. servers that provide file data & metadata services as
|
||||
well as Humming Consensus. Each atom in the list must
|
||||
cross-reference with a previously defined ~chain~; an exception will
|
||||
be thrown if any ~flu~ cannot be cross-referenced.
|
||||
|
||||
+ ~Witnesses::list(atom())~ Specifies the list of witness-only
|
||||
servers, i.e. servers that only participate in Humming Consensus.
|
||||
Each atom in the list must cross-reference with a previously defined
|
||||
~chain~; an exception will be thrown if any ~flu~ cannot be
|
||||
cross-referenced.
|
||||
+ This list must be empty for eventual consistency chains.
|
||||
|
||||
+ ~props::proplist()~ is an Erlang-style property list for specifying
|
||||
additional configuration options, debugging information, sysadmin
|
||||
comments, etc.
|
||||
|
||||
+ If this term specifies a new ~chain~ name, then all of the member
|
||||
FLU servers (full & witness types) will be bootstrapped to a
|
||||
starting configuration.
|
||||
|
||||
+ If this term specifies a previously-defined ~chain~ name, then all
|
||||
of the member FLU servers (full & witness types, respectively) will
|
||||
be adjusted to add or remove members, as appropriate.
|
||||
+ Any FLU servers added to either list must not be assigned to any
|
||||
other chain, or they must be a member of this specific chain.
|
||||
+ Any FLU servers removed from either list will be halted.
|
||||
(See the "FLU server administrative life cycle" section above.)
|
||||
|
||||
** Executing quick admin AST files via the 'machi-admin' utility
|
||||
|
||||
Examples of quick admin AST files can be found in the
|
||||
~priv/quick-admin/examples~ directory. Below is an example that will
|
||||
define a new host ( ~"localhost"~ ), three new FLU servers ( ~f1~ & ~f2~
|
||||
and ~f3~ ), and an eventually consistent chain ( ~c1~ ) that uses the new
|
||||
FLU servers:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{host, "localhost", []}.
|
||||
{flu,f1,"localhost",20401,[]}.
|
||||
{flu,f2,"localhost",20402,[]}.
|
||||
{flu,f3,"localhost",20403,[]}.
|
||||
{chain,c1,[f1,f2,f3],[]}.
|
||||
#+END_SRC
|
||||
|
||||
*** Checking the syntax of an AST file
|
||||
|
||||
Given an AST config file, ~/path/to/ast/file~, its basic syntax and
|
||||
correctness can be checked without executing it.
|
||||
|
||||
#+BEGIN_SRC
|
||||
./rel/machi/bin/machi-admin quick-admin-check /path/to/ast/file
|
||||
#+END_SRC
|
||||
|
||||
+ The utility will exit with status zero and output ~ok~ if the syntax
|
||||
and proposed configuration appears to be correct.
|
||||
+ If there is an error, the utility will exit with status one, and an
|
||||
error message will be printed.
|
||||
|
||||
*** Executing an AST file
|
||||
|
||||
Given an AST config file, ~/path/to/ast/file~, it can be executed
|
||||
using the command:
|
||||
|
||||
#+BEGIN_SRC
|
||||
./rel/machi/bin/machi-admin quick-admin-apply /path/to/ast/file RelativeHost
|
||||
#+END_SRC
|
||||
|
||||
... where the last argument, ~RelativeHost~, should be the exact
|
||||
spelling of one of the previously defined AST ~host~ entities,
|
||||
*and also* is the same host that the ~machi-admin~ utility is being
|
||||
executed on.
|
||||
|
||||
Restrictions and warnings:
|
||||
|
||||
+ This is alpha quality software.
|
||||
|
||||
+ There is no "undo".
|
||||
+ Of course there is, but you need to resort to doing things like
|
||||
using ~machi attach~ to attach to the server's CLI to then execute
|
||||
magic Erlang incantations to stop FLUs, unconfigure chains, etc.
|
||||
+ Oh, and delete some files with magic paths, also.
|
||||
|
||||
** Using quick admin to manage multiple machines
|
||||
|
||||
A quick sketch follows:
|
||||
|
||||
1. Create the AST file to specify all of the changes that you wish to
|
||||
make to all hosts, FLUs, and/or chains, e.g., ~/tmp/ast.txt~.
|
||||
2. Check the basic syntax with the ~quick-admin-check~ argument to
|
||||
~machi-admin~.
|
||||
3. If the syntax is good, then copy ~/tmp/ast.txt~ to all hosts in the
|
||||
cluster, using the same path, ~/tmp/ast.txt~.
|
||||
4. For each machine in the cluster, run:
|
||||
#+BEGIN_SRC
|
||||
./rel/machi/bin/machi-admin quick-admin-apply /tmp/ast.txt RelativeHost
|
||||
#+END_SRC
|
||||
|
||||
... where RelativeHost is the AST ~host~ name of the machine that you
|
||||
are executing the ~machi-admin~ command on. The command should be
|
||||
successful, with exit status 0 and outputting the string ~ok~.
|
||||
|
||||
Finally, for each machine in the cluster, a listing of all files in
|
||||
the directory ~rel/machi/etc/quick-admin-archive~ should show exactly
|
||||
the same files, one for each time that ~quick-admin-apply~ has been
|
||||
run successfully on that machine.
|
||||
|
||||
* The "rc.d" style configuration file scheme
|
||||
|
||||
This configuration scheme is inspired by BSD UNIX's ~init(8)~ process
|
||||
manager's configuration style, called "rc.d" after the name of the
|
||||
directory where these files are stored, ~/etc/rc.d~. The ~init~
|
||||
process is responsible for (among other things) starting UNIX
|
||||
processes at machine boot time and stopping them when the machine is
|
||||
shut down.
|
||||
|
||||
The original scheme used by ~init~ to start processes at boot time was
|
||||
a single Bourne shell script called ~/etc/rc~. When a new software
|
||||
package was installed that required a daemon to be started at boot
|
||||
time, text was added to the ~/etc/rc~ file. Uninstalling packages was
|
||||
much trickier, because it meant removing lines from a file that
|
||||
*is a computer program (run by the Bourne shell, a Turing-complete
|
||||
programming language)*. Error-free editing of the ~/etc/rc~ script
|
||||
was impossible in all cases.
|
||||
|
||||
Later, ~init~'s configuration was split into a few master Bourne shell
|
||||
scripts and a subdirectory, ~/etc/rc.d~. The subdirectory contained
|
||||
shell scripts that were responsible for boot time starting of a single
|
||||
daemon or service, e.g. NFS or an HTTP server. When a new software
|
||||
package was added, a new file was added to the ~rc.d~ subdirectory.
|
||||
When a package was removed, the corresponding file in ~rc.d~ was
|
||||
removed. With this simple scheme, addition & removal of boot time
|
||||
scripts was vastly simplified.
|
||||
|
||||
** Riak had a similar configuration file editing problem (and its solution)
|
||||
|
||||
Another software product from Basho Technologies, Riak, had a similar
|
||||
configuration file editing problem. One file in particular,
|
||||
~app.config~, had a syntax that made it difficult both for human
|
||||
systems administrators and also computer programs to edit the file in
|
||||
a syntactically correct manner.
|
||||
|
||||
Later releases of Riak switched to an alternative configuration file
|
||||
format, one inspired by the BSD UNIX ~sysctl(8)~ utility and
|
||||
~sysctl.conf(5)~ file syntax. The ~sysctl.conf~ format is much easier
|
||||
to manage by computer programs to add items. Removing items is not
|
||||
100% simple, however: the correct lines must be identified and then
|
||||
removed (e.g. with Perl or a text editor or combination of ~grep -v~
|
||||
and ~mv~), but removing any comment lines that "belong" to the removed
|
||||
config item(s) is not any easy for a 1-line shell script to do 100%
|
||||
correctly.
|
||||
|
||||
Machi will use the ~sysctl.conf~ style configuration for some
|
||||
application configuration variables. However, adding & removing FLUs
|
||||
and chains will be managed using the "rc.d" style because of the
|
||||
"rc.d" scheme's simplicity and tolerance of mistakes by administrators
|
||||
(human or computer).
|
||||
|
||||
** Machi's "rc.d" file scheme.
|
||||
|
||||
Machi will use a single subdirectory that will contain configuration
|
||||
files for some life cycle management task, e.g. a single FLU or a
|
||||
single chain.
|
||||
|
||||
The contents of the file should be a single Erlang term, serialized in
|
||||
ASCII form as Erlang source code statement, i.e. a single Erlang term
|
||||
~T~ that is formatted by ~io:format("~w.",[T]).~. This file must be
|
||||
parseable by the Erlang function ~file:consult()~.
|
||||
|
||||
Later versions of Machi may change the file format to be more familiar
|
||||
to administrators who are unaccustomed to Erlang language syntax.
|
||||
|
||||
** FLU life cycle management using "rc.d" style files
|
||||
|
||||
*** The key configuration components of a FLU
|
||||
|
||||
1. The machine (or virtual machine) to run it on.
|
||||
2. The Machi software package's artifacts to execute.
|
||||
3. The disk device(s) used to store Machi file data & metadata, "rc.d"
|
||||
style config files, etc.
|
||||
4. The name, IP address and TCP port assigned to the FLU service.
|
||||
5. Its chain assignment.
|
||||
|
||||
Notes:
|
||||
|
||||
+ Items 1-3 are currently outside of the scope of this life cycle
|
||||
document. We assume that human administrators know how to do these
|
||||
things.
|
||||
+ Item 4's properties are explicitly managed by a FLU-defining "rc.d"
|
||||
style config file.
|
||||
+ Item 5 is managed by the chain life cycle management system.
|
||||
|
||||
Here is an example of a properly formatted FLU config file:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{p_srvr,f1,machi_flu1_client,"192.168.72.23",20401,[]}.
|
||||
#+END_SRC
|
||||
|
||||
... which corresponds to the following Erlang record definition:
|
||||
|
||||
#+BEGIN_SRC
|
||||
-record(p_srvr, {
|
||||
name :: atom(),
|
||||
proto_mod = 'machi_flu1_client' :: atom(), % Module name
|
||||
address :: term(), % Protocol-specific
|
||||
port :: term(), % Protocol-specific
|
||||
props = [] :: list() % proplist for other related info
|
||||
}).
|
||||
#+END_SRC
|
||||
|
||||
+ ~name~ is ~f1~. This is name of the FLU. This name should be
|
||||
unique over the lifetime of the administrative domain and thus
|
||||
managed by external policy. This name must be the same as the name
|
||||
of the config file that defines the FLU.
|
||||
+ ~proto_mod~ is used for internal management purposes and should be
|
||||
considered a mandatory constant.
|
||||
+ ~address~ is "192.168.72.23". The DNS hostname or IP address used
|
||||
by other servers to communicate with this FLU. This must be a valid
|
||||
IP address, previously assigned to this machine/VM using the
|
||||
appropriate operating system-specific procedure.
|
||||
+ ~port~ is TCP port 20401. The TCP port number that the FLU listens
|
||||
to for incoming Protocol Buffers-serialized communication. This TCP
|
||||
port must not be in use (now or in the future) by another Machi FLU
|
||||
or any other process running on this machine/VM.
|
||||
+ ~props~ is an Erlang-style property list for specifying additional
|
||||
configuration options, debugging information, sysadmin comments,
|
||||
etc.
|
||||
|
||||
** Chain life cycle management using "rc.d" style files
|
||||
|
||||
Unlike FLUs, chains have a self-management aspect that makes a chain
|
||||
life cycle different from a single FLU server. Machi's chains are
|
||||
self-managing, via Humming Consensus; see the
|
||||
https://github.com/basho/machi/tree/master/doc/ directory for much
|
||||
more detail about Humming Consensus. After FLUs have received their
|
||||
initial chain configuration for Humming Consensus, the FLUs will
|
||||
manage the chain (and each other) by themselves.
|
||||
|
||||
However, Humming Consensus does not handle three chain management
|
||||
problems:
|
||||
|
||||
1. Specifying the very first chain configuration,
|
||||
2. Altering the membership of the chain (i.e. adding/removing FLUs
|
||||
from the chain),
|
||||
3. Stopping the chain permanently.
|
||||
|
||||
A chain "rc.d" file will only be used to bootstrap a newly-defined FLU
|
||||
server. It's like a piece of glue information to introduce the new
|
||||
FLU to the Humming Consensus group that is managing the chain's
|
||||
dynamic state (e.g. which members are up or down). In all other
|
||||
respects, chain config files are ignored by life cycle management code.
|
||||
However, to mimic the life cycle of the FLU server's "rc.d" config
|
||||
files, a chain "rc.d" files is not deleted until the chain has been
|
||||
decommissioned (i.e. defined with length=0).
|
||||
|
||||
*** The key configuration components of a chain
|
||||
|
||||
1. The name of the chain.
|
||||
2. Consistency mode: eventually consistent or strongly consistent.
|
||||
3. The membership list of all FLU servers in the chain.
|
||||
+ Remember, all servers in a single chain will manage full replicas
|
||||
of the same collection of Machi files.
|
||||
4. If the chain is defined to use strongly consistent mode, then a
|
||||
list of "witness servers" may also be defined. See the
|
||||
[https://github.com/basho/machi/tree/master/doc/] documentation for
|
||||
more information on witness servers.
|
||||
+ The witness list must be empty for all chains in eventual
|
||||
consistency mode.
|
||||
|
||||
Here is an example of a properly formatted chain config file:
|
||||
|
||||
#+BEGIN_SRC
|
||||
{chain_def_v1,c1,ap_mode,
|
||||
[{p_srvr,f1,machi_flu1_client,"localhost",20401,[]},
|
||||
{p_srvr,f2,machi_flu1_client,"localhost",20402,[]},
|
||||
{p_srvr,f3,machi_flu1_client,"localhost",20403,[]}],
|
||||
[],[],[],
|
||||
[f1,f2,f3],
|
||||
[],[]}.
|
||||
#+END_SRC
|
||||
|
||||
... which corresponds to the following Erlang record definition:
|
||||
|
||||
#+BEGIN_SRC
|
||||
-record(chain_def_v1, {
|
||||
name :: atom(), % chain name
|
||||
mode :: 'ap_mode' | 'cp_mode',
|
||||
full = [] :: [p_srvr()],
|
||||
witnesses = [] :: [p_srvr()],
|
||||
old_full = [] :: [atom()], % guard against some races
|
||||
old_witnesses=[] :: [atom()], % guard against some races
|
||||
local_run = [] :: [atom()], % must be tailored to each machine!
|
||||
local_stop = [] :: [atom()], % must be tailored to each machine!
|
||||
props = [] :: list() % proplist for other related info
|
||||
}).
|
||||
#+END_SRC
|
||||
|
||||
+ ~name~ is ~c1~, the name of the chain. This name should be unique
|
||||
over the lifetime of the administrative domain and thus managed by
|
||||
external policy. This name must be the same as the name of the
|
||||
config file that defines the chain.
|
||||
+ ~mode~ is ~ap_mode~, an internal code symbol for eventual
|
||||
consistency mode.
|
||||
+ ~full~ is a list of Erlang ~#p_srvr{}~ records for full-service
|
||||
members of the chain, i.e., providing Machi file data & metadata
|
||||
storage services.
|
||||
+ ~witnesses~ is a list of Erlang ~#p_srvr{}~ records for witness-only
|
||||
FLU servers, i.e., providing only Humming Consensus service.
|
||||
+ The next four fields are used for internal management only.
|
||||
+ ~props~ is an Erlang-style property list for specifying additional
|
||||
configuration options, debugging information, sysadmin comments,
|
||||
etc.
|
||||
|
||||
|
|
@ -1,372 +0,0 @@
|
|||
|
||||
# Table of contents
|
||||
|
||||
* [Hands-on experiments with Machi and Humming Consensus](#hands-on)
|
||||
* [Using the network partition simulator and convergence demo test code](#partition-simulator)
|
||||
|
||||
<a name="hands-on">
|
||||
# Hands-on experiments with Machi and Humming Consensus
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Please refer to the
|
||||
[Machi development environment prerequisites doc](./dev-prerequisites.md)
|
||||
for Machi developer environment prerequisites.
|
||||
|
||||
If you do not have an Erlang/OTP runtime system available, but you do
|
||||
have [the Vagrant virtual machine](https://www.vagrantup.com/) manager
|
||||
available, then please refer to the instructions in the prerequisites
|
||||
doc for using Vagrant.
|
||||
|
||||
<a name="clone-compile">
|
||||
## Clone and compile the code
|
||||
|
||||
Please see the
|
||||
[Machi 'clone and compile' doc](./dev-clone-compile.md)
|
||||
for the short list of steps required to fetch the Machi source code
|
||||
from GitHub and to compile & test Machi.
|
||||
|
||||
## Running three Machi instances on a single machine
|
||||
|
||||
All of the commands that should be run at your login shell (e.g. Bash,
|
||||
c-shell) can be cut-and-pasted from this document directly to your
|
||||
login shell prompt.
|
||||
|
||||
Run the following command:
|
||||
|
||||
make stagedevrel
|
||||
|
||||
This will create a directory structure like this:
|
||||
|
||||
|-dev1-|... stand-alone Machi app + subdirectories
|
||||
|-dev-|-dev2-|... stand-alone Machi app + directories
|
||||
|-dev3-|... stand-alone Machi app + directories
|
||||
|
||||
Each of the `dev/dev1`, `dev/dev2`, and `dev/dev3` are stand-alone
|
||||
application instances of Machi and can be run independently of each
|
||||
other on the same machine. This demo will use all three.
|
||||
|
||||
The lifecycle management utilities for Machi are a bit immature,
|
||||
currently. They assume that each Machi server runs on a host with a
|
||||
unique hostname -- there is no flexibility built-in yet to easily run
|
||||
multiple Machi instances on the same machine. To continue with the
|
||||
demo, we need to use `sudo` or `su` to obtain superuser privileges to
|
||||
edit the `/etc/hosts` file.
|
||||
|
||||
Please add the following line to `/etc/hosts`, using this command:
|
||||
|
||||
sudo sh -c 'echo "127.0.0.1 machi1 machi2 machi3" >> /etc/hosts'
|
||||
|
||||
Next, we will use a shell script to finish setting up our cluster. It
|
||||
will do the following for us:
|
||||
|
||||
* Verify that the new line that was added to `/etc/hosts` is correct.
|
||||
* Modify the `etc/app.config` files to configure the Humming Consensus
|
||||
chain manager's actions logged to the `log/console.log` file.
|
||||
* Start the three application instances.
|
||||
* Verify that the three instances are running correctly.
|
||||
* Configure a single chain, with one FLU server per application
|
||||
instance.
|
||||
|
||||
Please run this script using this command:
|
||||
|
||||
./priv/humming-consensus-demo.setup.sh
|
||||
|
||||
If the output looks like this (and exits with status zero), then the
|
||||
script was successful.
|
||||
|
||||
Step: Verify that the required entries in /etc/hosts are present
|
||||
Step: add a verbose logging option to app.config
|
||||
Step: start three three Machi application instances
|
||||
pong
|
||||
pong
|
||||
pong
|
||||
Step: configure one chain to start a Humming Consensus group with three members
|
||||
Result: ok
|
||||
Result: ok
|
||||
Result: ok
|
||||
|
||||
We have now created a single replica chain, called `c1`, that has
|
||||
three file servers participating in the chain. Thanks to the
|
||||
hostnames that we added to `/etc/hosts`, all are using the localhost
|
||||
network interface.
|
||||
|
||||
| App instance | Pseudo | FLU name | TCP port |
|
||||
| directory | Hostname | | number |
|
||||
|--------------+----------+----------+----------|
|
||||
| dev1 | machi1 | flu1 | 20401 |
|
||||
| dev2 | machi2 | flu2 | 20402 |
|
||||
| dev3 | machi3 | flu3 | 20403 |
|
||||
|
||||
The log files for each application instance can be found in the
|
||||
`./dev/devN/log/console.log` file, where the `N` is the instance
|
||||
number: 1, 2, or 3.
|
||||
|
||||
## Understanding the chain manager's log file output
|
||||
|
||||
After running the `./priv/humming-consensus-demo.setup.sh` script,
|
||||
let's look at the last few lines of the `./dev/dev1/log/console.log`
|
||||
log file for Erlang VM process #1.
|
||||
|
||||
2016-03-09 10:16:35.676 [info] <0.105.0>@machi_lifecycle_mgr:process_pending_flu:422 Started FLU f1 with supervisor pid <0.128.0>
|
||||
2016-03-09 10:16:35.676 [info] <0.105.0>@machi_lifecycle_mgr:move_to_flu_config:540 Creating FLU config file f1
|
||||
2016-03-09 10:16:35.790 [info] <0.105.0>@machi_lifecycle_mgr:bootstrap_chain2:312 Configured chain c1 via FLU f1 to mode=ap_mode all=[f1,f2,f3] witnesses=[]
|
||||
2016-03-09 10:16:35.790 [info] <0.105.0>@machi_lifecycle_mgr:move_to_chain_config:546 Creating chain config file c1
|
||||
2016-03-09 10:16:44.139 [info] <0.132.0> CONFIRM epoch 1141 <<155,42,7,221>> upi [] rep [] auth f1 by f1
|
||||
2016-03-09 10:16:44.271 [info] <0.132.0> CONFIRM epoch 1148 <<57,213,154,16>> upi [f1] rep [] auth f1 by f1
|
||||
2016-03-09 10:16:44.864 [info] <0.132.0> CONFIRM epoch 1151 <<239,29,39,70>> upi [f1] rep [f3] auth f1 by f1
|
||||
2016-03-09 10:16:45.235 [info] <0.132.0> CONFIRM epoch 1152 <<173,17,66,225>> upi [f2] rep [f1,f3] auth f2 by f1
|
||||
2016-03-09 10:16:47.343 [info] <0.132.0> CONFIRM epoch 1154 <<154,231,224,149>> upi [f2,f1,f3] rep [] auth f2 by f1
|
||||
|
||||
Let's pick apart some of these lines. We have started all three
|
||||
servers at about the same time. We see some race conditions happen,
|
||||
and some jostling and readjustment happens pretty quickly in the first
|
||||
few seconds.
|
||||
|
||||
* `Started FLU f1 with supervisor pid <0.128.0>`
|
||||
* This VM, #1,
|
||||
started a FLU (Machi data server) with the name `f1`. In the Erlang
|
||||
process supervisor hierarchy, the process ID of the top supervisor
|
||||
is `<0.128.0>`.
|
||||
* `Configured chain c1 via FLU f1 to mode=ap_mode all=[f1,f2,f3] witnesses=[]`
|
||||
* A bootstrap configuration for a chain named `c1` has been created.
|
||||
* The FLUs/data servers that are eligible for participation in the
|
||||
chain have names `f1`, `f2`, and `f3`.
|
||||
* The chain will operate in eventual consistency mode (`ap_mode`)
|
||||
* The witness server list is empty. Witness servers are never used
|
||||
in eventual consistency mode.
|
||||
* `CONFIRM epoch 1141 <<155,42,7,221>> upi [] rep [] auth f1 by f1`
|
||||
* All participants in epoch 1141 are unanimous in adopting epoch
|
||||
1141's projection. All active membership lists are empty, so
|
||||
there is no functional chain replication yet, at least as far as
|
||||
server `f1` knows
|
||||
* The epoch's abbreviated checksum is `<<155,42,7,221>>`.
|
||||
* The UPI list, i.e. the replicas whose data is 100% in sync is
|
||||
`[]`, the empty list. (UPI = Update Propagation Invariant)
|
||||
* The list of servers that are under data repair (`rep`) is also
|
||||
empty, `[]`.
|
||||
* This projection was authored by server `f1`.
|
||||
* The log message was generated by server `f1`.
|
||||
* `CONFIRM epoch 1148 <<57,213,154,16>> upi [f1] rep [] auth f1 by f1`
|
||||
* Now the server `f1` has created a chain of length 1, `[f1]`.
|
||||
* Chain repair/file re-sync is not required when the UPI server list
|
||||
changes from length 0 -> 1.
|
||||
* `CONFIRM epoch 1151 <<239,29,39,70>> upi [f1] rep [f3] auth f1 by f1`
|
||||
* Server `f1` has noticed that server `f3` is alive. Apparently it
|
||||
has not yet noticed that server `f2` is also running.
|
||||
* Server `f3` is in the repair list.
|
||||
* `CONFIRM epoch 1152 <<173,17,66,225>> upi [f2] rep [f1,f3] auth f2 by f1`
|
||||
* Server `f2` is apparently now aware that all three servers are running.
|
||||
* The previous configuration used by `f2` was `upi [f2]`, i.e., `f2`
|
||||
was running in a chain of one. `f2` noticed that `f1` and `f3`
|
||||
were now available and has started adding them to the chain.
|
||||
* All new servers are always added to the tail of the chain in the
|
||||
repair list.
|
||||
* In eventual consistency mode, a UPI change like this is OK.
|
||||
* When performing a read, a client must read from both tail of the
|
||||
UPI list and also from all repairing servers.
|
||||
* When performing a write, the client writes to both the UPI
|
||||
server list and also the repairing list, in that order.
|
||||
* I.e., the client concatenates both lists,
|
||||
`UPI ++ Repairing`, for its chain configuration for the write.
|
||||
* Server `f2` will trigger file repair/re-sync shortly.
|
||||
* The waiting time for starting repair has been configured to be
|
||||
extremely short, 1 second. The default waiting time is 10
|
||||
seconds, in case Humming Consensus remains unstable.
|
||||
* `CONFIRM epoch 1154 <<154,231,224,149>> upi [f2,f1,f3] rep [] auth f2 by f1`
|
||||
* File repair/re-sync has finished. All file data on all servers
|
||||
are now in sync.
|
||||
* The UPI/in-sync part of the chain is now `[f2,f1,f3]`, and there
|
||||
are no servers under repair.
|
||||
|
||||
## Let's create some failures
|
||||
|
||||
Here are some suggestions for creating failures.
|
||||
|
||||
* Use the `./dev/devN/bin/machi stop` and `./dev/devN/bin/machi start`
|
||||
commands to stop & start VM #`N`.
|
||||
* Stop a VM abnormally by using `kill`. The OS process name to look
|
||||
for is `beam.smp`.
|
||||
* Suspend and resume a VM, using the `SIGSTOP` and `SIGCONT` signals.
|
||||
* E.g. `kill -STOP 9823` and `kill -CONT 9823`
|
||||
|
||||
The network partition simulator is not (yet) available when running
|
||||
Machi in this mode. Please see the next section for instructions on
|
||||
how to use partition simulator.
|
||||
|
||||
|
||||
<a name="partition-simulator">
|
||||
# Using the network partition simulator and convergence demo test code
|
||||
|
||||
This is the demo code mentioned in the presentation that Scott Lystig
|
||||
Fritchie gave at the
|
||||
[RICON 2015 conference](http://ricon.io).
|
||||
* [slides (PDF format)](http://ricon.io/speakers/slides/Scott_Fritchie_Ricon_2015.pdf)
|
||||
* [video](https://www.youtube.com/watch?v=yR5kHL1bu1Q)
|
||||
|
||||
## A complete example of all input and output
|
||||
|
||||
If you don't have an Erlang/OTP 17 runtime environment available,
|
||||
please see this file for full input and output of a strong consistency
|
||||
length=3 chain test:
|
||||
https://gist.github.com/slfritchie/8352efc88cc18e62c72c
|
||||
This file contains all commands input and all simulator output from a
|
||||
sample run of the simulator.
|
||||
|
||||
To help interpret the output of the test, please skip ahead to the
|
||||
"The test output is very verbose" section.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
If you don't have `git` and/or the Erlang 17 runtime system available
|
||||
on your OS X, FreeBSD, Linux, or Solaris machine, please take a look
|
||||
at the [Prerequisites section](#prerequisites) first. When you have
|
||||
installed the prerequisite software, please return back here.
|
||||
|
||||
## Clone and compile the code
|
||||
|
||||
Please briefly visit the [Clone and compile the code](#clone-compile)
|
||||
section. When finished, please return back here.
|
||||
|
||||
## Run an interactive Erlang CLI shell
|
||||
|
||||
Run the following command at your login shell:
|
||||
|
||||
erl -pz .eunit ebin deps/*/ebin
|
||||
|
||||
If you are using Erlang/OTP version 17, you should see some CLI output
|
||||
that looks like this:
|
||||
|
||||
Erlang/OTP 17 [erts-6.4] [source] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
|
||||
|
||||
Eshell V6.4 (abort with ^G)
|
||||
1>
|
||||
|
||||
## The test output is very verbose ... what are the important parts?
|
||||
|
||||
The output of the Erlang command
|
||||
`machi_chain_manager1_converge_demo:help()` will display the following
|
||||
guide to the output of the tests.
|
||||
|
||||
A visualization of the convergence behavior of the chain self-management
|
||||
algorithm for Machi.
|
||||
|
||||
1. Set up some server and chain manager pairs.
|
||||
2. Create a number of different network partition scenarios, where
|
||||
(simulated) partitions may be symmetric or asymmetric. Then stop changing
|
||||
the partitions and keep the simulated network stable (and perhaps broken).
|
||||
3. Run a number of iterations of the algorithm in parallel by poking each
|
||||
of the manager processes on a random'ish basis.
|
||||
4. Afterward, fetch the chain transition changes made by each FLU and
|
||||
verify that no transition was unsafe.
|
||||
|
||||
During the iteration periods, the following is a cheatsheet for the output.
|
||||
See the internal source for interpreting the rest of the output.
|
||||
|
||||
'SET partitions = '
|
||||
|
||||
A pair-wise list of actors which cannot send messages. The
|
||||
list is uni-directional. If there are three servers (a,b,c),
|
||||
and if the partitions list is '[{a,b},{b,c}]' then all
|
||||
messages from a->b and b->c will be dropped, but any other
|
||||
sender->recipient messages will be delivered successfully.
|
||||
|
||||
'x uses:'
|
||||
|
||||
The FLU x has made an internal state transition and is using
|
||||
this epoch's projection as operating chain configuration. The
|
||||
rest of the line is a summary of the projection.
|
||||
|
||||
'CONFIRM epoch {N}'
|
||||
|
||||
This message confirms that all of the servers listed in the
|
||||
UPI and repairing lists of the projection at epoch {N} have
|
||||
agreed to use this projection because they all have written
|
||||
this projection to their respective private projection stores.
|
||||
The chain is now usable by/available to all clients.
|
||||
|
||||
'Sweet, private projections are stable'
|
||||
|
||||
This report announces that this iteration of the test cycle
|
||||
has passed successfully. The report that follows briefly
|
||||
summarizes the latest private projection used by each
|
||||
participating server. For example, when in strong consistency
|
||||
mode with 'a' as a witness and 'b' and 'c' as real servers:
|
||||
|
||||
%% Legend:
|
||||
%% server name, epoch ID, UPI list, repairing list, down list, ...
|
||||
%% ... witness list, 'false' (a constant value)
|
||||
|
||||
[{a,{{1116,<<23,143,246,55>>},[a,b],[],[c],[a],false}},
|
||||
{b,{{1116,<<23,143,246,55>>},[a,b],[],[c],[a],false}}]
|
||||
|
||||
Both servers 'a' and 'b' agree on epoch 1116 with epoch ID
|
||||
{1116,<<23,143,246,55>>} where UPI=[a,b], repairing=[],
|
||||
down=[c], and witnesses=[a].
|
||||
|
||||
Server 'c' is not shown because 'c' has wedged itself OOS (out
|
||||
of service) by configuring a chain length of zero.
|
||||
|
||||
If no servers are listed in the report (i.e. only '[]' is
|
||||
displayed), then all servers have wedged themselves OOS, and
|
||||
the chain is unavailable.
|
||||
|
||||
'DoIt,'
|
||||
|
||||
This marks a group of tick events which trigger the manager
|
||||
processes to evaluate their environment and perhaps make a
|
||||
state transition.
|
||||
|
||||
A long chain of 'DoIt,DoIt,DoIt,' means that the chain state has
|
||||
(probably) settled to a stable configuration, which is the goal of the
|
||||
algorithm.
|
||||
|
||||
Press control-c to interrupt the test....".
|
||||
|
||||
## Run a test in eventual consistency mode
|
||||
|
||||
Run the following command at the Erlang CLI prompt:
|
||||
|
||||
machi_chain_manager1_converge_demo:t(3, [{private_write_verbose,true}]).
|
||||
|
||||
The first argument, `3`, is the number of servers to participate in
|
||||
the chain. Please note:
|
||||
|
||||
* Chain lengths as short as 1 or 2 are valid, but the results are a
|
||||
bit boring.
|
||||
* Chain lengths as long as 7 or 9 can be used, but they may
|
||||
suffer from longer periods of churn/instability before all chain
|
||||
managers reach agreement via humming consensus. (It is future work
|
||||
to shorten the worst of the unstable churn latencies.)
|
||||
* In eventual consistency mode, chain lengths may be even numbers,
|
||||
e.g. 2, 4, or 6.
|
||||
* The simulator will choose partition events from the permutations of
|
||||
all 1, 2, and 3 node partition pairs. The total runtime will
|
||||
increase *dramatically* with chain length.
|
||||
* Chain length 2: about 3 partition cases
|
||||
* Chain length 3: about 35 partition cases
|
||||
* Chain length 4: about 230 partition cases
|
||||
* Chain length 5: about 1100 partition cases
|
||||
|
||||
## Run a test in strong consistency mode (with witnesses):
|
||||
|
||||
*NOTE:* Due to a bug in the test code, please do not try to run the
|
||||
convergence test in strong consistency mode and also without the
|
||||
correct minority number of witness servers! If in doubt, please run
|
||||
the commands shown below exactly.
|
||||
|
||||
Run the following command at the Erlang CLI prompt:
|
||||
|
||||
machi_chain_manager1_converge_demo:t(3, [{private_write_verbose,true}, {consistency_mode, cp_mode}, {witnesses, [a]}]).
|
||||
|
||||
The first argument, `3`, is the number of servers to participate in
|
||||
the chain. Chain lengths as long as 7 or 9 can be used, but they may
|
||||
suffer from longer periods of churn/instability before all chain
|
||||
managers reach agreement via humming consensus.
|
||||
|
||||
Due to the bug mentioned above, please use the following
|
||||
commands when running with chain lengths of 5 or 7, respectively.
|
||||
|
||||
machi_chain_manager1_converge_demo:t(5, [{private_write_verbose,true}, {consistency_mode, cp_mode}, {witnesses, [a,b]}]).
|
||||
machi_chain_manager1_converge_demo:t(7, [{private_write_verbose,true}, {consistency_mode, cp_mode}, {witnesses, [a,b,c]}]).
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 115 KiB |
4
doc/src.high-level/.gitignore
vendored
|
|
@ -1,4 +0,0 @@
|
|||
*.aux
|
||||
*.dvi
|
||||
*.log
|
||||
*.pdf
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
all: machi chain-mgr
|
||||
|
||||
machi:
|
||||
latex high-level-machi.tex
|
||||
dvipdfm high-level-machi.dvi
|
||||
|
||||
chain-mgr:
|
||||
latex high-level-chain-mgr.tex
|
||||
dvipdfm high-level-chain-mgr.dvi
|
||||
|
||||
clean:
|
||||
rm -f *.aux *.dvi *.log
|
||||
|
|
@ -1,268 +0,0 @@
|
|||
%!PS-Adobe-3.0 EPSF-2.0
|
||||
%%BoundingBox: 0 0 416.500000 280.000000
|
||||
%%Creator: mscgen 0.18
|
||||
%%EndComments
|
||||
0.700000 0.700000 scale
|
||||
0 0 moveto
|
||||
0 400 lineto
|
||||
595 400 lineto
|
||||
595 0 lineto
|
||||
closepath
|
||||
clip
|
||||
%PageTrailer
|
||||
%Page: 1 1
|
||||
/Helvetica findfont
|
||||
10 scalefont
|
||||
setfont
|
||||
/Helvetica findfont
|
||||
12 scalefont
|
||||
setfont
|
||||
0 400 translate
|
||||
/mtrx matrix def
|
||||
/ellipse
|
||||
{ /endangle exch def
|
||||
/startangle exch def
|
||||
/ydia exch def
|
||||
/xdia exch def
|
||||
/y exch def
|
||||
/x exch def
|
||||
/savematrix mtrx currentmatrix def
|
||||
x y translate
|
||||
xdia 2 div ydia 2 div scale
|
||||
1 -1 scale
|
||||
0 0 1 startangle endangle arc
|
||||
savematrix setmatrix
|
||||
} def
|
||||
(client) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 42 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
42 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(Projection) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 127 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
127 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(ProjStore_A) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 212 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
212 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(Sequencer_A) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 297 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
297 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_A) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 382 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
382 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_B) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 467 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
467 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_C) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 552 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
552 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
newpath 42 -22 moveto 42 -49 lineto stroke
|
||||
newpath 127 -22 moveto 127 -49 lineto stroke
|
||||
newpath 212 -22 moveto 212 -49 lineto stroke
|
||||
newpath 297 -22 moveto 297 -49 lineto stroke
|
||||
newpath 382 -22 moveto 382 -49 lineto stroke
|
||||
newpath 467 -22 moveto 467 -49 lineto stroke
|
||||
newpath 552 -22 moveto 552 -49 lineto stroke
|
||||
newpath 42 -35 moveto 127 -35 lineto stroke
|
||||
newpath 127 -35 moveto 117 -41 lineto stroke
|
||||
(get current) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 57 -33 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
57 -33 moveto show
|
||||
newpath 42 -49 moveto 42 -76 lineto stroke
|
||||
newpath 127 -49 moveto 127 -76 lineto stroke
|
||||
newpath 212 -49 moveto 212 -76 lineto stroke
|
||||
newpath 297 -49 moveto 297 -76 lineto stroke
|
||||
newpath 382 -49 moveto 382 -76 lineto stroke
|
||||
newpath 467 -49 moveto 467 -76 lineto stroke
|
||||
newpath 552 -49 moveto 552 -76 lineto stroke
|
||||
newpath 127 -62 moveto 42 -62 lineto stroke
|
||||
newpath 42 -62 moveto 52 -68 lineto stroke
|
||||
(ok, #12...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 61 -60 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
61 -60 moveto show
|
||||
newpath 42 -76 moveto 42 -103 lineto stroke
|
||||
newpath 127 -76 moveto 127 -103 lineto stroke
|
||||
newpath 212 -76 moveto 212 -103 lineto stroke
|
||||
newpath 297 -76 moveto 297 -103 lineto stroke
|
||||
newpath 382 -76 moveto 382 -103 lineto stroke
|
||||
newpath 467 -76 moveto 467 -103 lineto stroke
|
||||
newpath 552 -76 moveto 552 -103 lineto stroke
|
||||
newpath 42 -89 moveto 297 -89 lineto stroke
|
||||
newpath 297 -89 moveto 287 -95 lineto stroke
|
||||
(Req. 123 bytes, prefix="foo", epoch=12) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 66 -87 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
66 -87 moveto show
|
||||
newpath 42 -103 moveto 42 -130 lineto stroke
|
||||
newpath 127 -103 moveto 127 -130 lineto stroke
|
||||
newpath 212 -103 moveto 212 -130 lineto stroke
|
||||
newpath 297 -103 moveto 297 -130 lineto stroke
|
||||
newpath 382 -103 moveto 382 -130 lineto stroke
|
||||
newpath 467 -103 moveto 467 -130 lineto stroke
|
||||
newpath 552 -103 moveto 552 -130 lineto stroke
|
||||
newpath 297 -116 moveto 42 -116 lineto stroke
|
||||
newpath 42 -116 moveto 52 -122 lineto stroke
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
(bad_epoch, 13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 131 -114 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
131 -114 moveto show
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
newpath 42 -130 moveto 42 -157 lineto stroke
|
||||
newpath 127 -130 moveto 127 -157 lineto stroke
|
||||
newpath 212 -130 moveto 212 -157 lineto stroke
|
||||
newpath 297 -130 moveto 297 -157 lineto stroke
|
||||
newpath 382 -130 moveto 382 -157 lineto stroke
|
||||
newpath 467 -130 moveto 467 -157 lineto stroke
|
||||
newpath 552 -130 moveto 552 -157 lineto stroke
|
||||
newpath 42 -143 moveto 212 -143 lineto stroke
|
||||
newpath 212 -143 moveto 202 -149 lineto stroke
|
||||
(get epoch #13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 89 -141 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
89 -141 moveto show
|
||||
newpath 42 -157 moveto 42 -184 lineto stroke
|
||||
newpath 127 -157 moveto 127 -184 lineto stroke
|
||||
newpath 212 -157 moveto 212 -184 lineto stroke
|
||||
newpath 297 -157 moveto 297 -184 lineto stroke
|
||||
newpath 382 -157 moveto 382 -184 lineto stroke
|
||||
newpath 467 -157 moveto 467 -184 lineto stroke
|
||||
newpath 552 -157 moveto 552 -184 lineto stroke
|
||||
newpath 212 -170 moveto 42 -170 lineto stroke
|
||||
newpath 42 -170 moveto 52 -176 lineto stroke
|
||||
(ok, #13...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 103 -168 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
103 -168 moveto show
|
||||
newpath 42 -184 moveto 42 -211 lineto stroke
|
||||
newpath 127 -184 moveto 127 -211 lineto stroke
|
||||
newpath 212 -184 moveto 212 -211 lineto stroke
|
||||
newpath 297 -184 moveto 297 -211 lineto stroke
|
||||
newpath 382 -184 moveto 382 -211 lineto stroke
|
||||
newpath 467 -184 moveto 467 -211 lineto stroke
|
||||
newpath 552 -184 moveto 552 -211 lineto stroke
|
||||
newpath 42 -197 moveto 297 -197 lineto stroke
|
||||
newpath 297 -197 moveto 287 -203 lineto stroke
|
||||
(Req. 123 bytes, prefix="foo", epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 66 -195 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
66 -195 moveto show
|
||||
newpath 42 -211 moveto 42 -238 lineto stroke
|
||||
newpath 127 -211 moveto 127 -238 lineto stroke
|
||||
newpath 212 -211 moveto 212 -238 lineto stroke
|
||||
newpath 297 -211 moveto 297 -238 lineto stroke
|
||||
newpath 382 -211 moveto 382 -238 lineto stroke
|
||||
newpath 467 -211 moveto 467 -238 lineto stroke
|
||||
newpath 552 -211 moveto 552 -238 lineto stroke
|
||||
newpath 297 -224 moveto 42 -224 lineto stroke
|
||||
newpath 42 -224 moveto 52 -230 lineto stroke
|
||||
(ok, "foo.seq_a.009" offset=447) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 89 -222 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
89 -222 moveto show
|
||||
newpath 42 -238 moveto 42 -265 lineto stroke
|
||||
newpath 127 -238 moveto 127 -265 lineto stroke
|
||||
newpath 212 -238 moveto 212 -265 lineto stroke
|
||||
newpath 297 -238 moveto 297 -265 lineto stroke
|
||||
newpath 382 -238 moveto 382 -265 lineto stroke
|
||||
newpath 467 -238 moveto 467 -265 lineto stroke
|
||||
newpath 552 -238 moveto 552 -265 lineto stroke
|
||||
newpath 42 -251 moveto 382 -251 lineto stroke
|
||||
newpath 382 -251 moveto 372 -257 lineto stroke
|
||||
(write "foo.seq_a.009" offset=447 <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 51 -249 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
51 -249 moveto show
|
||||
newpath 42 -265 moveto 42 -292 lineto stroke
|
||||
newpath 127 -265 moveto 127 -292 lineto stroke
|
||||
newpath 212 -265 moveto 212 -292 lineto stroke
|
||||
newpath 297 -265 moveto 297 -292 lineto stroke
|
||||
newpath 382 -265 moveto 382 -292 lineto stroke
|
||||
newpath 467 -265 moveto 467 -292 lineto stroke
|
||||
newpath 552 -265 moveto 552 -292 lineto stroke
|
||||
newpath 382 -278 moveto 42 -278 lineto stroke
|
||||
newpath 42 -278 moveto 52 -284 lineto stroke
|
||||
(ok) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 206 -276 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
206 -276 moveto show
|
||||
newpath 42 -292 moveto 42 -319 lineto stroke
|
||||
newpath 127 -292 moveto 127 -319 lineto stroke
|
||||
newpath 212 -292 moveto 212 -319 lineto stroke
|
||||
newpath 297 -292 moveto 297 -319 lineto stroke
|
||||
newpath 382 -292 moveto 382 -319 lineto stroke
|
||||
newpath 467 -292 moveto 467 -319 lineto stroke
|
||||
newpath 552 -292 moveto 552 -319 lineto stroke
|
||||
newpath 42 -305 moveto 467 -305 lineto stroke
|
||||
newpath 467 -305 moveto 457 -311 lineto stroke
|
||||
(write "foo.seq_a.009" offset=447 <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 94 -303 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
94 -303 moveto show
|
||||
newpath 42 -319 moveto 42 -346 lineto stroke
|
||||
newpath 127 -319 moveto 127 -346 lineto stroke
|
||||
newpath 212 -319 moveto 212 -346 lineto stroke
|
||||
newpath 297 -319 moveto 297 -346 lineto stroke
|
||||
newpath 382 -319 moveto 382 -346 lineto stroke
|
||||
newpath 467 -319 moveto 467 -346 lineto stroke
|
||||
newpath 552 -319 moveto 552 -346 lineto stroke
|
||||
newpath 467 -332 moveto 42 -332 lineto stroke
|
||||
newpath 42 -332 moveto 52 -338 lineto stroke
|
||||
(ok) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 249 -330 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
249 -330 moveto show
|
||||
newpath 42 -346 moveto 42 -373 lineto stroke
|
||||
newpath 127 -346 moveto 127 -373 lineto stroke
|
||||
newpath 212 -346 moveto 212 -373 lineto stroke
|
||||
newpath 297 -346 moveto 297 -373 lineto stroke
|
||||
newpath 382 -346 moveto 382 -373 lineto stroke
|
||||
newpath 467 -346 moveto 467 -373 lineto stroke
|
||||
newpath 552 -346 moveto 552 -373 lineto stroke
|
||||
newpath 42 -359 moveto 552 -359 lineto stroke
|
||||
newpath 552 -359 moveto 542 -365 lineto stroke
|
||||
(write "foo.seq_a.009" offset=447 <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 136 -357 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
136 -357 moveto show
|
||||
newpath 42 -373 moveto 42 -400 lineto stroke
|
||||
newpath 127 -373 moveto 127 -400 lineto stroke
|
||||
newpath 212 -373 moveto 212 -400 lineto stroke
|
||||
newpath 297 -373 moveto 297 -400 lineto stroke
|
||||
newpath 382 -373 moveto 382 -400 lineto stroke
|
||||
newpath 467 -373 moveto 467 -400 lineto stroke
|
||||
newpath 552 -373 moveto 552 -400 lineto stroke
|
||||
newpath 552 -386 moveto 42 -386 lineto stroke
|
||||
newpath 42 -386 moveto 52 -392 lineto stroke
|
||||
(ok) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 291 -384 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
291 -384 moveto show
|
||||
|
|
@ -1,345 +0,0 @@
|
|||
%!PS-Adobe-3.0 EPSF-2.0
|
||||
%%BoundingBox: 0 0 416.500000 355.600006
|
||||
%%Creator: mscgen 0.18
|
||||
%%EndComments
|
||||
0.700000 0.700000 scale
|
||||
0 0 moveto
|
||||
0 508 lineto
|
||||
595 508 lineto
|
||||
595 0 lineto
|
||||
closepath
|
||||
clip
|
||||
%PageTrailer
|
||||
%Page: 1 1
|
||||
/Helvetica findfont
|
||||
10 scalefont
|
||||
setfont
|
||||
/Helvetica findfont
|
||||
12 scalefont
|
||||
setfont
|
||||
0 508 translate
|
||||
/mtrx matrix def
|
||||
/ellipse
|
||||
{ /endangle exch def
|
||||
/startangle exch def
|
||||
/ydia exch def
|
||||
/xdia exch def
|
||||
/y exch def
|
||||
/x exch def
|
||||
/savematrix mtrx currentmatrix def
|
||||
x y translate
|
||||
xdia 2 div ydia 2 div scale
|
||||
1 -1 scale
|
||||
0 0 1 startangle endangle arc
|
||||
savematrix setmatrix
|
||||
} def
|
||||
(client) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 42 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
42 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(Projection) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 127 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
127 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(ProjStore_A) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 212 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
212 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(Sequencer_A) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 297 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
297 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_A) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 382 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
382 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_B) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 467 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
467 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_C) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 552 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
552 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
newpath 42 -22 moveto 42 -49 lineto stroke
|
||||
newpath 127 -22 moveto 127 -49 lineto stroke
|
||||
newpath 212 -22 moveto 212 -49 lineto stroke
|
||||
newpath 297 -22 moveto 297 -49 lineto stroke
|
||||
newpath 382 -22 moveto 382 -49 lineto stroke
|
||||
newpath 467 -22 moveto 467 -49 lineto stroke
|
||||
newpath 552 -22 moveto 552 -49 lineto stroke
|
||||
newpath 42 -35 moveto 127 -35 lineto stroke
|
||||
newpath 127 -35 moveto 117 -41 lineto stroke
|
||||
(get current) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 57 -33 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
57 -33 moveto show
|
||||
newpath 42 -49 moveto 42 -76 lineto stroke
|
||||
newpath 127 -49 moveto 127 -76 lineto stroke
|
||||
newpath 212 -49 moveto 212 -76 lineto stroke
|
||||
newpath 297 -49 moveto 297 -76 lineto stroke
|
||||
newpath 382 -49 moveto 382 -76 lineto stroke
|
||||
newpath 467 -49 moveto 467 -76 lineto stroke
|
||||
newpath 552 -49 moveto 552 -76 lineto stroke
|
||||
newpath 127 -62 moveto 42 -62 lineto stroke
|
||||
newpath 42 -62 moveto 52 -68 lineto stroke
|
||||
(ok, #12...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 61 -60 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
61 -60 moveto show
|
||||
newpath 42 -76 moveto 42 -103 lineto stroke
|
||||
newpath 127 -76 moveto 127 -103 lineto stroke
|
||||
newpath 212 -76 moveto 212 -103 lineto stroke
|
||||
newpath 297 -76 moveto 297 -103 lineto stroke
|
||||
newpath 382 -76 moveto 382 -103 lineto stroke
|
||||
newpath 467 -76 moveto 467 -103 lineto stroke
|
||||
newpath 552 -76 moveto 552 -103 lineto stroke
|
||||
newpath 42 -89 moveto 382 -89 lineto stroke
|
||||
newpath 382 -89 moveto 372 -95 lineto stroke
|
||||
(append prefix="foo" <<123 bytes...>> epoch=12) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 85 -87 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
85 -87 moveto show
|
||||
newpath 42 -103 moveto 42 -130 lineto stroke
|
||||
newpath 127 -103 moveto 127 -130 lineto stroke
|
||||
newpath 212 -103 moveto 212 -130 lineto stroke
|
||||
newpath 297 -103 moveto 297 -130 lineto stroke
|
||||
newpath 382 -103 moveto 382 -130 lineto stroke
|
||||
newpath 467 -103 moveto 467 -130 lineto stroke
|
||||
newpath 552 -103 moveto 552 -130 lineto stroke
|
||||
newpath 382 -116 moveto 42 -116 lineto stroke
|
||||
newpath 42 -116 moveto 52 -122 lineto stroke
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
(bad_epoch, 13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 173 -114 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
173 -114 moveto show
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
newpath 42 -130 moveto 42 -157 lineto stroke
|
||||
newpath 127 -130 moveto 127 -157 lineto stroke
|
||||
newpath 212 -130 moveto 212 -157 lineto stroke
|
||||
newpath 297 -130 moveto 297 -157 lineto stroke
|
||||
newpath 382 -130 moveto 382 -157 lineto stroke
|
||||
newpath 467 -130 moveto 467 -157 lineto stroke
|
||||
newpath 552 -130 moveto 552 -157 lineto stroke
|
||||
newpath 42 -143 moveto 212 -143 lineto stroke
|
||||
newpath 212 -143 moveto 202 -149 lineto stroke
|
||||
(get epoch #13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 89 -141 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
89 -141 moveto show
|
||||
newpath 42 -157 moveto 42 -184 lineto stroke
|
||||
newpath 127 -157 moveto 127 -184 lineto stroke
|
||||
newpath 212 -157 moveto 212 -184 lineto stroke
|
||||
newpath 297 -157 moveto 297 -184 lineto stroke
|
||||
newpath 382 -157 moveto 382 -184 lineto stroke
|
||||
newpath 467 -157 moveto 467 -184 lineto stroke
|
||||
newpath 552 -157 moveto 552 -184 lineto stroke
|
||||
newpath 212 -170 moveto 42 -170 lineto stroke
|
||||
newpath 42 -170 moveto 52 -176 lineto stroke
|
||||
(ok, #13...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 103 -168 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
103 -168 moveto show
|
||||
newpath 42 -184 moveto 42 -211 lineto stroke
|
||||
newpath 127 -184 moveto 127 -211 lineto stroke
|
||||
newpath 212 -184 moveto 212 -211 lineto stroke
|
||||
newpath 297 -184 moveto 297 -211 lineto stroke
|
||||
newpath 382 -184 moveto 382 -211 lineto stroke
|
||||
newpath 467 -184 moveto 467 -211 lineto stroke
|
||||
newpath 552 -184 moveto 552 -211 lineto stroke
|
||||
newpath 42 -197 moveto 382 -197 lineto stroke
|
||||
newpath 382 -197 moveto 372 -203 lineto stroke
|
||||
(append prefix="foo" <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 85 -195 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
85 -195 moveto show
|
||||
newpath 42 -211 moveto 42 -238 lineto stroke
|
||||
newpath 127 -211 moveto 127 -238 lineto stroke
|
||||
newpath 212 -211 moveto 212 -238 lineto stroke
|
||||
newpath 297 -211 moveto 297 -238 lineto stroke
|
||||
newpath 382 -211 moveto 382 -238 lineto stroke
|
||||
newpath 467 -211 moveto 467 -238 lineto stroke
|
||||
newpath 552 -211 moveto 552 -238 lineto stroke
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
newpath 263 -211 moveto 417 -211 lineto 417 -236 lineto 263 -236 lineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
newpath 269 -211 moveto 411 -211 lineto stroke
|
||||
newpath 269 -236 moveto 411 -236 lineto stroke
|
||||
newpath 269 -211 moveto 263 -223 lineto stroke
|
||||
newpath 263 -223 moveto 269 -236 lineto stroke
|
||||
newpath 411 -211 moveto 417 -223 lineto stroke
|
||||
newpath 417 -223 moveto 411 -236 lineto stroke
|
||||
(Co-located on same box) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 275 -227 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
275 -227 moveto show
|
||||
newpath 42 -238 moveto 42 -265 lineto stroke
|
||||
newpath 127 -238 moveto 127 -265 lineto stroke
|
||||
newpath 212 -238 moveto 212 -265 lineto stroke
|
||||
newpath 297 -238 moveto 297 -265 lineto stroke
|
||||
newpath 382 -238 moveto 382 -265 lineto stroke
|
||||
newpath 467 -238 moveto 467 -265 lineto stroke
|
||||
newpath 552 -238 moveto 552 -265 lineto stroke
|
||||
newpath 382 -251 moveto 297 -251 lineto stroke
|
||||
newpath 297 -251 moveto 307 -257 lineto stroke
|
||||
(Req. 123 bytes, prefix="foo", epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 236 -249 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
236 -249 moveto show
|
||||
newpath 42 -265 moveto 42 -292 lineto stroke
|
||||
newpath 127 -265 moveto 127 -292 lineto stroke
|
||||
newpath 212 -265 moveto 212 -292 lineto stroke
|
||||
newpath 297 -265 moveto 297 -292 lineto stroke
|
||||
newpath 382 -265 moveto 382 -292 lineto stroke
|
||||
newpath 467 -265 moveto 467 -292 lineto stroke
|
||||
newpath 552 -265 moveto 552 -292 lineto stroke
|
||||
newpath 297 -278 moveto 382 -278 lineto stroke
|
||||
newpath 382 -278 moveto 372 -284 lineto stroke
|
||||
(ok, "foo.seq_a.009" offset=447) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 259 -276 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
259 -276 moveto show
|
||||
newpath 42 -292 moveto 42 -319 lineto stroke
|
||||
newpath 127 -292 moveto 127 -319 lineto stroke
|
||||
newpath 212 -292 moveto 212 -319 lineto stroke
|
||||
newpath 297 -292 moveto 297 -319 lineto stroke
|
||||
newpath 382 -292 moveto 382 -319 lineto stroke
|
||||
newpath 467 -292 moveto 467 -319 lineto stroke
|
||||
newpath 552 -292 moveto 552 -319 lineto stroke
|
||||
newpath 382 -305 85 13 270 90 ellipse stroke
|
||||
newpath 382 -311 moveto 392 -317 lineto stroke
|
||||
(write "foo.seq_a.009" offset=447 <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 58 -303 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
58 -303 moveto show
|
||||
newpath 42 -319 moveto 42 -346 lineto stroke
|
||||
newpath 127 -319 moveto 127 -346 lineto stroke
|
||||
newpath 212 -319 moveto 212 -346 lineto stroke
|
||||
newpath 297 -319 moveto 297 -346 lineto stroke
|
||||
newpath 382 -319 moveto 382 -346 lineto stroke
|
||||
newpath 467 -319 moveto 467 -346 lineto stroke
|
||||
newpath 552 -319 moveto 552 -346 lineto stroke
|
||||
newpath 382 -332 moveto 467 -332 lineto stroke
|
||||
newpath 467 -332 moveto 457 -338 lineto stroke
|
||||
(write "foo.seq_a.009" offset=447 <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 264 -330 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
264 -330 moveto show
|
||||
newpath 42 -346 moveto 42 -373 lineto stroke
|
||||
newpath 127 -346 moveto 127 -373 lineto stroke
|
||||
newpath 212 -346 moveto 212 -373 lineto stroke
|
||||
newpath 297 -346 moveto 297 -373 lineto stroke
|
||||
newpath 382 -346 moveto 382 -373 lineto stroke
|
||||
newpath 467 -346 moveto 467 -373 lineto stroke
|
||||
newpath 552 -346 moveto 552 -373 lineto stroke
|
||||
newpath 467 -359 moveto 552 -359 lineto stroke
|
||||
newpath 552 -359 moveto 542 -365 lineto stroke
|
||||
(write "foo.seq_a.009" offset=447 <<123 bytes...>> epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 273 -357 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
273 -357 moveto show
|
||||
newpath 42 -373 moveto 42 -400 lineto stroke
|
||||
newpath 127 -373 moveto 127 -400 lineto stroke
|
||||
newpath 212 -373 moveto 212 -400 lineto stroke
|
||||
newpath 297 -373 moveto 297 -400 lineto stroke
|
||||
newpath 382 -373 moveto 382 -400 lineto stroke
|
||||
newpath 467 -373 moveto 467 -400 lineto stroke
|
||||
newpath 552 -373 moveto 552 -400 lineto stroke
|
||||
newpath 552 -386 moveto 42 -386 lineto stroke
|
||||
newpath 42 -386 moveto 52 -392 lineto stroke
|
||||
(ok, "foo.seq_a.009" offset=447) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 216 -384 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
216 -384 moveto show
|
||||
newpath 42 -400 moveto 42 -427 lineto stroke
|
||||
newpath 127 -400 moveto 127 -427 lineto stroke
|
||||
newpath 212 -400 moveto 212 -427 lineto stroke
|
||||
newpath 297 -400 moveto 297 -427 lineto stroke
|
||||
newpath 382 -400 moveto 382 -427 lineto stroke
|
||||
newpath 467 -400 moveto 467 -427 lineto stroke
|
||||
newpath 552 -400 moveto 552 -427 lineto stroke
|
||||
(The above is "fast path" for FLU->FLU forwarding.) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 164 -416 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
164 -416 moveto show
|
||||
[2] 0 setdash
|
||||
newpath 21 -413 moveto 162 -413 lineto stroke
|
||||
[] 0 setdash
|
||||
[2] 0 setdash
|
||||
newpath 432 -413 moveto 574 -413 lineto stroke
|
||||
[] 0 setdash
|
||||
newpath 42 -427 moveto 42 -454 lineto stroke
|
||||
newpath 127 -427 moveto 127 -454 lineto stroke
|
||||
newpath 212 -427 moveto 212 -454 lineto stroke
|
||||
newpath 297 -427 moveto 297 -454 lineto stroke
|
||||
newpath 382 -427 moveto 382 -454 lineto stroke
|
||||
newpath 467 -427 moveto 467 -454 lineto stroke
|
||||
newpath 552 -427 moveto 552 -454 lineto stroke
|
||||
(If, in an alternate scenario, FLU_C has an error...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 167 -443 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
167 -443 moveto show
|
||||
[2] 0 setdash
|
||||
newpath 21 -440 moveto 165 -440 lineto stroke
|
||||
[] 0 setdash
|
||||
[2] 0 setdash
|
||||
newpath 429 -440 moveto 574 -440 lineto stroke
|
||||
[] 0 setdash
|
||||
newpath 42 -454 moveto 42 -481 lineto stroke
|
||||
newpath 127 -454 moveto 127 -481 lineto stroke
|
||||
newpath 212 -454 moveto 212 -481 lineto stroke
|
||||
newpath 297 -454 moveto 297 -481 lineto stroke
|
||||
newpath 382 -454 moveto 382 -481 lineto stroke
|
||||
newpath 467 -454 moveto 467 -481 lineto stroke
|
||||
newpath 552 -454 moveto 552 -481 lineto stroke
|
||||
newpath 552 -467 moveto 42 -467 lineto stroke
|
||||
newpath 42 -467 moveto 52 -473 lineto stroke
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
(bad_epoch, 15) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 258 -465 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
258 -465 moveto show
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
newpath 42 -481 moveto 42 -508 lineto stroke
|
||||
newpath 127 -481 moveto 127 -508 lineto stroke
|
||||
newpath 212 -481 moveto 212 -508 lineto stroke
|
||||
newpath 297 -481 moveto 297 -508 lineto stroke
|
||||
newpath 382 -481 moveto 382 -508 lineto stroke
|
||||
newpath 467 -481 moveto 467 -508 lineto stroke
|
||||
newpath 552 -481 moveto 552 -508 lineto stroke
|
||||
(... then repair becomes the client's responsibility \("slow path"\).) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 133 -497 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
133 -497 moveto show
|
||||
[2] 0 setdash
|
||||
newpath 21 -494 moveto 131 -494 lineto stroke
|
||||
[] 0 setdash
|
||||
[2] 0 setdash
|
||||
newpath 464 -494 moveto 574 -494 lineto stroke
|
||||
[] 0 setdash
|
||||
|
|
@ -1,557 +0,0 @@
|
|||
%!PS-Adobe-3.0 EPSF-3.0
|
||||
%%Title: figure6.fig
|
||||
%%Creator: fig2dev Version 3.2 Patchlevel 5d
|
||||
%%CreationDate: Mon Oct 20 21:56:33 2014
|
||||
%%For: fritchie@sbb3.local (Scott Lystig Fritchie)
|
||||
%%BoundingBox: 0 0 633 332
|
||||
%Magnification: 1.0000
|
||||
%%EndComments
|
||||
%%BeginProlog
|
||||
/$F2psDict 200 dict def
|
||||
$F2psDict begin
|
||||
$F2psDict /mtrx matrix put
|
||||
/col-1 {0 setgray} bind def
|
||||
/col0 {0.000 0.000 0.000 srgb} bind def
|
||||
/col1 {0.000 0.000 1.000 srgb} bind def
|
||||
/col2 {0.000 1.000 0.000 srgb} bind def
|
||||
/col3 {0.000 1.000 1.000 srgb} bind def
|
||||
/col4 {1.000 0.000 0.000 srgb} bind def
|
||||
/col5 {1.000 0.000 1.000 srgb} bind def
|
||||
/col6 {1.000 1.000 0.000 srgb} bind def
|
||||
/col7 {1.000 1.000 1.000 srgb} bind def
|
||||
/col8 {0.000 0.000 0.560 srgb} bind def
|
||||
/col9 {0.000 0.000 0.690 srgb} bind def
|
||||
/col10 {0.000 0.000 0.820 srgb} bind def
|
||||
/col11 {0.530 0.810 1.000 srgb} bind def
|
||||
/col12 {0.000 0.560 0.000 srgb} bind def
|
||||
/col13 {0.000 0.690 0.000 srgb} bind def
|
||||
/col14 {0.000 0.820 0.000 srgb} bind def
|
||||
/col15 {0.000 0.560 0.560 srgb} bind def
|
||||
/col16 {0.000 0.690 0.690 srgb} bind def
|
||||
/col17 {0.000 0.820 0.820 srgb} bind def
|
||||
/col18 {0.560 0.000 0.000 srgb} bind def
|
||||
/col19 {0.690 0.000 0.000 srgb} bind def
|
||||
/col20 {0.820 0.000 0.000 srgb} bind def
|
||||
/col21 {0.560 0.000 0.560 srgb} bind def
|
||||
/col22 {0.690 0.000 0.690 srgb} bind def
|
||||
/col23 {0.820 0.000 0.820 srgb} bind def
|
||||
/col24 {0.500 0.190 0.000 srgb} bind def
|
||||
/col25 {0.630 0.250 0.000 srgb} bind def
|
||||
/col26 {0.750 0.380 0.000 srgb} bind def
|
||||
/col27 {1.000 0.500 0.500 srgb} bind def
|
||||
/col28 {1.000 0.630 0.630 srgb} bind def
|
||||
/col29 {1.000 0.750 0.750 srgb} bind def
|
||||
/col30 {1.000 0.880 0.880 srgb} bind def
|
||||
/col31 {1.000 0.840 0.000 srgb} bind def
|
||||
|
||||
end
|
||||
|
||||
/cp {closepath} bind def
|
||||
/ef {eofill} bind def
|
||||
/gr {grestore} bind def
|
||||
/gs {gsave} bind def
|
||||
/sa {save} bind def
|
||||
/rs {restore} bind def
|
||||
/l {lineto} bind def
|
||||
/m {moveto} bind def
|
||||
/rm {rmoveto} bind def
|
||||
/n {newpath} bind def
|
||||
/s {stroke} bind def
|
||||
/sh {show} bind def
|
||||
/slc {setlinecap} bind def
|
||||
/slj {setlinejoin} bind def
|
||||
/slw {setlinewidth} bind def
|
||||
/srgb {setrgbcolor} bind def
|
||||
/rot {rotate} bind def
|
||||
/sc {scale} bind def
|
||||
/sd {setdash} bind def
|
||||
/ff {findfont} bind def
|
||||
/sf {setfont} bind def
|
||||
/scf {scalefont} bind def
|
||||
/sw {stringwidth} bind def
|
||||
/tr {translate} bind def
|
||||
/tnt {dup dup currentrgbcolor
|
||||
4 -2 roll dup 1 exch sub 3 -1 roll mul add
|
||||
4 -2 roll dup 1 exch sub 3 -1 roll mul add
|
||||
4 -2 roll dup 1 exch sub 3 -1 roll mul add srgb}
|
||||
bind def
|
||||
/shd {dup dup currentrgbcolor 4 -2 roll mul 4 -2 roll mul
|
||||
4 -2 roll mul srgb} bind def
|
||||
/reencdict 12 dict def /ReEncode { reencdict begin
|
||||
/newcodesandnames exch def /newfontname exch def /basefontname exch def
|
||||
/basefontdict basefontname findfont def /newfont basefontdict maxlength dict def
|
||||
basefontdict { exch dup /FID ne { dup /Encoding eq
|
||||
{ exch dup length array copy newfont 3 1 roll put }
|
||||
{ exch newfont 3 1 roll put } ifelse } { pop pop } ifelse } forall
|
||||
newfont /FontName newfontname put newcodesandnames aload pop
|
||||
128 1 255 { newfont /Encoding get exch /.notdef put } for
|
||||
newcodesandnames length 2 idiv { newfont /Encoding get 3 1 roll put } repeat
|
||||
newfontname newfont definefont pop end } def
|
||||
/isovec [
|
||||
8#055 /minus 8#200 /grave 8#201 /acute 8#202 /circumflex 8#203 /tilde
|
||||
8#204 /macron 8#205 /breve 8#206 /dotaccent 8#207 /dieresis
|
||||
8#210 /ring 8#211 /cedilla 8#212 /hungarumlaut 8#213 /ogonek 8#214 /caron
|
||||
8#220 /dotlessi 8#230 /oe 8#231 /OE
|
||||
8#240 /space 8#241 /exclamdown 8#242 /cent 8#243 /sterling
|
||||
8#244 /currency 8#245 /yen 8#246 /brokenbar 8#247 /section 8#250 /dieresis
|
||||
8#251 /copyright 8#252 /ordfeminine 8#253 /guillemotleft 8#254 /logicalnot
|
||||
8#255 /hyphen 8#256 /registered 8#257 /macron 8#260 /degree 8#261 /plusminus
|
||||
8#262 /twosuperior 8#263 /threesuperior 8#264 /acute 8#265 /mu 8#266 /paragraph
|
||||
8#267 /periodcentered 8#270 /cedilla 8#271 /onesuperior 8#272 /ordmasculine
|
||||
8#273 /guillemotright 8#274 /onequarter 8#275 /onehalf
|
||||
8#276 /threequarters 8#277 /questiondown 8#300 /Agrave 8#301 /Aacute
|
||||
8#302 /Acircumflex 8#303 /Atilde 8#304 /Adieresis 8#305 /Aring
|
||||
8#306 /AE 8#307 /Ccedilla 8#310 /Egrave 8#311 /Eacute
|
||||
8#312 /Ecircumflex 8#313 /Edieresis 8#314 /Igrave 8#315 /Iacute
|
||||
8#316 /Icircumflex 8#317 /Idieresis 8#320 /Eth 8#321 /Ntilde 8#322 /Ograve
|
||||
8#323 /Oacute 8#324 /Ocircumflex 8#325 /Otilde 8#326 /Odieresis 8#327 /multiply
|
||||
8#330 /Oslash 8#331 /Ugrave 8#332 /Uacute 8#333 /Ucircumflex
|
||||
8#334 /Udieresis 8#335 /Yacute 8#336 /Thorn 8#337 /germandbls 8#340 /agrave
|
||||
8#341 /aacute 8#342 /acircumflex 8#343 /atilde 8#344 /adieresis 8#345 /aring
|
||||
8#346 /ae 8#347 /ccedilla 8#350 /egrave 8#351 /eacute
|
||||
8#352 /ecircumflex 8#353 /edieresis 8#354 /igrave 8#355 /iacute
|
||||
8#356 /icircumflex 8#357 /idieresis 8#360 /eth 8#361 /ntilde 8#362 /ograve
|
||||
8#363 /oacute 8#364 /ocircumflex 8#365 /otilde 8#366 /odieresis 8#367 /divide
|
||||
8#370 /oslash 8#371 /ugrave 8#372 /uacute 8#373 /ucircumflex
|
||||
8#374 /udieresis 8#375 /yacute 8#376 /thorn 8#377 /ydieresis] def
|
||||
/Times-Bold /Times-Bold-iso isovec ReEncode
|
||||
/Times-Roman /Times-Roman-iso isovec ReEncode
|
||||
/$F2psBegin {$F2psDict begin /$F2psEnteredState save def} def
|
||||
/$F2psEnd {$F2psEnteredState restore end} def
|
||||
|
||||
/pageheader {
|
||||
save
|
||||
newpath 0 332 moveto 0 0 lineto 633 0 lineto 633 332 lineto closepath clip newpath
|
||||
-331.7 473.8 translate
|
||||
1 -1 scale
|
||||
$F2psBegin
|
||||
10 setmiterlimit
|
||||
0 slj 0 slc
|
||||
0.06000 0.06000 sc
|
||||
} bind def
|
||||
/pagefooter {
|
||||
$F2psEnd
|
||||
restore
|
||||
} bind def
|
||||
%%EndProlog
|
||||
pageheader
|
||||
%
|
||||
% Fig objects follow
|
||||
%
|
||||
%
|
||||
% here starts figure with depth 50
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
5925 7275 m
|
||||
gs 1 -1 sc (Step 6: Client now knows that projection 12 is invalid. Fetch projection 13, then retry at step #8.) col16 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8550 3225 m
|
||||
gs 1 -1 sc (Get epoch 13) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 6900 m
|
||||
gs 1 -1 sc (Active=[a,b,c]) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 6675 m
|
||||
gs 1 -1 sc (Members=[a,b,c]) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 6450 m
|
||||
gs 1 -1 sc (Epoch=13) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 5580 m
|
||||
gs 1 -1 sc (Epoch=12) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 5835 m
|
||||
gs 1 -1 sc (Members=[a,b,c]) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 6090 m
|
||||
gs 1 -1 sc (Active=[a,b]) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5925 5175 m
|
||||
gs 1 -1 sc (Projection \(data structure\)) col0 sh gr
|
||||
% Polyline
|
||||
0 slj
|
||||
0 slc
|
||||
15.000 slw
|
||||
n 8400 4950 m 5625 4950 l 5625 7050 l 8400 7050 l
|
||||
cp gs col0 s gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 6405 m
|
||||
gs 1 -1 sc (- write once) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 6660 m
|
||||
gs 1 -1 sc (- key=integer) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 6915 m
|
||||
gs 1 -1 sc (- value=projection data structure) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 7170 m
|
||||
gs 1 -1 sc (k=11, v=...) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 7425 m
|
||||
gs 1 -1 sc (k=12, v=...) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 7680 m
|
||||
gs 1 -1 sc (k=13, v=...) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 6150 m
|
||||
gs 1 -1 sc (FLU projection store \(proc\)) col0 sh gr
|
||||
% Polyline
|
||||
n 12750 5925 m 15900 5925 l 15900 7725 l 12750 7725 l
|
||||
cp gs col0 s gr
|
||||
% Polyline
|
||||
gs clippath
|
||||
14788 5055 m 14940 5055 l 14940 4995 l 14788 4995 l 14788 4995 l 14908 5025 l 14788 5055 l cp
|
||||
14612 4995 m 14460 4995 l 14460 5055 l 14612 5055 l 14612 5055 l 14492 5025 l 14612 4995 l cp
|
||||
eoclip
|
||||
n 14475 5025 m
|
||||
14925 5025 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 14612 4995 m 14492 5025 l 14612 5055 l col0 s
|
||||
% arrowhead
|
||||
n 14788 5055 m 14908 5025 l 14788 4995 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
15688 5055 m 15840 5055 l 15840 4995 l 15688 4995 l 15688 4995 l 15808 5025 l 15688 5055 l cp
|
||||
15137 4995 m 14985 4995 l 14985 5055 l 15137 5055 l 15137 5055 l 15017 5025 l 15137 4995 l cp
|
||||
eoclip
|
||||
n 15000 5025 m
|
||||
15825 5025 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 15137 4995 m 15017 5025 l 15137 5055 l col0 s
|
||||
% arrowhead
|
||||
n 15688 5055 m 15808 5025 l 15688 4995 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
14638 5355 m 14790 5355 l 14790 5295 l 14638 5295 l 14638 5295 l 14758 5325 l 14638 5355 l cp
|
||||
14612 5295 m 14460 5295 l 14460 5355 l 14612 5355 l 14612 5355 l 14492 5325 l 14612 5295 l cp
|
||||
eoclip
|
||||
n 14475 5325 m 14550 5325 l 14625 5325 l 14700 5325 l 14775 5325 l 14700 5325 l
|
||||
|
||||
14775 5325 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 14612 5295 m 14492 5325 l 14612 5355 l col0 s
|
||||
% arrowhead
|
||||
n 14638 5355 m 14758 5325 l 14638 5295 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
15163 5355 m 15315 5355 l 15315 5295 l 15163 5295 l 15163 5295 l 15283 5325 l 15163 5355 l cp
|
||||
15137 5295 m 14985 5295 l 14985 5355 l 15137 5355 l 15137 5355 l 15017 5325 l 15137 5295 l cp
|
||||
eoclip
|
||||
n 15000 5325 m 15075 5325 l 15150 5325 l 15225 5325 l
|
||||
15300 5325 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 15137 5295 m 15017 5325 l 15137 5355 l col0 s
|
||||
% arrowhead
|
||||
n 15163 5355 m 15283 5325 l 15163 5295 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
15688 5355 m 15840 5355 l 15840 5295 l 15688 5295 l 15688 5295 l 15808 5325 l 15688 5355 l cp
|
||||
15587 5295 m 15435 5295 l 15435 5355 l 15587 5355 l 15587 5355 l 15467 5325 l 15587 5295 l cp
|
||||
eoclip
|
||||
n 15450 5325 m 15525 5325 l 15600 5325 l 15675 5325 l 15750 5325 l
|
||||
15825 5325 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 15587 5295 m 15467 5325 l 15587 5355 l col0 s
|
||||
% arrowhead
|
||||
n 15688 5355 m 15808 5325 l 15688 5295 l col0 s
|
||||
% Polyline
|
||||
[60] 0 sd
|
||||
n 14475 5025 m
|
||||
15825 5025 l gs col0 s gr [] 0 sd
|
||||
% Polyline
|
||||
[60] 0 sd
|
||||
n 14475 5325 m
|
||||
15825 5325 l gs col0 s gr [] 0 sd
|
||||
% Polyline
|
||||
[60] 0 sd
|
||||
n 14475 5550 m
|
||||
15825 5550 l gs col0 s gr [] 0 sd
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 4575 m
|
||||
gs 1 -1 sc (epoch=13) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 4830 m
|
||||
gs 1 -1 sc (files:) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 5085 m
|
||||
gs 1 -1 sc ( "foo.seq_a.006") col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 5340 m
|
||||
gs 1 -1 sc ( "foo.seq_b.007") col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 5595 m
|
||||
gs 1 -1 sc ( "foo.seq_b.008") col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 4275 m
|
||||
gs 1 -1 sc (FLU \(proc\)) col0 sh gr
|
||||
% Polyline
|
||||
15.000 slw
|
||||
n 12750 4050 m 15975 4050 l 15975 5775 l 12750 5775 l
|
||||
cp gs col0 s gr
|
||||
% Polyline
|
||||
n 12750 2775 m 15150 2775 l 15150 3900 l 12750 3900 l
|
||||
cp gs col0 s gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 3000 m
|
||||
gs 1 -1 sc (Sequencer \(proc\)) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 3300 m
|
||||
gs 1 -1 sc (epoch=13) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
12825 3555 m
|
||||
gs 1 -1 sc (map=[{"foo", next_file=8,) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
13500 3750 m
|
||||
gs 1 -1 sc (next_offset=0}...]) col0 sh gr
|
||||
% Polyline
|
||||
n 5700 3975 m 5700 4275 l 8250 4275 l 8250 3075 l 7950 3075 l 7950 3975 l
|
||||
|
||||
5700 3975 l cp gs col0 s gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5775 4200 m
|
||||
gs 1 -1 sc (server logic) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5775 3060 m
|
||||
gs 1 -1 sc (Append <<123 bytes>>) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5775 3315 m
|
||||
gs 1 -1 sc (to a file with prefix) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5775 3570 m
|
||||
gs 1 -1 sc ("foo".) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
5775 2700 m
|
||||
gs 1 -1 sc (CLIENT \(proc\)) col0 sh gr
|
||||
% Polyline
|
||||
gs clippath
|
||||
5970 3763 m 5970 3915 l 6030 3915 l 6030 3763 l 6030 3763 l 6000 3883 l 5970 3763 l cp
|
||||
eoclip
|
||||
n 6000 3600 m
|
||||
6000 3900 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 5970 3763 m 6000 3883 l 6030 3763 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
6630 3737 m 6630 3585 l 6570 3585 l 6570 3737 l 6570 3737 l 6600 3617 l 6630 3737 l cp
|
||||
eoclip
|
||||
n 6600 3900 m 6600 3825 l 6600 3750 l 6600 3675 l
|
||||
6600 3600 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 6630 3737 m 6600 3617 l 6570 3737 l col0 s
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
6675 3900 m
|
||||
gs 1 -1 sc (ok) col0 sh gr
|
||||
% Polyline
|
||||
15.000 slw
|
||||
n 5550 4350 m 8325 4350 l 8325 2475 l 5550 2475 l
|
||||
cp gs col0 s gr
|
||||
% Polyline
|
||||
gs clippath
|
||||
8143 4500 m 8035 4393 l 7993 4435 l 8100 4543 l 8100 4543 l 8037 4437 l 8143 4500 l cp
|
||||
eoclip
|
||||
n 12525 5175 m 8775 5175 l
|
||||
8025 4425 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 8143 4500 m 8037 4437 l 8100 4543 l col0 s
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
11625 5100 m
|
||||
gs 1 -1 sc (ok) col0 sh gr
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
5970 4663 m 5970 4815 l 6030 4815 l 6030 4663 l 6030 4663 l 6000 4783 l 5970 4663 l cp
|
||||
eoclip
|
||||
n 6000 4425 m
|
||||
6000 4800 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 5970 4663 m 6000 4783 l 6030 4663 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
6630 4562 m 6630 4410 l 6570 4410 l 6570 4562 l 6570 4562 l 6600 4442 l 6630 4562 l cp
|
||||
eoclip
|
||||
n 6600 4800 m 6600 4650 l 6600 4575 l 6600 4500 l
|
||||
6600 4425 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 6630 4562 m 6600 4442 l 6570 4562 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
12388 2730 m 12540 2730 l 12540 2670 l 12388 2670 l 12388 2670 l 12508 2700 l 12388 2730 l cp
|
||||
eoclip
|
||||
n 8475 2700 m
|
||||
12525 2700 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 12388 2730 m 12508 2700 l 12388 2670 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
8612 2970 m 8460 2970 l 8460 3030 l 8612 3030 l 8612 3030 l 8492 3000 l 8612 2970 l cp
|
||||
eoclip
|
||||
n 12525 3000 m
|
||||
8475 3000 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 8612 2970 m 8492 3000 l 8612 3030 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
8612 3645 m 8460 3645 l 8460 3705 l 8612 3705 l 8612 3705 l 8492 3675 l 8612 3645 l cp
|
||||
eoclip
|
||||
n 12525 6900 m 12000 6900 l 12000 3675 l
|
||||
8475 3675 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 8612 3645 m 8492 3675 l 8612 3705 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
12388 3330 m 12540 3330 l 12540 3270 l 12388 3270 l 12388 3270 l 12508 3300 l 12388 3330 l cp
|
||||
eoclip
|
||||
n 8475 3975 m 12300 3975 l 12300 3300 l
|
||||
12525 3300 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 12388 3330 m 12508 3300 l 12388 3270 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
12388 4905 m 12540 4905 l 12540 4845 l 12388 4845 l 12388 4845 l 12508 4875 l 12388 4905 l cp
|
||||
eoclip
|
||||
n 8250 4425 m 8700 4875 l
|
||||
12525 4875 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 12388 4905 m 12508 4875 l 12388 4845 l col0 s
|
||||
% Polyline
|
||||
15.000 slw
|
||||
n 12675 2400 m 16050 2400 l 16050 7875 l 12675 7875 l
|
||||
cp gs col0 s gr
|
||||
% Polyline
|
||||
gs clippath
|
||||
8612 4245 m 8460 4245 l 8460 4305 l 8612 4305 l 8612 4305 l 8492 4275 l 8612 4245 l cp
|
||||
eoclip
|
||||
n 12525 3600 m 12375 3600 l 12375 4275 l
|
||||
8475 4275 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 8612 4245 m 8492 4275 l 8612 4305 l col0 s
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8850 5625 m
|
||||
gs 1 -1 sc (Write to FLU B -> ok) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8850 6135 m
|
||||
gs 1 -1 sc (Write to FLU C -> ok) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8550 2625 m
|
||||
gs 1 -1 sc (Request 123 bytes, prefix="foo", epoch=12) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
11100 2925 m
|
||||
gs 1 -1 sc ({bad_epoch,13}) col4 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
10875 3600 m
|
||||
gs 1 -1 sc ({ok, proj=...}) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8550 4500 m
|
||||
gs 1 -1 sc (Write <<123 bytes>> to) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8550 4755 m
|
||||
gs 1 -1 sc (file="foo.seq_a.008", offset=0) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
13575 2625 m
|
||||
gs 1 -1 sc (Server A) col0 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
8550 3900 m
|
||||
gs 1 -1 sc (Req. 123 bytes, prefix="foo", epoch=13) col0 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
6075 3825 m
|
||||
gs 1 -1 sc (1) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
6075 4650 m
|
||||
gs 1 -1 sc (2) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
6675 4650 m
|
||||
gs 1 -1 sc (3) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
10950 2850 m
|
||||
gs 1 -1 sc (5) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
10725 3525 m
|
||||
gs 1 -1 sc (7) col16 sh gr
|
||||
/Times-Bold-iso ff 200.00 scf sf
|
||||
9375 4200 m
|
||||
gs 1 -1 sc (file="foo.seq_a.008", offset=0) col0 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
8400 3225 m
|
||||
gs 1 -1 sc (6) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
8400 2625 m
|
||||
gs 1 -1 sc (4) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
6675 3750 m
|
||||
gs 1 -1 sc (16) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
8400 3900 m
|
||||
gs 1 -1 sc (8) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
9225 4200 m
|
||||
gs 1 -1 sc (9) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
8400 4500 m
|
||||
gs 1 -1 sc (10) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
8475 5625 m
|
||||
gs 1 -1 sc (12,13) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
8475 6075 m
|
||||
gs 1 -1 sc (14,15) col16 sh gr
|
||||
/Times-Roman-iso ff 166.67 scf sf
|
||||
11400 5100 m
|
||||
gs 1 -1 sc (11) col16 sh gr
|
||||
% Polyline
|
||||
15.000 slw
|
||||
gs clippath
|
||||
12388 6630 m 12540 6630 l 12540 6570 l 12388 6570 l 12388 6570 l 12508 6600 l 12388 6630 l cp
|
||||
eoclip
|
||||
n 8475 3300 m 12150 3300 l 12150 6600 l
|
||||
12525 6600 l gs col0 s gr gr
|
||||
|
||||
% arrowhead
|
||||
7.500 slw
|
||||
n 12388 6630 m 12508 6600 l 12388 6570 l col0 s
|
||||
% here ends figure;
|
||||
pagefooter
|
||||
showpage
|
||||
%%Trailer
|
||||
%EOF
|
||||
|
|
@ -1,145 +0,0 @@
|
|||
%!PS-Adobe-3.0 EPSF-2.0
|
||||
%%BoundingBox: 0 0 420.000000 166.599991
|
||||
%%Creator: mscgen 0.18
|
||||
%%EndComments
|
||||
0.700000 0.700000 scale
|
||||
0 0 moveto
|
||||
0 238 lineto
|
||||
600 238 lineto
|
||||
600 0 lineto
|
||||
closepath
|
||||
clip
|
||||
%PageTrailer
|
||||
%Page: 1 1
|
||||
/Helvetica findfont
|
||||
10 scalefont
|
||||
setfont
|
||||
/Helvetica findfont
|
||||
12 scalefont
|
||||
setfont
|
||||
0 238 translate
|
||||
/mtrx matrix def
|
||||
/ellipse
|
||||
{ /endangle exch def
|
||||
/startangle exch def
|
||||
/ydia exch def
|
||||
/xdia exch def
|
||||
/y exch def
|
||||
/x exch def
|
||||
/savematrix mtrx currentmatrix def
|
||||
x y translate
|
||||
xdia 2 div ydia 2 div scale
|
||||
1 -1 scale
|
||||
0 0 1 startangle endangle arc
|
||||
savematrix setmatrix
|
||||
} def
|
||||
(client) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 75 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
75 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(Projection) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 225 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
225 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(ProjStore_C) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 375 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
375 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
(FLU_C) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup dup newpath 525 -17 moveto 2 div neg 0 rmoveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
525 -15 moveto dup stringwidth pop 2 div neg 0 rmoveto show
|
||||
newpath 75 -22 moveto 75 -49 lineto stroke
|
||||
newpath 225 -22 moveto 225 -49 lineto stroke
|
||||
newpath 375 -22 moveto 375 -49 lineto stroke
|
||||
newpath 525 -22 moveto 525 -49 lineto stroke
|
||||
newpath 75 -35 moveto 225 -35 lineto stroke
|
||||
newpath 225 -35 moveto 215 -41 lineto stroke
|
||||
(get current) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 122 -33 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
122 -33 moveto show
|
||||
newpath 75 -49 moveto 75 -76 lineto stroke
|
||||
newpath 225 -49 moveto 225 -76 lineto stroke
|
||||
newpath 375 -49 moveto 375 -76 lineto stroke
|
||||
newpath 525 -49 moveto 525 -76 lineto stroke
|
||||
newpath 225 -62 moveto 75 -62 lineto stroke
|
||||
newpath 75 -62 moveto 85 -68 lineto stroke
|
||||
(ok, #12...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 126 -60 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
126 -60 moveto show
|
||||
newpath 75 -76 moveto 75 -103 lineto stroke
|
||||
newpath 225 -76 moveto 225 -103 lineto stroke
|
||||
newpath 375 -76 moveto 375 -103 lineto stroke
|
||||
newpath 525 -76 moveto 525 -103 lineto stroke
|
||||
newpath 75 -89 moveto 525 -89 lineto stroke
|
||||
newpath 525 -89 moveto 515 -95 lineto stroke
|
||||
(read "foo.seq_a.009" offset=447 bytes=123 epoch=12) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 157 -87 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
157 -87 moveto show
|
||||
newpath 75 -103 moveto 75 -130 lineto stroke
|
||||
newpath 225 -103 moveto 225 -130 lineto stroke
|
||||
newpath 375 -103 moveto 375 -130 lineto stroke
|
||||
newpath 525 -103 moveto 525 -130 lineto stroke
|
||||
newpath 525 -116 moveto 75 -116 lineto stroke
|
||||
newpath 75 -116 moveto 85 -122 lineto stroke
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
(bad_epoch, 13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 261 -114 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
1.000000 0.000000 0.000000 setrgbcolor
|
||||
261 -114 moveto show
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
newpath 75 -130 moveto 75 -157 lineto stroke
|
||||
newpath 225 -130 moveto 225 -157 lineto stroke
|
||||
newpath 375 -130 moveto 375 -157 lineto stroke
|
||||
newpath 525 -130 moveto 525 -157 lineto stroke
|
||||
newpath 75 -143 moveto 375 -143 lineto stroke
|
||||
newpath 375 -143 moveto 365 -149 lineto stroke
|
||||
(get epoch #13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 187 -141 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
187 -141 moveto show
|
||||
newpath 75 -157 moveto 75 -184 lineto stroke
|
||||
newpath 225 -157 moveto 225 -184 lineto stroke
|
||||
newpath 375 -157 moveto 375 -184 lineto stroke
|
||||
newpath 525 -157 moveto 525 -184 lineto stroke
|
||||
newpath 375 -170 moveto 75 -170 lineto stroke
|
||||
newpath 75 -170 moveto 85 -176 lineto stroke
|
||||
(ok, #13...) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 201 -168 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
201 -168 moveto show
|
||||
newpath 75 -184 moveto 75 -211 lineto stroke
|
||||
newpath 225 -184 moveto 225 -211 lineto stroke
|
||||
newpath 375 -184 moveto 375 -211 lineto stroke
|
||||
newpath 525 -184 moveto 525 -211 lineto stroke
|
||||
newpath 75 -197 moveto 525 -197 lineto stroke
|
||||
newpath 525 -197 moveto 515 -203 lineto stroke
|
||||
(read "foo.seq_a.009" offset=447 bytes=123 epoch=13) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 157 -195 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
157 -195 moveto show
|
||||
newpath 75 -211 moveto 75 -238 lineto stroke
|
||||
newpath 225 -211 moveto 225 -238 lineto stroke
|
||||
newpath 375 -211 moveto 375 -238 lineto stroke
|
||||
newpath 525 -211 moveto 525 -238 lineto stroke
|
||||
newpath 525 -224 moveto 75 -224 lineto stroke
|
||||
newpath 75 -224 moveto 85 -230 lineto stroke
|
||||
(ok, <<...123...>>) dup stringwidth
|
||||
1.000000 1.000000 1.000000 setrgbcolor
|
||||
pop dup newpath 257 -222 moveto 0 rlineto 0 11 rlineto neg 0 rlineto closepath fill
|
||||
0.000000 0.000000 0.000000 setrgbcolor
|
||||
257 -222 moveto show
|
||||
2
ebin/.gitignore
vendored
|
|
@ -1,2 +0,0 @@
|
|||
*.beam
|
||||
*.app
|
||||
|
|
@ -1,63 +0,0 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Copyright (c) 2007-2015 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
%% Version 2.0 (the "License"); you may not use this file
|
||||
%% except in compliance with the License. You may obtain
|
||||
%% a copy of the License at
|
||||
%%
|
||||
%% http://www.apache.org/licenses/LICENSE-2.0
|
||||
%%
|
||||
%% Unless required by applicable law or agreed to in writing,
|
||||
%% software distributed under the License is distributed on an
|
||||
%% "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
%% KIND, either express or implied. See the License for the
|
||||
%% specific language governing permissions and limitations
|
||||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
%% @doc Now 4GiBytes, could be up to 64bit due to PB message limit of
|
||||
%% chunk size
|
||||
-define(DEFAULT_MAX_FILE_SIZE, ((1 bsl 32) - 1)).
|
||||
-define(MINIMUM_OFFSET, 1024).
|
||||
|
||||
%% 0th draft of checksum typing with 1st byte.
|
||||
-define(CSUM_TAG_NONE, 0). % No csum provided by client
|
||||
-define(CSUM_TAG_CLIENT_SHA, 1). % Client-generated SHA1
|
||||
-define(CSUM_TAG_SERVER_SHA, 2). % Server-genereated SHA1
|
||||
-define(CSUM_TAG_SERVER_REGEN_SHA, 3). % Server-regenerated SHA1
|
||||
|
||||
-define(CSUM_TAG_NONE_ATOM, none).
|
||||
-define(CSUM_TAG_CLIENT_SHA_ATOM, client_sha).
|
||||
-define(CSUM_TAG_SERVER_SHA_ATOM, server_sha).
|
||||
-define(CSUM_TAG_SERVER_REGEN_SHA_ATOM, server_regen_sha).
|
||||
|
||||
%% Protocol Buffers goop
|
||||
-define(PB_MAX_MSG_SIZE, (33*1024*1024)).
|
||||
-define(PB_PACKET_OPTS, [{packet, 4}, {packet_size, ?PB_MAX_MSG_SIZE}]).
|
||||
|
||||
%% TODO: it's used in flu_sup and elsewhere, change this to suitable name
|
||||
-define(TEST_ETS_TABLE, test_ets_table).
|
||||
|
||||
-define(DEFAULT_COC_NAMESPACE, "").
|
||||
-define(DEFAULT_COC_LOCATOR, 0).
|
||||
|
||||
-record(ns_info, {
|
||||
version = 0 :: machi_dt:namespace_version(),
|
||||
name = <<>> :: machi_dt:namespace(),
|
||||
locator = 0 :: machi_dt:locator()
|
||||
}).
|
||||
|
||||
-record(append_opts, {
|
||||
chunk_extra = 0 :: machi_dt:chunk_size(),
|
||||
preferred_file_name :: 'undefined' | machi_dt:file_name_s(),
|
||||
flag_fail_preferred = false :: boolean()
|
||||
}).
|
||||
|
||||
-record(read_opts, {
|
||||
no_checksum = false :: boolean(),
|
||||
no_chunk = false :: boolean(),
|
||||
needs_trimmed = false :: boolean()
|
||||
}).
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Copyright (c) 2007-2015 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
%% Version 2.0 (the "License"); you may not use this file
|
||||
%% except in compliance with the License. You may obtain
|
||||
%% a copy of the License at
|
||||
%%
|
||||
%% http://www.apache.org/licenses/LICENSE-2.0
|
||||
%%
|
||||
%% Unless required by applicable law or agreed to in writing,
|
||||
%% software distributed under the License is distributed on an
|
||||
%% "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
%% KIND, either express or implied. See the License for the
|
||||
%% specific language governing permissions and limitations
|
||||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-include("machi_projection.hrl").
|
||||
|
||||
-define(NOT_FLAPPING, {0,0,0}).
|
||||
|
||||
-type projection() :: #projection_v1{}.
|
||||
|
||||
|
|
@ -1,20 +0,0 @@
|
|||
%% machi merkle tree records
|
||||
|
||||
-record(naive, {
|
||||
chunk_size = 1048576 :: pos_integer(), %% default 1 MB
|
||||
recalc = true :: boolean(),
|
||||
root :: 'undefined' | binary(),
|
||||
lvl1 = [] :: [ binary() ],
|
||||
lvl2 = [] :: [ binary() ],
|
||||
lvl3 = [] :: [ binary() ],
|
||||
leaves = [] :: [ { Offset :: pos_integer(),
|
||||
Size :: pos_integer(),
|
||||
Csum :: binary()} ]
|
||||
}).
|
||||
|
||||
-record(mt, {
|
||||
filename :: string(),
|
||||
tree :: #naive{},
|
||||
backend = 'naive' :: 'naive'
|
||||
}).
|
||||
|
||||
|
|
@ -1,92 +0,0 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Copyright (c) 2007-2015 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
%% Version 2.0 (the "License"); you may not use this file
|
||||
%% except in compliance with the License. You may obtain
|
||||
%% a copy of the License at
|
||||
%%
|
||||
%% http://www.apache.org/licenses/LICENSE-2.0
|
||||
%%
|
||||
%% Unless required by applicable law or agreed to in writing,
|
||||
%% software distributed under the License is distributed on an
|
||||
%% "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
%% KIND, either express or implied. See the License for the
|
||||
%% specific language governing permissions and limitations
|
||||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-ifndef(MACHI_PROJECTION_HRL).
|
||||
-define(MACHI_PROJECTION_HRL, true).
|
||||
|
||||
-type pv1_consistency_mode() :: 'ap_mode' | 'cp_mode'.
|
||||
-type pv1_chain_name():: atom().
|
||||
-type pv1_csum() :: binary().
|
||||
-type pv1_epoch() :: {pv1_epoch_n(), pv1_csum()}.
|
||||
-type pv1_epoch_n() :: non_neg_integer().
|
||||
-type pv1_server() :: atom().
|
||||
-type pv1_timestamp() :: {non_neg_integer(), non_neg_integer(), non_neg_integer()}.
|
||||
|
||||
-record(p_srvr, {
|
||||
name :: pv1_server(),
|
||||
proto_mod = 'machi_flu1_client' :: atom(), % Module name
|
||||
address :: term(), % Protocol-specific
|
||||
port :: term(), % Protocol-specific
|
||||
props = [] :: list() % proplist for other related info
|
||||
}).
|
||||
|
||||
-record(flap_i, {
|
||||
flap_count :: {term(), term()},
|
||||
all_hosed :: list(),
|
||||
all_flap_counts :: list(),
|
||||
my_unique_prop_count :: non_neg_integer()
|
||||
}).
|
||||
|
||||
-type p_srvr() :: #p_srvr{}.
|
||||
-type p_srvr_dict() :: orddict:orddict().
|
||||
|
||||
-define(DUMMY_PV1_EPOCH, {0,<<0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0>>}).
|
||||
|
||||
%% Kludge for spam gossip. TODO: replace me
|
||||
-define(SPAM_PROJ_EPOCH, ((1 bsl 32) - 7)).
|
||||
|
||||
-record(projection_v1, {
|
||||
epoch_number :: pv1_epoch_n() | ?SPAM_PROJ_EPOCH,
|
||||
epoch_csum :: pv1_csum(),
|
||||
author_server :: pv1_server(),
|
||||
chain_name = ch_not_def_yet :: pv1_chain_name(),
|
||||
all_members :: [pv1_server()],
|
||||
witnesses = [] :: [pv1_server()],
|
||||
creation_time :: pv1_timestamp(),
|
||||
mode = ap_mode :: pv1_consistency_mode(),
|
||||
upi :: [pv1_server()],
|
||||
repairing :: [pv1_server()],
|
||||
down :: [pv1_server()],
|
||||
dbg :: list(), %proplist(), is checksummed
|
||||
dbg2 :: list(), %proplist(), is not checksummed
|
||||
members_dict :: p_srvr_dict()
|
||||
}).
|
||||
|
||||
-define(MACHI_DEFAULT_TCP_PORT, 50000).
|
||||
|
||||
-define(SHA_MAX, (1 bsl (20*8))).
|
||||
|
||||
%% Set a limit to the maximum chain length, so that it's easier to
|
||||
%% create a consistent projection ranking score.
|
||||
-define(MAX_CHAIN_LENGTH, 64).
|
||||
|
||||
-record(chain_def_v1, {
|
||||
name :: atom(), % chain name
|
||||
mode :: pv1_consistency_mode(),
|
||||
full = [] :: [p_srvr()],
|
||||
witnesses = [] :: [p_srvr()],
|
||||
old_full = [] :: [pv1_server()], % guard against some races
|
||||
old_witnesses=[] :: [pv1_server()], % guard against some races
|
||||
local_run = [] :: [pv1_server()], % must be tailored to each machine!
|
||||
local_stop = [] :: [pv1_server()], % must be tailored to each machine!
|
||||
props = [] :: list() % proplist for other related info
|
||||
}).
|
||||
|
||||
-endif. % !MACHI_PROJECTION_HRL
|
||||
|
|
@ -1,31 +0,0 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014-2015 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
%% Version 2.0 (the "License"); you may not use this file
|
||||
%% except in compliance with the License. You may obtain
|
||||
%% a copy of the License at
|
||||
%%
|
||||
%% http://www.apache.org/licenses/LICENSE-2.0
|
||||
%%
|
||||
%% Unless required by applicable law or agreed to in writing,
|
||||
%% software distributed under the License is distributed on an
|
||||
%% "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
%% KIND, either express or implied. See the License for the
|
||||
%% specific language governing permissions and limitations
|
||||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-ifdef(PULSE).
|
||||
-define(V(Fmt, Args), pulse:format(Fmt, Args)).
|
||||
-else. % PULSE
|
||||
-define(V(Fmt, Args), io:format(user, Fmt, Args)).
|
||||
-endif. % PULSE
|
||||
|
||||
-define(D(X), ?V("~s ~p\n", [??X, X])).
|
||||
-define(Dw(X), ?V("~s ~w\n", [??X, X])).
|
||||
|
||||
|
|
@ -1,45 +0,0 @@
|
|||
%% Mandatory: adjust this code path to top of your compiled Machi source distro
|
||||
{code_paths, ["/Users/fritchie/b/src/machi"]}.
|
||||
{driver, machi_basho_bench_driver}.
|
||||
|
||||
%% Chose your maximum rate (per worker proc, see 'concurrent' below)
|
||||
%{mode, {rate,10}}.
|
||||
%{mode, {rate,20}}.
|
||||
{mode, max}.
|
||||
|
||||
%% Runtime & reporting interval
|
||||
{duration, 10}. % minutes
|
||||
{report_interval, 1}. % seconds
|
||||
|
||||
%% Choose your number of worker procs
|
||||
%{concurrent, 1}.
|
||||
{concurrent, 5}.
|
||||
%{concurrent, 10}.
|
||||
|
||||
%% Here's a chain of (up to) length 3, all on localhost
|
||||
%% Note: if any servers are down, and your OS/TCP stack has an
|
||||
%% ICMP response limit such as OS X's "net.inet.icmp.icmplim" setting,
|
||||
%% then if that setting is very low (e.g., OS X's limit is 50), then
|
||||
%% you can have big problems with ICMP/RST responses being delayed and
|
||||
%% interactive *very* badly with your test.
|
||||
%% For OS X, fix using "sudo sysctl -w net.inet.icmp.icmplim=9999"
|
||||
{machi_server_info,
|
||||
[
|
||||
{p_srvr,a,machi_flu1_client,"localhost",4444,[]},
|
||||
{p_srvr,b,machi_flu1_client,"localhost",4445,[]},
|
||||
{p_srvr,c,machi_flu1_client,"localhost",4446,[]}
|
||||
]}.
|
||||
{machi_ets_key_tab_type, set}. % set | ordered_set
|
||||
|
||||
%% Workload-specific definitions follow....
|
||||
|
||||
%% 10 parts 'append' operation + 0 parts anything else = 100% 'append' ops
|
||||
{operations, [{append, 10}]}.
|
||||
|
||||
%% For append, key = Machi file prefix name
|
||||
{key_generator, {to_binstr, "prefix~w", {uniform_int, 30}}}.
|
||||
|
||||
%% Increase size of value_generator_source_size if value_generator is big!!
|
||||
{value_generator_source_size, 2111000}.
|
||||
{value_generator, {fixed_bin, 32768}}. % 32 KB
|
||||
|
||||
|
|
@ -1,47 +0,0 @@
|
|||
%% Mandatory: adjust this code path to top of your compiled Machi source distro
|
||||
{code_paths, ["/Users/fritchie/b/src/machi"]}.
|
||||
{driver, machi_basho_bench_driver}.
|
||||
|
||||
%% Chose your maximum rate (per worker proc, see 'concurrent' below)
|
||||
%{mode, {rate,10}}.
|
||||
%{mode, {rate,20}}.
|
||||
{mode, max}.
|
||||
|
||||
%% Runtime & reporting interval
|
||||
{duration, 10}. % minutes
|
||||
{report_interval, 1}. % seconds
|
||||
|
||||
%% Choose your number of worker procs
|
||||
%{concurrent, 1}.
|
||||
{concurrent, 5}.
|
||||
%{concurrent, 10}.
|
||||
|
||||
%% Here's a chain of (up to) length 3, all on localhost
|
||||
%% Note: if any servers are down, and your OS/TCP stack has an
|
||||
%% ICMP response limit such as OS X's "net.inet.icmp.icmplim" setting,
|
||||
%% then if that setting is very low (e.g., OS X's limit is 50), then
|
||||
%% you can have big problems with ICMP/RST responses being delayed and
|
||||
%% interactive *very* badly with your test.
|
||||
%% For OS X, fix using "sudo sysctl -w net.inet.icmp.icmplim=9999"
|
||||
{machi_server_info,
|
||||
[
|
||||
{p_srvr,a,machi_flu1_client,"localhost",4444,[]},
|
||||
{p_srvr,b,machi_flu1_client,"localhost",4445,[]},
|
||||
{p_srvr,c,machi_flu1_client,"localhost",4446,[]}
|
||||
]}.
|
||||
{machi_ets_key_tab_type, set}. % set | ordered_set
|
||||
|
||||
%% Workload-specific definitions follow....
|
||||
|
||||
%% 10 parts 'read' operation + 0 parts anything else = 100% 'read' ops
|
||||
{operations, [{read, 10}]}.
|
||||
|
||||
%% For read, key = integer index into Machi's chunk ETS table, modulo the
|
||||
%% ETS table size, so a huge number here is OK.
|
||||
{key_generator, {uniform_int, 999999999999}}.
|
||||
|
||||
%% For read, value_generator_* isn't used, so leave these defaults as-is.
|
||||
{value_generator_source_size, 2111000}.
|
||||
{value_generator, {fixed_bin, 32768}}. % 32 KB
|
||||
|
||||
|
||||
|
|
@ -1,56 +0,0 @@
|
|||
#!/bin/sh
|
||||
|
||||
echo "Step: Verify that the required entries in /etc/hosts are present"
|
||||
for i in 1 2 3; do
|
||||
grep machi$i /etc/hosts | egrep -s '^127.0.0.1' > /dev/null 2>&1
|
||||
if [ $? -ne 0 ]; then
|
||||
echo ""
|
||||
echo "'grep -s machi$i' failed. Aborting, sorry."
|
||||
exit 1
|
||||
fi
|
||||
ping -c 1 machi$i > /dev/null 2>&1
|
||||
if [ $? -ne 0 ]; then
|
||||
echo ""
|
||||
echo "Ping attempt on host machi$i failed. Aborting."
|
||||
echo ""
|
||||
ping -c 1 machi$i
|
||||
exit 1
|
||||
fi
|
||||
done
|
||||
|
||||
echo "Step: add a verbose logging option to app.config"
|
||||
for i in 1 2 3; do
|
||||
ed ./dev/dev$i/etc/app.config <<EOF > /dev/null 2>&1
|
||||
/verbose_confirm
|
||||
a
|
||||
{chain_manager_opts, [{private_write_verbose_confirm,true}]},
|
||||
{stability_time, 1},
|
||||
.
|
||||
w
|
||||
q
|
||||
EOF
|
||||
done
|
||||
|
||||
echo "Step: start three three Machi application instances"
|
||||
for i in 1 2 3; do
|
||||
./dev/dev$i/bin/machi start
|
||||
./dev/dev$i/bin/machi ping
|
||||
if [ $? -ne 0 ]; then
|
||||
echo "Sorry, a 'ping' check for instance dev$i failed. Aborting."
|
||||
exit 1
|
||||
fi
|
||||
done
|
||||
|
||||
echo "Step: configure one chain to start a Humming Consensus group with three members"
|
||||
|
||||
# Note: $CWD of each Machi proc is two levels below the source code root dir.
|
||||
LIFECYCLE000=../../priv/quick-admin-examples/demo-000
|
||||
for i in 3 2 1; do
|
||||
./dev/dev$i/bin/machi-admin quick-admin-apply $LIFECYCLE000 machi$i
|
||||
if [ $? -ne 0 ]; then
|
||||
echo "Sorry, 'machi-admin quick-admin-apply failed' on machi$i. Aborting."
|
||||
exit 1
|
||||
fi
|
||||
done
|
||||
|
||||
exit 0
|
||||
93
priv/humming-consensus-demo.vagrant/Vagrantfile
vendored
|
|
@ -1,93 +0,0 @@
|
|||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
|
||||
# All Vagrant configuration is done below. The "2" in Vagrant.configure
|
||||
# configures the configuration version (we support older styles for
|
||||
# backwards compatibility). Please don't change it unless you know what
|
||||
# you're doing.
|
||||
Vagrant.configure(2) do |config|
|
||||
# The most common configuration options are documented and commented below.
|
||||
# For a complete reference, please see the online documentation at
|
||||
# https://docs.vagrantup.com.
|
||||
|
||||
# Every Vagrant development environment requires a box. You can search for
|
||||
# boxes at https://atlas.hashicorp.com/search.
|
||||
# If this Vagrant box has not been downloaded before (e.g. using "vagrant box add"),
|
||||
# then Vagrant will automatically download the VM image from HashiCorp.
|
||||
config.vm.box = "hashicorp/precise64"
|
||||
# If using a FreeBSD box, Bash may not be installed.
|
||||
# Use the config.ssh.shell setting to specify an alternate shell.
|
||||
# Note, however, that any code in the 'config.vm.provision' section
|
||||
# would then have to use this shell's syntax!
|
||||
# config.ssh.shell = "/bin/csh -l"
|
||||
|
||||
# Disable automatic box update checking. If you disable this, then
|
||||
# boxes will only be checked for updates when the user runs
|
||||
# `vagrant box outdated`. This is not recommended.
|
||||
# config.vm.box_check_update = false
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine. In the example below,
|
||||
# accessing "localhost:8080" will access port 80 on the guest machine.
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
|
||||
# Create a private network, which allows host-only access to the machine
|
||||
# using a specific IP.
|
||||
# config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
# Create a public network, which generally matched to bridged network.
|
||||
# Bridged networks make the machine appear as another physical device on
|
||||
# your network.
|
||||
# config.vm.network "public_network"
|
||||
|
||||
# Share an additional folder to the guest VM. The first argument is
|
||||
# the path on the host to the actual folder. The second argument is
|
||||
# the path on the guest to mount the folder. And the optional third
|
||||
# argument is a set of non-required options.
|
||||
# config.vm.synced_folder "../data", "/vagrant_data"
|
||||
|
||||
# Provider-specific configuration so you can fine-tune various
|
||||
# backing providers for Vagrant. These expose provider-specific options.
|
||||
# Example for VirtualBox:
|
||||
#
|
||||
config.vm.provider "virtualbox" do |vb|
|
||||
# Display the VirtualBox GUI when booting the machine
|
||||
# vb.gui = true
|
||||
|
||||
# Customize the amount of memory on the VM:
|
||||
vb.memory = "512"
|
||||
end
|
||||
#
|
||||
# View the documentation for the provider you are using for more
|
||||
# information on available options.
|
||||
|
||||
# Define a Vagrant Push strategy for pushing to Atlas. Other push strategies
|
||||
# such as FTP and Heroku are also available. See the documentation at
|
||||
# https://docs.vagrantup.com/v2/push/atlas.html for more information.
|
||||
# config.push.define "atlas" do |push|
|
||||
# push.app = "YOUR_ATLAS_USERNAME/YOUR_APPLICATION_NAME"
|
||||
# end
|
||||
|
||||
# Enable provisioning with a shell script. Additional provisioners such as
|
||||
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
|
||||
# documentation for more information about their specific syntax and use.
|
||||
config.vm.provision "shell", inline: <<-SHELL
|
||||
# Install prerequsites
|
||||
# Support here for FreeBSD is experimental
|
||||
apt-get update ; sudo apt-get install -y git sudo rsync ; # Ubuntu Linux
|
||||
env ASSUME_ALWAYS_YES=yes pkg install -f git sudo rsync ; # FreeBSD 10
|
||||
|
||||
# Install dependent packages, using slf-configurator
|
||||
git clone https://github.com/slfritchie/slf-configurator.git
|
||||
chown -R vagrant ./slf-configurator
|
||||
(cd slf-configurator ; sudo sh -x ./ALL.sh)
|
||||
echo 'export PATH=${PATH}:/usr/local/erlang/17.5/bin' >> ~vagrant/.bashrc
|
||||
export PATH=${PATH}:/usr/local/erlang/17.5/bin
|
||||
## echo 'set path = ( $path /usr/local/erlang/17.5/bin )' >> ~vagrant/.cshrc
|
||||
## setenv PATH /usr/local/erlang/17.5/bin:$PATH
|
||||
|
||||
git clone https://github.com/basho/machi.git
|
||||
(cd machi ; git checkout master ; make && make test )
|
||||
chown -R vagrant ./machi
|
||||
SHELL
|
||||
end
|
||||
|
|
@ -1,81 +0,0 @@
|
|||
#!/usr/bin/perl
|
||||
|
||||
$input = shift;
|
||||
$tmp1 = "/tmp/my-tmp.1.$$";
|
||||
$tmp2 = "/tmp/my-tmp.2.$$";
|
||||
$l1 = 0;
|
||||
$l2 = 0;
|
||||
$l3 = 0;
|
||||
|
||||
open(I, $input);
|
||||
open(T1, "> $tmp1");
|
||||
open(T2, "> $tmp2");
|
||||
|
||||
while (<I>) {
|
||||
if (/^##*/) {
|
||||
$line = $_;
|
||||
chomp;
|
||||
@a = split;
|
||||
$count = length($a[0]) - 2;
|
||||
if ($count >= 0) {
|
||||
if ($count == 0) {
|
||||
$l1++;
|
||||
$l2 = 0;
|
||||
$l3 = 0;
|
||||
$label = "$l1"
|
||||
}
|
||||
if ($count == 1) {
|
||||
$l2++;
|
||||
$l3 = 0;
|
||||
$label = "$l1.$l2"
|
||||
}
|
||||
if ($count == 2) {
|
||||
$l3++;
|
||||
$label = "$l1.$l2.$l3"
|
||||
}
|
||||
$indent = " " x ($count * 4);
|
||||
s/^#*\s*[0-9. ]*//;
|
||||
$anchor = "n$label";
|
||||
printf T1 "%s+ [%s. %s](#%s)\n", $indent, $label, $_, $anchor;
|
||||
printf T2 "<a name=\"%s\">\n", $anchor;
|
||||
$line =~ s/(#+)\s*[0-9. ]*/$1 $label. /;
|
||||
print T2 $line;
|
||||
} else {
|
||||
print T2 $_, "\n";
|
||||
}
|
||||
} else {
|
||||
next if /^<a name="n[0-9.]+">/;
|
||||
print T2 $_;
|
||||
}
|
||||
}
|
||||
|
||||
close(I);
|
||||
close(T1);
|
||||
close(T2);
|
||||
open(T2, $tmp2);
|
||||
|
||||
while (<T2>) {
|
||||
if (/<!\-\- OUTLINE \-\->/) {
|
||||
print;
|
||||
print "\n";
|
||||
open(T1, $tmp1);
|
||||
while (<T1>) {
|
||||
print;
|
||||
}
|
||||
close(T1);
|
||||
while (<T2>) {
|
||||
if (/<!\-\- ENDOUTLINE \-\->/) {
|
||||
print "\n";
|
||||
print;
|
||||
last;
|
||||
}
|
||||
}
|
||||
} else {
|
||||
print;
|
||||
}
|
||||
}
|
||||
close(T2);
|
||||
|
||||
unlink($tmp1);
|
||||
unlink($tmp2);
|
||||
exit(0);
|
||||
|
|
@ -1 +0,0 @@
|
|||
{host, "localhost", []}.
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
{flu,f1,"localhost",20401,[]}.
|
||||
{flu,f2,"localhost",20402,[]}.
|
||||
{flu,f3,"localhost",20403,[]}.
|
||||
{chain,c1,[f1,f2,f3],[]}.
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
{flu,f4,"localhost",20404,[]}.
|
||||
{flu,f5,"localhost",20405,[]}.
|
||||
{flu,f6,"localhost",20406,[]}.
|
||||
{chain,c2,[f4,f5,f6],[]}.
|
||||
|
|
@ -1,7 +0,0 @@
|
|||
{host, "machi1", []}.
|
||||
{host, "machi2", []}.
|
||||
{host, "machi3", []}.
|
||||
{flu,f1,"machi1",20401,[]}.
|
||||
{flu,f2,"machi2",20402,[]}.
|
||||
{flu,f3,"machi3",20403,[]}.
|
||||
{chain,c1,[f1,f2,f3],[]}.
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
#!/bin/sh
|
||||
|
||||
if [ "${TRAVIS_PULL_REQUEST}" = "false" ]; then
|
||||
echo '$TRAVIS_PULL_REQUEST is false, skipping tests'
|
||||
exit 0
|
||||
else
|
||||
echo '$TRAVIS_PULL_REQUEST is not false ($TRAVIS_PULL_REQUEST), running tests'
|
||||
make test
|
||||
make dialyzer
|
||||
fi
|
||||
|
|
@ -1,64 +0,0 @@
|
|||
# Prototype directory
|
||||
|
||||
The contents of the `prototype` directory is the result of
|
||||
consolidating several small & independent repos. Originally, each
|
||||
small was a separate prototype/quick hack for experimentation
|
||||
purposes. The code is preserved here for use as:
|
||||
|
||||
* Examples of what not to do ... the code **is** a bit ugly, after
|
||||
all. <tt>^_^</tt>
|
||||
* Some examples of what to do when prototyping in Erlang. For
|
||||
example, "Let it crash" style coding is so nice to hack on quickly.
|
||||
* Some code might actually be reusable, as-is or after some
|
||||
refactoring.
|
||||
|
||||
The prototype code here is not meant for long-term use or
|
||||
maintenance. We are unlikely to accept changes/pull requests for adding
|
||||
large new features or to build full Erlang/OTP applications using this
|
||||
code only.
|
||||
|
||||
However, pull requests for small changes, such as support for
|
||||
newer Erlang versions (e.g., Erlang 17), will be gladly accepted.
|
||||
We will also accept fixes for bugs in the test code.
|
||||
|
||||
## The corfurl prototype
|
||||
|
||||
The `corfurl` code is a mostly-complete complete implementation of the
|
||||
CORFU server & client specification. More details on the papers about
|
||||
CORFU are mentioned in the `corfurl/docs/corfurl.md` file.
|
||||
|
||||
This code contains a QuickCheck + PULSE test. If you wish to use it,
|
||||
please note the usage instructions and restrictions mentioned in the
|
||||
`README.md` file.
|
||||
|
||||
## The demo-day-hack prototype
|
||||
|
||||
This code in the `demo-day-hack` is expected to remain static,
|
||||
as an archive of past "Demo Day" work.
|
||||
|
||||
See the top-level README.md file for details on work to move
|
||||
much of this code out of the `prototype` directory and into real
|
||||
use elsewhere in the repo.
|
||||
|
||||
## The tango prototype
|
||||
|
||||
A quick & dirty prototype of Tango on top of the `prototype/corfurl`
|
||||
CORFU implementation. The implementation is powerful enough (barely)
|
||||
to run concurrently on multiple Erlang nodes. See its `README.md`
|
||||
file for limitations, TODO items, etc.
|
||||
|
||||
## The chain-manager prototype
|
||||
|
||||
This is a very early experiment to try to create a distributed "rough
|
||||
consensus" algorithm that is sufficient & safe for managing the order
|
||||
of a Chain Replication chain, its members, and its chain order.
|
||||
|
||||
Unlike the other code projects in this repository's `prototype`
|
||||
directory, the chain management code is still under active
|
||||
development. However, the chain manager code here in the `prototype`
|
||||
subdirectory will remain frozen in time.
|
||||
|
||||
Efforts in April 2015 have moved the chain manager code to the "top level"
|
||||
of the repository. All new work is being merged weekly into the `master`
|
||||
branch, see `src/machi_chain_manager1.erl` and related source at the top of
|
||||
the repo.
|
||||
1
prototype/chain-manager/.gitignore
vendored
|
|
@ -6,4 +6,3 @@ deps
|
|||
ebin/*.beam
|
||||
ebin/*.app
|
||||
erl_crash.dump
|
||||
RUNLOG*
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ deps:
|
|||
$(REBAR_BIN) get-deps
|
||||
|
||||
clean:
|
||||
$(REBAR_BIN) -r clean
|
||||
$(REBAR_BIN) clean
|
||||
|
||||
test: deps compile eunit
|
||||
|
||||
|
|
@ -23,7 +23,7 @@ eunit:
|
|||
|
||||
pulse: compile
|
||||
env USE_PULSE=1 $(REBAR_BIN) skip_deps=true clean compile
|
||||
env USE_PULSE=1 $(REBAR_BIN) skip_deps=true -D PULSE -v eunit
|
||||
env USE_PULSE=1 $(REBAR_BIN) -v skip_deps=true -D PULSE eunit
|
||||
|
||||
CONC_ARGS = --pz ./.eunit --treat_as_normal shutdown --after_timeout 1000
|
||||
|
||||
|
|
@ -41,15 +41,3 @@ concuerror: deps compile
|
|||
concuerror -m machi_flu0_test -t proj_store_test $(CONC_ARGS)
|
||||
concuerror -m machi_flu0_test -t wedge_test $(CONC_ARGS)
|
||||
concuerror -m machi_flu0_test -t proj0_test $(CONC_ARGS)
|
||||
|
||||
APPS = kernel stdlib sasl erts ssl compiler eunit
|
||||
PLT = $(HOME)/.chmgr_dialyzer_plt
|
||||
|
||||
build_plt: deps compile
|
||||
dialyzer --build_plt --output_plt $(PLT) --apps $(APPS) deps/*/ebin
|
||||
|
||||
dialyzer: deps compile
|
||||
dialyzer -Wno_return --plt $(PLT) ebin
|
||||
|
||||
clean_plt:
|
||||
rm $(PLT)
|
||||
|
|
|
|||
|
|
@ -1,202 +0,0 @@
|
|||
# The chain manager prototype
|
||||
|
||||
This is a very early experiment to try to create a distributed "rough
|
||||
consensus" algorithm that is sufficient & safe for managing the order
|
||||
of a Chain Replication chain, its members, and its chain order. A
|
||||
name hasn't been chosen yet, though the following are contenders:
|
||||
|
||||
* chain self-management
|
||||
* rough consensus
|
||||
* humming consensus
|
||||
* foggy consensus
|
||||
|
||||
## Code status: active!
|
||||
|
||||
Unlike the other code projects in this repository's `prototype`
|
||||
directory, the chain management code is still under active
|
||||
development. It is quite likely (as of early March 2015) that this
|
||||
code will be robust enough to move to the "real" Machi code base soon.
|
||||
|
||||
The most up-to-date documentation for this prototype will **not** be
|
||||
found in this subdirectory. Rather, please see the `doc` directory at
|
||||
the top of the Machi source repository.
|
||||
|
||||
## Testing, testing, testing
|
||||
|
||||
It's important to implement any Chain Replication chain manager as
|
||||
close to 100% bug-free as possible. Any bug can introduce the
|
||||
possibility of data loss, which is something we must avoid.
|
||||
Therefore, we will spend a large amount of effort to use as many
|
||||
robust testing tools and methods as feasible to test this code.
|
||||
|
||||
* [Concuerror](http://concuerror.com), a DPOR-based full state space
|
||||
exploration tool. Some preliminary Concuerror tests can be found in the
|
||||
`test/machi_flu0_test.erl` module.
|
||||
* [QuickCheck](http://www.quviq.com/products/erlang-quickcheck/), a
|
||||
property-based testing tool for Erlang. QuickCheck doesn't provide
|
||||
the reassurance of 100% state exploration, but it proven quite
|
||||
effective at Basho for finding numerous subtle bugs.
|
||||
* Automatic simulation of arbitrary network partition failures. This
|
||||
code is already in progress and is used, for example, by the
|
||||
`test/machi_chain_manager1_test.erl` module.
|
||||
* TLA+ (future work), to try to create a rigorous model of the
|
||||
algorithm and its behavior
|
||||
|
||||
If you'd like to work on additional testing of this component, please
|
||||
[open a new GitHub Issue ticket](https://github.com/basho/machi) with
|
||||
any questions you have. Or just open a GitHub pull request. <tt>^_^</tt>
|
||||
|
||||
## Compilation & unit testing
|
||||
|
||||
Use `make` and `make test`. Note that the Makefile assumes that the
|
||||
`rebar` utility is available somewhere in your path.
|
||||
|
||||
Tested using Erlang/OTP R16B and Erlang/OTP 17, both on OS X.
|
||||
|
||||
If you wish to run the PULSE test in
|
||||
`test/machi_chain_manager1_pulse.erl` module, you must use Erlang
|
||||
R16B and Quviq QuickCheck 1.30.2 -- there is a known problem with
|
||||
QuickCheck 1.33.2, sorry! Also, please note that a single iteration
|
||||
of a PULSE test case in this model can run for 10s of seconds!
|
||||
|
||||
Otherwise, it ought to "just work" on other versions of Erlang and on other OS
|
||||
platforms, but sorry, I haven't tested it.
|
||||
|
||||
### Testing with simulated network partitions
|
||||
|
||||
See the `doc/chain-self-management-sketch.org` file for details of how
|
||||
the simulator works.
|
||||
|
||||
In summary, the simulator tries to emulate the effect of arbitrary
|
||||
asymmetric network partitions. For example, for two simulated nodes A
|
||||
and B, it's possible to have node A send messages to B, but B cannot
|
||||
send messages to A.
|
||||
|
||||
This kind of one-way message passing is nearly impossible do with
|
||||
distributed Erlang, because disterl uses TCP. If a network partition
|
||||
happens at ISO Layer 2 (for example, due to a bad Ethernet cable that
|
||||
has a faulty receive wire), the entire TCP connection will hang rather
|
||||
than deliver disterl messages in only one direction.
|
||||
|
||||
### Testing simulated data "repair"
|
||||
|
||||
In the Machi documentation, "repair" is a re-syncronization of data
|
||||
between the UPI members of the chain (see below) and members which
|
||||
have been down/partitioned/gone-to-Hawaii-for-vacation for some period
|
||||
of time and may have state which is out-of-sync with the rest of the
|
||||
active-and-running-and-fully-in-sync chain members.
|
||||
|
||||
A rough-and-inaccurate-but-useful summary of state transitions are:
|
||||
|
||||
down -> repair eligible -> repairing started -> repairing finished -> upi
|
||||
|
||||
* Any state can transition back to 'down'
|
||||
* Repair interruptions might trigger a transition to
|
||||
'repair eligible instead of 'down'.
|
||||
* UPI = Update Propagation Invariant (per the original
|
||||
Chain Replication paper) preserving members.
|
||||
|
||||
I.e., The state stored by any UPI member is fully
|
||||
in sync with all other UPI chain members, except
|
||||
for new updates which are being processed by Chain
|
||||
Replication at a particular instant in time.
|
||||
|
||||
In both the PULSE and `convergence_demo*()` tests, there is a
|
||||
simulated time when a FLU's repair state goes from "repair started" to
|
||||
"repair finished", which means that the FLU-under-repair is now
|
||||
eligible to join the UPI portion of the chain as a fully-sync'ed
|
||||
member of the chain. The simulation is based on a simple "coin
|
||||
flip"-style random choice.
|
||||
|
||||
The simulator framework is simulating repair failures when a network
|
||||
partition is detected with the repair destination FLU. In the "real
|
||||
world", other kinds of failure could also interrupt the repair
|
||||
process.
|
||||
|
||||
### The PULSE test in machi_chain_manager1_test.erl
|
||||
|
||||
As mentioned above, this test is quite slow: it can take many dozens
|
||||
of seconds to execute a single test case. However, the test really is using
|
||||
PULSE to play strange games with Erlang process scheduling.
|
||||
|
||||
Unfortnately, the PULSE framework is very slow for this test. We'd
|
||||
like something better, so I wrote the
|
||||
`machi_chain_manager1_test:convergence_demo_test()` test to use most
|
||||
of the network partition simulator to try to run many more partition
|
||||
scenarios in the same amount of time.
|
||||
|
||||
### machi_chain_manager1_test:convergence_demo1()
|
||||
|
||||
This function is intended both as a demo and as a possible
|
||||
fully-automated sanity checking function (it will throw an exception
|
||||
when a model failure happens). It's purpose is to "go faster" than
|
||||
the PULSE test describe above. It meets this purpose handily.
|
||||
However, it doesn't give quite as much confidence as PULSE does that
|
||||
Erlang process scheduling cannot somehow break algorithm running
|
||||
inside the simulator.
|
||||
|
||||
To execute:
|
||||
|
||||
make test
|
||||
erl -pz ./.eunit deps/*/ebin
|
||||
ok = machi_chain_manager1_test:convergence_demo1().
|
||||
|
||||
In summary:
|
||||
|
||||
* Set up four FLUs, `[a,b,c,d]`, to be used for the test
|
||||
* Set up a set of random asymmetric network partitions, based on a
|
||||
'seed' for a pseudo-random number generator. Each call to the
|
||||
partition simulator may yield a different partition scenario ... so
|
||||
the simulated environment is very unstable.
|
||||
* Run the algorithm for a while so that it has witnessed the partition
|
||||
instability for a long time.
|
||||
* Set the partitions definition to a fixed `[{a,b}]`, meaning that FLU `a`
|
||||
cannot send messages to FLU `b`, but all other communication
|
||||
(including messages from `b -> a`) works correctly.
|
||||
* Run the algorithm, wait for everyone to settle on rough consensus.
|
||||
* Set the partition definition to wildly random again.
|
||||
* Run the algorithm for a while so that it has witnessed the partition
|
||||
instability for a long time.
|
||||
* Set the partitions definition to a fixed `[{a,c}]`.
|
||||
* Run the algorithm, wait for everyone to settle on rough consensus.
|
||||
* Set the partitions definition to a fixed `[]`, i.e., there are no
|
||||
network partitions at all.
|
||||
* Run the algorithm, wait for everyone to settle on a **unanimous value**
|
||||
of some ordering of all four FLUs.
|
||||
|
||||
To try to understand the simulator's output, let's look at some examples:
|
||||
|
||||
20:12:59.120 c uses: [{epoch,1023},{author,d},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{20,12,59}}}]}]
|
||||
|
||||
So, server C has decided the following, as far as it can tell:
|
||||
|
||||
* Epoch 1023 is the latest epoch
|
||||
* There's already a projection written to the "public" projection stores by author server D.
|
||||
* C has decided that D's proposal is the best out of all that C can see in the "public" projection stores plus its own calculation
|
||||
* The UPI/active chain order is: C (head), B, D, A (tail).
|
||||
* No servers are under repair
|
||||
* No servers are down.
|
||||
* Then there's some other debugging/status info in the 'd' and 'd2' data attributes
|
||||
* The 'react' to outside stimulus triggered the author's action
|
||||
* The 'ps' says that there are no network partitions *inside the simulator* (yes, that's cheating, but sooo useful for debugging)
|
||||
* All 4 nodes are believed up
|
||||
* (aside) The 'ps' partition list describes nodes that cannot talk to each other.
|
||||
* For easier debugging/visualization, the 'network_islands' converts 'ps' into lists of "islands" where nodes can talk to each other.
|
||||
* So 'network_islands' says that A&B&C&D can all message each other, as far as author D understands at the moment.
|
||||
* Hooray, the decision was made at 20:12:59 on 2015-03-03.
|
||||
|
||||
So, let's see a tiny bit of what happens when there's an asymmetric
|
||||
network partition. Note that no consensus has yet been reached:
|
||||
participants are still churning/uncertain.
|
||||
|
||||
20:12:48.420 a uses: [{epoch,1011},{author,a},{upi,[a,b]},{repair,[d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{20,12,48}}}]}]
|
||||
20:12:48.811 d uses: [{epoch,1012},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{20,12,48}}}]}]
|
||||
{FLAP: a flaps 5}!
|
||||
|
||||
* The simulator says that the one-way partition definition is `{ps,[{a,c}]}`. This is authoritative info from the simulator. The algorithm *does not* use this source of info, however!
|
||||
* Server A believes that `{nodes_up,[a,b,d]}`. A is a victim of the simulator's partitioning, so this belief is correct relative to A.
|
||||
* Server D believes that `{nodes_up,[a,b,c,d]}`. D doesn't have any simulator partition, so this belief is also correct relative to D.
|
||||
* A participant has now noticed that server A has "flapped": it has
|
||||
proposed the same proposal at least 5 times in a row. This kind of
|
||||
pattern is indicative of an asymmetric partition ... which is indeed
|
||||
what is happening at this moment.
|
||||
431
prototype/chain-manager/RUNLOG
Normal file
|
|
@ -0,0 +1,431 @@
|
|||
/Users/fritchie/b/src/rebar/rebar get-deps
|
||||
==> goldrush (get-deps)
|
||||
==> lager (get-deps)
|
||||
==> chain-manager (get-deps)
|
||||
/Users/fritchie/b/src/rebar/rebar compile
|
||||
==> goldrush (compile)
|
||||
Compiled src/gre.erl
|
||||
Compiled src/gr_param_sup.erl
|
||||
Compiled src/gr_sup.erl
|
||||
Compiled src/gr_manager_sup.erl
|
||||
Compiled src/gr_counter_sup.erl
|
||||
Compiled src/gr_manager.erl
|
||||
Compiled src/gr_context.erl
|
||||
Compiled src/gr_app.erl
|
||||
Compiled src/gr_param.erl
|
||||
Compiled src/glc_ops.erl
|
||||
Compiled src/gr_counter.erl
|
||||
Compiled src/glc.erl
|
||||
Compiled src/glc_lib.erl
|
||||
Compiled src/glc_code.erl
|
||||
==> lager (compile)
|
||||
Compiled src/lager_util.erl
|
||||
Compiled src/lager_transform.erl
|
||||
Compiled src/lager_sup.erl
|
||||
Compiled src/lager_msg.erl
|
||||
Compiled src/lager_handler_watcher_sup.erl
|
||||
Compiled src/lager_handler_watcher.erl
|
||||
Compiled src/lager_stdlib.erl
|
||||
Compiled src/lager_trunc_io.erl
|
||||
Compiled src/lager_default_formatter.erl
|
||||
Compiled src/lager_format.erl
|
||||
Compiled src/lager_crash_log.erl
|
||||
Compiled src/lager_console_backend.erl
|
||||
Compiled src/lager_file_backend.erl
|
||||
Compiled src/lager_config.erl
|
||||
Compiled src/lager_backend_throttle.erl
|
||||
Compiled src/lager_app.erl
|
||||
Compiled src/lager.erl
|
||||
Compiled src/error_logger_lager_h.erl
|
||||
==> chain-manager (compile)
|
||||
Compiled src/machi_util.erl
|
||||
Compiled src/machi_flu0.erl
|
||||
Compiled src/machi_chain_manager0.erl
|
||||
Compiled src/machi_chain_manager1.erl
|
||||
/Users/fritchie/b/src/rebar/rebar -v skip_deps=true eunit
|
||||
INFO: Looking for lager-2.0.1 ; found lager-2.0.1 at /Users/fritchie/b/src/machi/prototype/chain-manager/deps/lager
|
||||
INFO: Looking for lager-2.0.1 ; found lager-2.0.1 at /Users/fritchie/b/src/machi/prototype/chain-manager/deps/lager
|
||||
INFO: Looking for goldrush-.* ; found goldrush-0.1.5 at /Users/fritchie/b/src/machi/prototype/chain-manager/deps/goldrush
|
||||
INFO: Looking for goldrush-.* ; found goldrush-0.1.5 at /Users/fritchie/b/src/machi/prototype/chain-manager/deps/goldrush
|
||||
==> chain-manager (eunit)
|
||||
INFO: sh info:
|
||||
cwd: "/Users/fritchie/b/src/machi/prototype/chain-manager"
|
||||
cmd: cp -R src/machi_util.erl src/machi_flu0.erl src/machi_chain_manager1.erl src/machi_chain_manager0.erl test/pulse_util/lamport_clock.erl test/pulse_util/handle_errors.erl test/pulse_util/event_logger.erl test/machi_util_test.erl test/machi_partition_simulator.erl test/machi_flu0_test.erl test/machi_chain_manager1_test.erl test/machi_chain_manager1_pulse.erl test/machi_chain_manager0_test.erl ".eunit"
|
||||
Compiled src/machi_flu0.erl
|
||||
Compiled src/machi_util.erl
|
||||
Compiled test/pulse_util/lamport_clock.erl
|
||||
Compiled test/pulse_util/handle_errors.erl
|
||||
Compiled src/machi_chain_manager0.erl
|
||||
Compiled test/pulse_util/event_logger.erl
|
||||
Compiled test/machi_partition_simulator.erl
|
||||
Compiled test/machi_util_test.erl
|
||||
Compiled test/machi_flu0_test.erl
|
||||
Compiled test/machi_chain_manager1_pulse.erl
|
||||
Compiled test/machi_chain_manager1_test.erl
|
||||
Compiled src/machi_chain_manager1.erl
|
||||
Compiled test/machi_chain_manager0_test.erl
|
||||
======================== EUnit ========================
|
||||
machi_util_test: repair_merge_test_ (module 'machi_util_test')...............................................................................................................................................................................................................................................................................................................
|
||||
OK, passed 300 tests
|
||||
[1.733 s] ok
|
||||
module 'machi_util'
|
||||
module 'machi_partition_simulator'
|
||||
module 'machi_flu0_test'
|
||||
machi_flu0_test: repair_status_test...[0.002 s] ok
|
||||
machi_flu0_test: concuerror1_test...ok
|
||||
machi_flu0_test: concuerror2_test...ok
|
||||
machi_flu0_test: concuerror3_test...ok
|
||||
machi_flu0_test: concuerror4_test...ok
|
||||
machi_flu0_test: proj_store_test...ok
|
||||
machi_flu0_test: wedge_test...ok
|
||||
machi_flu0_test: proj0_test...[0.001 s] ok
|
||||
[done in 0.026 s]
|
||||
module 'machi_flu0'
|
||||
module 'machi_chain_manager1_test'
|
||||
machi_chain_manager1_test: smoke0_test...[{epoch,1},{author,a},{upi,[a,b,c]},{repair,[]},{down,[]},{d,[{author_proc,call},{ps,[]},{nodes_up,[a,b,c]}]},{d2,[]}]
|
||||
[{epoch,1},{author,a},{upi,[a]},{repair,[]},{down,[b,c]},{d,[{author_proc,call},{ps,[{a,b},{c,a},{b,c},{c,b}]},{nodes_up,[a]}]},{d2,[]}]
|
||||
[{epoch,1},{author,a},{upi,[a,b]},{repair,[]},{down,[c]},{d,[{author_proc,call},{ps,[{c,a},{b,c}]},{nodes_up,[a,b]}]},{d2,[]}]
|
||||
[{epoch,1},{author,a},{upi,[a,b]},{repair,[]},{down,[c]},{d,[{author_proc,call},{ps,[{c,a},{b,c}]},{nodes_up,[a,b]}]},{d2,[]}]
|
||||
[{epoch,1},{author,a},{upi,[a]},{repair,[]},{down,[b,c]},{d,[{author_proc,call},{ps,[{a,b},{b,a},{a,c},{c,a},{b,c}]},{nodes_up,[a]}]},{d2,[]}]
|
||||
[0.003 s] ok
|
||||
machi_chain_manager1_test: smoke1_test...[0.001 s] ok
|
||||
machi_chain_manager1_test: nonunanimous_setup_and_fix_test...x x
|
||||
_XX {not_unanimous,{projection,1,<<110,253,187,8,20,172,231,72,56,72,97,162,22,0,234,37,105,166,11,10>>,[a,b],[a],{1425,368983,392344},b,[b],[],[{hackhack,103}],[]},[{unanimous_flus,[b]},{not_unanimous_flus,[{projection,1,<<125,66,48,143,209,3,150,235,225,93,216,21,70,165,243,106,106,243,105,176>>,[a,b],[b],{1425,368983,392326},a,[a],[],[{hackhack,100}],[]}]},{all_members_replied,true}]}
|
||||
[0.001 s] ok
|
||||
machi_chain_manager1_test: convergence_demo_test_...16:49:43.396 a uses: [{epoch,1},{author,a},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,call},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
XX1 1
|
||||
16:49:43.396 b uses: [{epoch,1},{author,a},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,call},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.396 c uses: [{epoch,1},{author,a},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,call},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
QQ unanimous
|
||||
? MGR : make_projection_summary ( QQP2 ) [{epoch,1},{author,a},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,call},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[]}]
|
||||
QQE2 [{unanimous_flus,[a,b,c,d]},
|
||||
{not_unanimous_flus,[]},
|
||||
{all_members_replied,true}]
|
||||
16:49:43.397 d uses: [{epoch,1},{author,a},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,call},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.398 c uses: [{epoch,4},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.399 d uses: [{epoch,10},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{d,a},{b,c},{b,d},{d,b},{c,d}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.401 d uses: [{epoch,19},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.403 d uses: [{epoch,26},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.404 d uses: [{epoch,28},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.405 d uses: [{epoch,34},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{b,a},{a,c},{c,a},{a,d},{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.406 d uses: [{epoch,38},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.408 d uses: [{epoch,45},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.411 d uses: [{epoch,63},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.412 d uses: [{epoch,65},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.414 d uses: [{epoch,71},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.417 d uses: [{epoch,85},{author,d},{upi,[d]},{repair,[a,c]},{down,[b]},{d,[{author_proc,react},{ps,[{d,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.418 d uses: [{epoch,87},{author,d},{upi,[d]},{repair,[a,c,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.421 d uses: [{epoch,98},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.423 d uses: [{epoch,104},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.424 d uses: [{epoch,107},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.425 d uses: [{epoch,110},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.426 d uses: [{epoch,113},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.426 d uses: [{epoch,116},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{a,d},{c,b},{b,d},{d,b},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.427 d uses: [{epoch,118},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{c,a},{a,d},{d,a},{b,c},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.428 d uses: [{epoch,121},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.428 d uses: [{epoch,123},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{b,a},{a,d},{b,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.430 d uses: [{epoch,129},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.433 d uses: [{epoch,139},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.436 d uses: [{epoch,149},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.503 c uses: [{epoch,149},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.506 b uses: [{epoch,153},{author,b},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.507 b uses: [{epoch,157},{author,b},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.508 b uses: [{epoch,161},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.509 b uses: [{epoch,166},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.510 b uses: [{epoch,170},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{c,a},{a,d},{d,a},{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.513 b uses: [{epoch,181},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.515 b uses: [{epoch,184},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.516 b uses: [{epoch,187},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.516 b uses: [{epoch,189},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{b,a},{c,a},{a,d},{d,a},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.517 b uses: [{epoch,192},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.518 b uses: [{epoch,196},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.520 b uses: [{epoch,200},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.521 b uses: [{epoch,202},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.523 b uses: [{epoch,209},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.524 b uses: [{epoch,211},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.526 b uses: [{epoch,220},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.528 b uses: [{epoch,225},{author,b},{upi,[b]},{repair,[c]},{down,[a,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{a,d},{d,a},{b,d},{d,b},{c,d}]},{nodes_up,[b,c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.529 b uses: [{epoch,228},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{a,d},{b,c},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.530 b uses: [{epoch,232},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{c,a},{a,d},{d,a},{c,b},{b,d},{d,b}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.531 b uses: [{epoch,235},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.534 b uses: [{epoch,243},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{d,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.563 c uses: [{epoch,243},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{d,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.563 c uses: [{epoch,245},{author,c},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.567 c uses: [{epoch,261},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.567 c uses: [{epoch,263},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.568 c uses: [{epoch,266},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{b,c},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.570 c uses: [{epoch,273},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.571 c uses: [{epoch,279},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.573 c uses: [{epoch,284},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.573 c uses: [{epoch,286},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.575 c uses: [{epoch,294},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.576 c uses: [{epoch,296},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{b,a},{a,c},{c,a},{d,a},{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.576 c uses: [{epoch,299},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.579 c uses: [{epoch,311},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.580 c uses: [{epoch,314},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.582 c uses: [{epoch,322},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{b,a},{c,a},{a,d},{d,a},{b,c},{c,b},{d,b},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.583 c uses: [{epoch,325},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.583 c uses: [{epoch,327},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{c,a},{c,b},{c,d}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.631 a uses: [{epoch,329},{author,a},{upi,[a,b,c,d]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.633 a uses: [{epoch,338},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{d,a},{c,b},{b,d},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.635 a uses: [{epoch,344},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.635 a uses: [{epoch,347},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.636 a uses: [{epoch,349},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.636 a uses: [{epoch,351},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{c,a},{a,d},{d,b},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.637 a uses: [{epoch,354},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{c,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.639 a uses: [{epoch,362},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.640 a uses: [{epoch,365},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.641 a uses: [{epoch,368},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{d,a},{b,d},{d,b},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.642 a uses: [{epoch,372},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.642 a uses: [{epoch,374},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.643 a uses: [{epoch,376},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{b,c},{c,b},{b,d},{d,b},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.644 a uses: [{epoch,380},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{b,a},{c,a},{d,a},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.644 a uses: [{epoch,382},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{c,a},{a,d},{c,b}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.647 a uses: [{epoch,394},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.648 a uses: [{epoch,398},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.649 a uses: [{epoch,402},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.650 a uses: [{epoch,404},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.651 a uses: [{epoch,409},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.652 a uses: [{epoch,414},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{b,d},{d,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.654 a uses: [{epoch,420},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{c,b},{d,b},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.656 a uses: [{epoch,427},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.657 a uses: [{epoch,431},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.658 a uses: [{epoch,434},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
|
||||
SET always_last_partitions ON ... we should see convergence to correct chains.
|
||||
16:49:43.701 d uses: [{epoch,434},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.799 c uses: [{epoch,434},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{b,c},{c,b},{d,b},{c,d},{d,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:43.999 a uses: [{epoch,436},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{repair_airquote_done,{we_agree,434}},{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,43}}}]}]
|
||||
16:49:44.143 b uses: [{epoch,437},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.171 d uses: [{epoch,438},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.206 c uses: [{epoch,438},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.403 a uses: [{epoch,439},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.695 d uses: [{epoch,440},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.740 c uses: [{epoch,440},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.808 a uses: [{epoch,441},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:44.810 b uses: [{epoch,442},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,44}}}]}]
|
||||
16:49:45.100 d uses: [{epoch,443},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:45.144 c uses: [{epoch,443},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:45.212 a uses: [{epoch,444},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:45.460 b uses: [{epoch,445},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:45.502 d uses: [{epoch,446},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:45.549 c uses: [{epoch,446},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:45.618 a uses: [{epoch,447},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,45}}}]}]
|
||||
16:49:46.025 d uses: [{epoch,448},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.031 c uses: [{epoch,448},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.117 b uses: [{epoch,449},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.427 a uses: [{epoch,450},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.531 d uses: [{epoch,451},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.580 c uses: [{epoch,451},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.790 b uses: [{epoch,452},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:46.833 a uses: [{epoch,453},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,46}}}]}]
|
||||
16:49:47.039 d uses: [{epoch,454},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:47.043 c uses: [{epoch,454},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:47.237 a uses: [{epoch,455},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:47.451 b uses: [{epoch,456},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:47.492 d uses: [{epoch,457},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:47.538 c uses: [{epoch,457},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:47.644 a uses: [{epoch,458},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,47}}}]}]
|
||||
16:49:48.016 d uses: [{epoch,459},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,48}}}]}]
|
||||
16:49:48.022 c uses: [{epoch,459},{author,d},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,48}}}]}]
|
||||
16:49:48.049 a uses: [{epoch,460},{author,a},{upi,[a,c]},{repair,[d]},{down,[b]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,48}}}]}]
|
||||
16:49:48.111 b uses: [{epoch,461},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,48}}}]}]
|
||||
{FLAP: c flaps 5}!
|
||||
{FLAP: a flaps 5}!
|
||||
{FLAP: c flaps 6}!
|
||||
{FLAP: a flaps 6}!
|
||||
|
||||
SET always_last_partitions OFF ... let loose the dogs of war!
|
||||
16:49:56.562 a uses: [{epoch,466},{author,a},{upi,[a,c]},{repair,[d,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.565 a uses: [{epoch,471},{author,a},{upi,[a,c]},{repair,[d,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.568 a uses: [{epoch,479},{author,a},{upi,[a,c]},{repair,[d,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.569 a uses: [{epoch,481},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.571 a uses: [{epoch,487},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.572 a uses: [{epoch,490},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.573 a uses: [{epoch,493},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.575 a uses: [{epoch,496},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.580 a uses: [{epoch,509},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.582 a uses: [{epoch,513},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.583 a uses: [{epoch,516},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{d,a},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.585 a uses: [{epoch,520},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{c,d}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.587 a uses: [{epoch,524},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.589 a uses: [{epoch,529},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.590 a uses: [{epoch,532},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.591 a uses: [{epoch,535},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{d,a},{b,c},{c,b},{d,c}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.592 a uses: [{epoch,537},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.594 a uses: [{epoch,540},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.595 a uses: [{epoch,542},{author,a},{upi,[a]},{repair,[]},{down,[b,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d}]},{nodes_up,[a]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.598 a uses: [{epoch,547},{author,a},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.622 c uses: [{epoch,555},{author,c},{upi,[a]},{repair,[b,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.625 c uses: [{epoch,561},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.626 c uses: [{epoch,565},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.627 c uses: [{epoch,569},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{c,a},{b,c},{c,b},{b,d},{d,b},{c,d}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.628 c uses: [{epoch,573},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.629 c uses: [{epoch,575},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.630 c uses: [{epoch,578},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.632 c uses: [{epoch,582},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.636 d uses: [{epoch,596},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.636 c uses: [{epoch,596},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{a,d},{d,a},{b,c},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.640 d uses: [{epoch,604},{author,d},{upi,[d]},{repair,[a]},{down,[b,c]},{d,[{author_proc,react},{ps,[{a,c},{d,b},{c,d},{d,c}]},{nodes_up,[a,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.643 d uses: [{epoch,610},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.646 d uses: [{epoch,615},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,d},{d,a},{c,b},{d,b},{c,d}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.647 d uses: [{epoch,617},{author,d},{upi,[d]},{repair,[c]},{down,[a,b]},{d,[{author_proc,react},{ps,[{a,b},{c,a},{a,d},{c,b},{b,d}]},{nodes_up,[c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.649 d uses: [{epoch,623},{author,d},{upi,[d]},{repair,[c,a,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.652 d uses: [{epoch,627},{author,d},{upi,[d]},{repair,[c,a,b]},{down,[]},{d,[{author_proc,react},{ps,[{c,a},{b,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.653 d uses: [{epoch,629},{author,d},{upi,[d]},{repair,[c,a,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.659 d uses: [{epoch,643},{author,d},{upi,[d]},{repair,[c,a,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.662 d uses: [{epoch,651},{author,d},{upi,[d]},{repair,[c,a,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.668 d uses: [{epoch,668},{author,d},{upi,[d]},{repair,[c,a,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.677 d uses: [{epoch,685},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.679 d uses: [{epoch,688},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.680 d uses: [{epoch,691},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.685 d uses: [{epoch,699},{author,d},{upi,[d]},{repair,[a,b,c]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.688 d uses: [{epoch,701},{author,d},{upi,[d]},{repair,[a,c]},{down,[b]},{d,[{author_proc,react},{ps,[{d,b}]},{nodes_up,[a,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.690 d uses: [{epoch,706},{author,d},{upi,[d]},{repair,[a,c,b]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.690 d uses: [{epoch,708},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,c},{d,a},{b,c},{c,b},{b,d},{d,b},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.697 d uses: [{epoch,724},{author,d},{upi,[d]},{repair,[]},{down,[a,b,c]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.753 b uses: [{epoch,729},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.754 b uses: [{epoch,731},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.759 b uses: [{epoch,738},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{d,a},{b,c},{d,b},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.767 b uses: [{epoch,753},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.768 b uses: [{epoch,755},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{b,a},{a,c},{d,a},{b,c},{b,d},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.773 b uses: [{epoch,765},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.778 b uses: [{epoch,775},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.784 b uses: [{epoch,792},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.787 b uses: [{epoch,799},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.790 b uses: [{epoch,807},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.795 b uses: [{epoch,821},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.797 b uses: [{epoch,825},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.798 b uses: [{epoch,828},{author,b},{upi,[b]},{repair,[c,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,b},{d,a}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.799 b uses: [{epoch,832},{author,b},{upi,[b]},{repair,[c,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.800 b uses: [{epoch,834},{author,b},{upi,[b]},{repair,[c,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.801 b uses: [{epoch,837},{author,b},{upi,[b]},{repair,[c,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.802 b uses: [{epoch,840},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{d,a},{b,c},{c,b},{b,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.803 b uses: [{epoch,842},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.804 b uses: [{epoch,845},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{c,a},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.808 b uses: [{epoch,854},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{a,d},{d,a},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.808 b uses: [{epoch,856},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.815 b uses: [{epoch,870},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{d,a},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.818 b uses: [{epoch,877},{author,b},{upi,[b]},{repair,[]},{down,[a,c,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{d,c}]},{nodes_up,[b]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.876 c uses: [{epoch,879},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.877 c uses: [{epoch,881},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.878 c uses: [{epoch,883},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.879 c uses: [{epoch,885},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.881 c uses: [{epoch,890},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.882 c uses: [{epoch,892},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{b,a},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.884 c uses: [{epoch,899},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.886 c uses: [{epoch,904},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{a,c},{c,a},{a,d},{b,c},{c,b},{b,d},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.887 c uses: [{epoch,906},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.888 c uses: [{epoch,910},{author,c},{upi,[c]},{repair,[]},{down,[a,b,d]},{d,[{author_proc,react},{ps,[{a,b},{b,a},{a,c},{c,a},{a,d},{d,a},{b,c},{c,b},{b,d},{d,b},{c,d},{d,c}]},{nodes_up,[c]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.894 c uses: [{epoch,925},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.896 c uses: [{epoch,929},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.902 c uses: [{epoch,943},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[islands_not_supported]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:56.903 c uses: [{epoch,945},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
|
||||
SET always_last_partitions ON ... we should see convergence to correct chains2.
|
||||
16:49:56.946 d uses: [{epoch,945},{author,c},{upi,[c]},{repair,[a,b,d]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,56}}}]}]
|
||||
16:49:57.049 c uses: [{epoch,947},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:57.147 b uses: [{epoch,948},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:57.350 d uses: [{epoch,948},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:57.579 a uses: [{epoch,949},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:57.625 c uses: [{epoch,950},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:57.760 d uses: [{epoch,951},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:57.959 b uses: [{epoch,951},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,57}}}]}]
|
||||
16:49:58.200 c uses: [{epoch,952},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,58}}}]}]
|
||||
16:49:58.321 a uses: [{epoch,953},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,58}}}]}]
|
||||
16:49:58.366 b uses: [{epoch,954},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,58}}}]}]
|
||||
16:49:58.572 d uses: [{epoch,954},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,58}}}]}]
|
||||
16:49:58.802 c uses: [{epoch,955},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,58}}}]}]
|
||||
16:49:58.976 d uses: [{epoch,956},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,58}}}]}]
|
||||
16:49:59.047 a uses: [{epoch,957},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.173 b uses: [{epoch,958},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.382 d uses: [{epoch,958},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.383 c uses: [{epoch,959},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.576 b uses: [{epoch,960},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.778 a uses: [{epoch,961},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.784 d uses: [{epoch,962},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.957 c uses: [{epoch,963},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:49:59.980 b uses: [{epoch,964},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,49,59}}}]}]
|
||||
16:50:00.187 d uses: [{epoch,964},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,0}}}]}]
|
||||
16:50:00.532 a uses: [{epoch,965},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,0}}}]}]
|
||||
16:50:00.552 c uses: [{epoch,966},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,0}}}]}]
|
||||
16:50:00.590 d uses: [{epoch,967},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,0}}}]}]
|
||||
16:50:00.788 b uses: [{epoch,967},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,0}}}]}]
|
||||
16:50:01.136 c uses: [{epoch,968},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:01.194 b uses: [{epoch,969},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:01.263 a uses: [{epoch,970},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:01.398 d uses: [{epoch,971},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:01.600 b uses: [{epoch,971},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:01.716 c uses: [{epoch,972},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:01.803 d uses: [{epoch,973},{author,d},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,1}}}]}]
|
||||
16:50:02.002 a uses: [{epoch,974},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,2}}}]}]
|
||||
16:50:02.003 b uses: [{epoch,975},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,2}}}]}]
|
||||
16:50:02.209 d uses: [{epoch,975},{author,b},{upi,[b]},{repair,[a,c,d]},{down,[]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,2}}}]}]
|
||||
16:50:02.291 c uses: [{epoch,976},{author,c},{upi,[c]},{repair,[b,d]},{down,[a]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[b,c,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,2}}}]}]
|
||||
{FLAP: b flaps 4}!
|
||||
{FLAP: b flaps 5}!
|
||||
{FLAP: d flaps 6}!
|
||||
{FLAP: b flaps 6}!
|
||||
16:50:02.761 a uses: [{epoch,977},{author,a},{upi,[a]},{repair,[b,d]},{down,[c]},{d,[{author_proc,react},{ps,[{a,c}]},{nodes_up,[a,b,d]}]},{d2,[{network_islands,[na_reset_by_always]},{hooray,{v2,{2015,3,3},{16,50,2}}}]}]
|
||||
|
||||
SET always_last_partitions ON ... we should see convergence to correct chains3.
|
||||
16:50:12.096 c uses: [{epoch,978},{author,c},{upi,[c]},{repair,[b,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.196 b uses: [{epoch,978},{author,c},{upi,[c]},{repair,[b,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.294 a uses: [{epoch,978},{author,c},{upi,[c]},{repair,[b,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.464 d uses: [{epoch,978},{author,c},{upi,[c]},{repair,[b,d,a]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.503 c uses: [{epoch,980},{author,c},{upi,[c,b]},{repair,[d,a]},{down,[]},{d,[{repair_airquote_done,{we_agree,978}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.601 b uses: [{epoch,980},{author,c},{upi,[c,b]},{repair,[d,a]},{down,[]},{d,[{repair_airquote_done,{we_agree,978}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.700 a uses: [{epoch,980},{author,c},{upi,[c,b]},{repair,[d,a]},{down,[]},{d,[{repair_airquote_done,{we_agree,978}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.871 d uses: [{epoch,980},{author,c},{upi,[c,b]},{repair,[d,a]},{down,[]},{d,[{repair_airquote_done,{we_agree,978}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:12.910 c uses: [{epoch,982},{author,c},{upi,[c,b,d]},{repair,[a]},{down,[]},{d,[{repair_airquote_done,{we_agree,980}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,12}}}]}]
|
||||
16:50:13.008 b uses: [{epoch,982},{author,c},{upi,[c,b,d]},{repair,[a]},{down,[]},{d,[{repair_airquote_done,{we_agree,980}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:13.106 a uses: [{epoch,982},{author,c},{upi,[c,b,d]},{repair,[a]},{down,[]},{d,[{repair_airquote_done,{we_agree,980}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:13.278 d uses: [{epoch,982},{author,c},{upi,[c,b,d]},{repair,[a]},{down,[]},{d,[{repair_airquote_done,{we_agree,980}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:13.316 c uses: [{epoch,984},{author,c},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{repair_airquote_done,{we_agree,982}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:13.414 b uses: [{epoch,984},{author,c},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{repair_airquote_done,{we_agree,982}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:13.513 a uses: [{epoch,984},{author,c},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{repair_airquote_done,{we_agree,982}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:13.684 d uses: [{epoch,984},{author,c},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{repair_airquote_done,{we_agree,982}},{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,13}}}]}]
|
||||
16:50:14.088 d uses: [{epoch,986},{author,d},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,14}}}]}]
|
||||
16:50:14.128 c uses: [{epoch,986},{author,d},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,14}}}]}]
|
||||
16:50:14.224 b uses: [{epoch,986},{author,d},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,14}}}]}]
|
||||
16:50:14.326 a uses: [{epoch,986},{author,d},{upi,[c,b,d,a]},{repair,[]},{down,[]},{d,[{author_proc,react},{ps,[]},{nodes_up,[a,b,c,d]}]},{d2,[{network_islands,[[a,b,c,d]]},{hooray,{v2,{2015,3,3},{16,50,14}}}]}]
|
||||
Tue Mar 3 16:50:20 JST 2015
|
||||
|
||||
[36.758 s] ok
|
||||
[done in 36.773 s]
|
||||
module 'machi_chain_manager1_pulse'
|
||||
module 'machi_chain_manager1'
|
||||
module 'machi_chain_manager0_test'
|
||||
machi_chain_manager0_test: smoke0_test...[0.001 s] ok
|
||||
machi_chain_manager0_test: calc_projection_test_...
|
||||
{ time ( ) , Hack } {{16,50,20},0}
|
||||
.......................
|
||||
NotCounted list was written to /tmp/manager-test.16.50.22
|
||||
OKs length = 135
|
||||
Transitions hit = 109
|
||||
NotCounted length = 26
|
||||
Least-counted transition = {{[a,c,b],[b]},1}
|
||||
Most-counted transition = {{[b],[b]},21051}
|
||||
[2.626 s] ok
|
||||
machi_chain_manager0_test: pass1_smoke_test...ok
|
||||
machi_chain_manager0_test: fail1_smoke_test...ok
|
||||
machi_chain_manager0_test: fail2_smoke_test...ok
|
||||
machi_chain_manager0_test: fail3_smoke_test...ok
|
||||
machi_chain_manager0_test: fail4_smoke_test...ok
|
||||
[done in 2.647 s]
|
||||
module 'machi_chain_manager0'
|
||||
module 'lamport_clock'
|
||||
module 'handle_errors'
|
||||
module 'event_logger'
|
||||
=======================================================
|
||||
All 20 tests passed.
|
||||
|
||||
=INFO REPORT==== 3-Mar-2015::16:50:22 ===
|
||||
application: pulse
|
||||
exited: stopped
|
||||
type: temporary
|
||||
|
||||
=INFO REPORT==== 3-Mar-2015::16:50:22 ===
|
||||
application: inets
|
||||
exited: killed
|
||||
type: temporary
|
||||
|
|
@ -1,2 +0,0 @@
|
|||
|
||||
Please see the `doc` directory at the top of the Machi repo.
|
||||
191
prototype/chain-manager/docs/corfurl.md
Normal file
|
|
@ -0,0 +1,191 @@
|
|||
## CORFU papers
|
||||
|
||||
I recommend the "5 pages" paper below first, to give a flavor of
|
||||
what the CORFU is about. When Scott first read the CORFU paper
|
||||
back in 2011 (and the Hyder paper), he thought it was insanity.
|
||||
He recommends waiting before judging quite so hastily. :-)
|
||||
|
||||
After that, then perhaps take a step back are skim over the
|
||||
Hyder paper. Hyder started before CORFU, but since CORFU, the
|
||||
Hyder folks at Microsoft have rewritten Hyder to use CORFU as
|
||||
the shared log underneath it. But the Hyder paper has lots of
|
||||
interesting bits about how you'd go about creating a distributed
|
||||
DB where the transaction log *is* the DB.
|
||||
|
||||
### "CORFU: A Distributed Shared LogCORFU: A Distributed Shared Log"
|
||||
|
||||
MAHESH BALAKRISHNAN, DAHLIA MALKHI, JOHN D. DAVIS, and VIJAYAN
|
||||
PRABHAKARAN, Microsoft Research Silicon Valley, MICHAEL WEI,
|
||||
University of California, San Diego, TED WOBBER, Microsoft Research
|
||||
Silicon Valley
|
||||
|
||||
Long version of introduction to CORFU (~30 pages)
|
||||
http://www.snookles.com/scottmp/corfu/corfu.a10-balakrishnan.pdf
|
||||
|
||||
### "CORFU: A Shared Log Design for Flash Clusters"
|
||||
|
||||
Same authors as above
|
||||
|
||||
Short version of introduction to CORFU paper above (~12 pages)
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/corfu-shared-log-design.nsdi12-final30.pdf
|
||||
|
||||
### "From Paxos to CORFU: A Flash-Speed Shared Log"
|
||||
|
||||
Same authors as above
|
||||
|
||||
5 pages, a short summary of CORFU basics and some trial applications
|
||||
that have been implemented on top of it.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/paxos-to-corfu.malki-acmstyle.pdf
|
||||
|
||||
### "Beyond Block I/O: Implementing a Distributed Shared Log in Hardware"
|
||||
|
||||
Wei, Davis, Wobber, Balakrishnan, Malkhi
|
||||
|
||||
Summary report of implmementing the CORFU server-side in
|
||||
FPGA-style hardware. (~11 pages)
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/beyond-block-io.CameraReady.pdf
|
||||
|
||||
### "Tango: Distributed Data Structures over a Shared Log"
|
||||
|
||||
Balakrishnan, Malkhi, Wobber, Wu, Brabhakaran, Wei, Davis, Rao, Zou, Zuck
|
||||
|
||||
Describes a framework for developing data structures that reside
|
||||
persistently within a CORFU log: the log *is* the database/data
|
||||
structure store.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/Tango.pdf
|
||||
|
||||
### "Dynamically Scalable, Fault-Tolerant Coordination on a Shared Logging Service"
|
||||
|
||||
Wei, Balakrishnan, Davis, Malkhi, Prabhakaran, Wobber
|
||||
|
||||
The ZooKeeper inter-server communication is replaced with CORFU.
|
||||
Faster, fewer lines of code than ZK, and more features than the
|
||||
original ZK code base.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/zookeeper-techreport.pdf
|
||||
|
||||
### "Hyder – A Transactional Record Manager for Shared Flash"
|
||||
|
||||
Bernstein, Reid, Das
|
||||
|
||||
Describes a distributed log-based DB system where the txn log is
|
||||
treated quite oddly: a "txn intent" record is written to a
|
||||
shared common log All participants read the shared log in
|
||||
parallel and make commit/abort decisions in parallel, based on
|
||||
what conflicts (or not) that they see in the log. Scott's first
|
||||
reading was "No way, wacky" ... and has since changed his mind.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/CIDR2011Proceedings.pdf
|
||||
pages 9-20
|
||||
|
||||
|
||||
|
||||
## Fiddling with PULSE
|
||||
|
||||
Do the following:
|
||||
|
||||
make clean
|
||||
make
|
||||
make pulse
|
||||
|
||||
... then watch the dots go across the screen for 60 seconds. If you
|
||||
wish, you can press `Control-c` to interrupt the test. We're really
|
||||
interested in the build artifacts.
|
||||
|
||||
erl -pz .eunit deps/*/ebin
|
||||
eqc:quickcheck(eqc:testing_time(5, corfurl_pulse:prop_pulse())).
|
||||
|
||||
This will run the PULSE test for 5 seconds. Feel free to adjust for
|
||||
as many seconds as you wish.
|
||||
|
||||
Erlang R16B02-basho4 (erts-5.10.3) [source] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
|
||||
|
||||
Eshell V5.10.3 (abort with ^G)
|
||||
1> eqc:quickcheck(eqc:testing_time(5, corfurl_pulse:prop_pulse())).
|
||||
Starting Quviq QuickCheck version 1.30.4
|
||||
(compiled at {{2014,2,7},{9,19,50}})
|
||||
Licence for Basho reserved until {{2014,2,17},{1,41,39}}
|
||||
......................................................................................
|
||||
OK, passed 86 tests
|
||||
schedule: Count: 86 Min: 2 Max: 1974 Avg: 3.2e+2 Total: 27260
|
||||
true
|
||||
2>
|
||||
|
||||
REPL interactive work can be done via:
|
||||
|
||||
1. Edit code, e.g. `corfurl_pulse.erl`.
|
||||
2. Run `env BITCASK_PULSE=1 ./rebar skip_deps=true -D PULSE eunit suites=SKIP`
|
||||
to compile.
|
||||
3. Reload any recompiled modules, e.g. `l(corfurl_pulse).`
|
||||
4. Resume QuickCheck activities.
|
||||
|
||||
## Seeing an PULSE scheduler interleaving failure in action
|
||||
|
||||
1. Edit `corfurl_pulse:check_trace()` to uncomment the
|
||||
use of `conjunction()` that mentions `bogus_order_check_do_not_use_me`
|
||||
and comment out the real `conjunction()` call below it.
|
||||
2. Recompile & reload.
|
||||
3. Check.
|
||||
|
||||
For example:
|
||||
|
||||
9> eqc:quickcheck(eqc:testing_time(5, corfurl_pulse:prop_pulse())).
|
||||
.........Failed! After 9 tests.
|
||||
|
||||
Sweet! The first tuple below are the first `?FORALL()` values,
|
||||
and the 2nd is the list of commands,
|
||||
`{SequentialCommands, ListofParallelCommandLists}`. The 3rd is the
|
||||
seed used to perturb the PULSE scheduler.
|
||||
|
||||
In this case, `SequentialCommands` has two calls (to `setup()` then
|
||||
`append()`) and there are two parallel procs: one makes 1 call
|
||||
call to `append()` and the other makes 2 calls to `append()`.
|
||||
|
||||
{2,2,9}
|
||||
{{[{set,{var,1},{call,corfurl_pulse,setup,[2,2,9]}}],
|
||||
[[{set,{var,3},
|
||||
{call,corfurl_pulse,append,
|
||||
[{var,1},<<231,149,226,203,10,105,54,223,147>>]}}],
|
||||
[{set,{var,2},
|
||||
{call,corfurl_pulse,append,
|
||||
[{var,1},<<7,206,146,75,249,13,154,238,110>>]}},
|
||||
{set,{var,4},
|
||||
{call,corfurl_pulse,append,
|
||||
[{var,1},<<224,121,129,78,207,23,79,216,36>>]}}]]},
|
||||
{27492,46961,4884}}
|
||||
|
||||
Here are our results:
|
||||
|
||||
simple_result: passed
|
||||
errors: passed
|
||||
events: failed
|
||||
identity: passed
|
||||
bogus_order_check_do_not_use_me: failed
|
||||
[{ok,1},{ok,3},{ok,2}] /= [{ok,1},{ok,2},{ok,3}]
|
||||
|
||||
Our (bogus!) order expectation was violated. Shrinking!
|
||||
|
||||
simple_result: passed
|
||||
errors: passed
|
||||
events: failed
|
||||
identity: passed
|
||||
bogus_order_check_do_not_use_me: failed
|
||||
[{ok,1},{ok,3},{ok,2}] /= [{ok,1},{ok,2},{ok,3}]
|
||||
|
||||
Shrinking was able to remove two `append()` calls and to shrink the
|
||||
size of the pages down from 9 bytes down to 1 byte.
|
||||
|
||||
Shrinking........(8 times)
|
||||
{1,1,1}
|
||||
{{[{set,{var,1},{call,corfurl_pulse,setup,[1,1,1]}}],
|
||||
[[{set,{var,3},{call,corfurl_pulse,append,[{var,1},<<0>>]}}],
|
||||
[{set,{var,4},{call,corfurl_pulse,append,[{var,1},<<0>>]}}]]},
|
||||
{27492,46961,4884}}
|
||||
events: failed
|
||||
bogus_order_check_do_not_use_me: failed
|
||||
[{ok,2},{ok,1}] /= [{ok,1},{ok,2}]
|
||||
false
|
||||
|
|
@ -1,16 +1,3 @@
|
|||
## NOTE
|
||||
|
||||
The Git commit numbers used below refer to a private Git
|
||||
repository and not to the https://github.com/basho/machi repo. My
|
||||
apologies for any confusion.
|
||||
|
||||
## Generating diagrams of the race/bug scenarios
|
||||
|
||||
Each of the scenario notes includes an MSC diagram
|
||||
(Message Sequence Chart) specification file
|
||||
to help illustrate the race, each with an `.mscgen` suffix. Use the
|
||||
`mscgen` utility to render the diagrams into PNG, Encapsulated Postscript,
|
||||
or other graphic file formats.
|
||||
|
||||
## read-repair-race.1.
|
||||
|
||||
|
|
@ -23,15 +10,7 @@ Chart (MSC) for a race found at commit 087c2605ab.
|
|||
Second attempt. This is almost exactly the trace that is
|
||||
generated by this failing test case at commit 087c2605ab:
|
||||
|
||||
C2 = [{1,2,1},
|
||||
{{[{set,{var,1},{call,corfurl_pulse,setup,[1,2,1,standard]}}],
|
||||
[[{set,{var,3},{call,corfurl_pulse,append,[{var,1},<<0>>]}}],
|
||||
[{set,{var,2},{call,corfurl_pulse,read_approx,[{var,1},6201864198]}},
|
||||
{set,{var,5},{call,corfurl_pulse,append,[{var,1},<<0>>]}}],
|
||||
[{set,{var,4},{call,corfurl_pulse,append,[{var,1},<<0>>]}},
|
||||
{set,{var,6},{call,corfurl_pulse,trim,[{var,1},510442857]}}]]},
|
||||
{25152,1387,78241}},
|
||||
[{events,[[{no_bad_reads,[]}]]}]]
|
||||
C2 = [{1,2,1},{{[{set,{var,1},{call,corfurl_pulse,setup,[1,2,1,standard]}}],[[{set,{var,3},{call,corfurl_pulse,append,[{var,1},<<0>>]}}],[{set,{var,2},{call,corfurl_pulse,read_approx,[{var,1},6201864198]}},{set,{var,5},{call,corfurl_pulse,append,[{var,1},<<0>>]}}],[{set,{var,4},{call,corfurl_pulse,append,[{var,1},<<0>>]}},{set,{var,6},{call,corfurl_pulse,trim,[{var,1},510442857]}}]]},{25152,1387,78241}},[{events,[[{no_bad_reads,[]}]]}]].
|
||||
eqc:check(corfurl_pulse:prop_pulse(), C2).
|
||||
|
||||
## read-repair-race.2b.*
|
||||
24824
prototype/chain-manager/docs/machi/Diagram1.eps
Normal file
109
prototype/chain-manager/docs/machi/chain-mgmt-flowchart.dot
Normal file
|
|
@ -0,0 +1,109 @@
|
|||
digraph {
|
||||
compound=true
|
||||
label="Machi chain management flowchart (sample)";
|
||||
|
||||
node[shape="box", style="rounded"]
|
||||
start;
|
||||
node[shape="box", style="rounded", label="stop1"]
|
||||
stop1;
|
||||
node[shape="box", style="rounded", label="stop2"]
|
||||
stop2;
|
||||
node[shape="box", style="rounded"]
|
||||
crash;
|
||||
|
||||
subgraph clustera {
|
||||
node[shape="parallelogram", style="", label="Set retry counter = 0"]
|
||||
a05_retry;
|
||||
node[shape="parallelogram", style="", label="Create P_newprop @ epoch E+1\nbased on P_current @ epoch E"]
|
||||
a10_create;
|
||||
node[shape="parallelogram", style="", label="Get latest public projection, P_latest"]
|
||||
a20_get;
|
||||
node[shape="diamond", style="", label="Epoch(P_latest) > Epoch(P_current)\norelse\nP_latest was not unanimous"]
|
||||
a30_epoch;
|
||||
node[shape="diamond", style="", label="Epoch(P_latest) == Epoch(P_current)"]
|
||||
a40_epochequal;
|
||||
node[shape="diamond", style="", label="P_latest == P_current"]
|
||||
a50_equal;
|
||||
}
|
||||
|
||||
subgraph clustera100 {
|
||||
node[shape="diamond", style="", label="Write P_newprop to everyone"]
|
||||
a100_write;
|
||||
}
|
||||
|
||||
subgraph clusterb {
|
||||
node[shape="diamond", style="", label="P_latest was unanimous?"]
|
||||
b10_unanimous;
|
||||
node[shape="diamond", style="", label="Retry counter too big?"]
|
||||
b20_counter;
|
||||
node[shape="diamond", style="", label="Rank(P_latest) >= Rank(P_newprop)"]
|
||||
b30_rank;
|
||||
node[shape="diamond", style="", label="P_latest.upi == P_newprop.upi\nand also\nPlatest.repairing == P_newprop.repairing"]
|
||||
b40_condc;
|
||||
node[shape="square", style="", label="P_latest author is\ntoo slow, let's try!"]
|
||||
b45_lets;
|
||||
node[shape="parallelogram", style="", label="P_newprop is better than P_latest.\nSet P_newprop.epoch = P_latest.epoch + 1."]
|
||||
b50_better;
|
||||
}
|
||||
|
||||
subgraph clusterc {
|
||||
node[shape="diamond", style="", label="Is Move(P_current, P_latest) ok?"]
|
||||
c10_move;
|
||||
node[shape="parallelogram", style="", label="Tell Author(P_latest) to rewrite\nwith a bigger epoch number"]
|
||||
c20_tell;
|
||||
}
|
||||
|
||||
subgraph clusterd {
|
||||
node[shape="diamond", style="", label="Use P_latest as the\nnew P_current"]
|
||||
d10_use;
|
||||
}
|
||||
|
||||
start -> a05_retry;
|
||||
|
||||
a05_retry -> a10_create;
|
||||
a10_create -> a20_get;
|
||||
a20_get -> a30_epoch;
|
||||
a30_epoch -> a40_epochequal[label="false"];
|
||||
a30_epoch -> b10_unanimous[label="true"];
|
||||
a40_epochequal -> a50_equal[label="true"];
|
||||
a40_epochequal -> crash[label="falseXX"];
|
||||
a50_equal -> stop1[label="true"];
|
||||
a50_equal -> b20_counter[label="false"];
|
||||
|
||||
a100_write -> a10_create;
|
||||
|
||||
b10_unanimous -> c10_move[label="yes"];
|
||||
b10_unanimous -> b20_counter[label="no"];
|
||||
b20_counter -> b45_lets[label="true"];
|
||||
b20_counter -> b30_rank[label="false"];
|
||||
b30_rank -> b40_condc[label="false"];
|
||||
b30_rank -> c20_tell[label="true"];
|
||||
b40_condc -> b50_better[label="false"];
|
||||
b40_condc -> c20_tell[label="true"];
|
||||
b45_lets -> b50_better;
|
||||
b50_better -> a100_write;
|
||||
|
||||
c10_move -> d10_use[label="yes"];
|
||||
c10_move -> a100_write[label="no"];
|
||||
c20_tell -> b50_better;
|
||||
|
||||
d10_use -> stop2;
|
||||
|
||||
{rank=same; clustera clusterb clusterc clusterd};
|
||||
|
||||
// {rank=same; a10_create b10_unanimous c10_move d10_use stop2};
|
||||
// {rank=same; a20_get b20_counter c20_tell};
|
||||
// {rank=same; a30_epoch b40_condc};
|
||||
// {rank=same; a40_epochequal b40_condc crash};
|
||||
// {rank=same; stop1 a50_equal b50_better};
|
||||
|
||||
// if_valid;
|
||||
//
|
||||
// start -> input;
|
||||
// input -> if_valid;
|
||||
// if_valid -> message[label="no"];
|
||||
// if_valid -> end[label="yes"];
|
||||
// message -> input;
|
||||
|
||||
// {rank=same; message input}
|
||||
}
|
||||
|
|
@ -45,16 +45,19 @@
|
|||
dbg2 :: list() %proplist(), is not checksummed
|
||||
}).
|
||||
|
||||
-define(NOT_FLAPPING, {0,0,0}).
|
||||
|
||||
-record(ch_mgr, {
|
||||
init_finished :: boolean(),
|
||||
name :: m_server(),
|
||||
proj :: #projection{},
|
||||
proj_history :: queue(),
|
||||
myflu :: pid() | atom(),
|
||||
flap_limit :: non_neg_integer(),
|
||||
%%
|
||||
runenv :: list(), %proplist()
|
||||
opts :: list(), %proplist()
|
||||
flaps=0 :: integer(),
|
||||
flaps=0 :: integer(),
|
||||
|
||||
%% Deprecated ... TODO: remove when old test unit test code is removed
|
||||
proj_proposed :: 'none' | #projection{}
|
||||
|
|
|
|||
|
|
@ -1,6 +0,0 @@
|
|||
%%% {erl_opts, [warnings_as_errors, {parse_transform, lager_transform}, debug_info]}.
|
||||
{erl_opts, [{parse_transform, lager_transform}, debug_info]}.
|
||||
{deps, [
|
||||
{lager, "2.0.1", {git, "git://github.com/basho/lager.git", {tag, "2.0.1"}}}
|
||||
]}.
|
||||
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl).
|
||||
|
||||
-export([new_simple_projection/5,
|
||||
|
|
@ -261,7 +262,6 @@ trim_page(#proj{epoch=Epoch} = P, LPN) ->
|
|||
fill_or_trim_page([], _Epoch, _LPN, _Func) ->
|
||||
ok;
|
||||
fill_or_trim_page([H|T], Epoch, LPN, Func) ->
|
||||
%% io:format(user, "~s.erl line ~w: TODO: this 'fill or trim' logic is probably stupid, due to mis-remembering the CORFU paper, sorry! Commenting out this warning line is OK, if you wish to proceed with testing Corfurl. This code can change a fill into a trim. Those things are supposed to be separate, silly me, a fill should never automagically change to a trim.\n", [?MODULE, ?LINE]),
|
||||
case corfurl_flu:Func(flu_pid(H), Epoch, LPN) of
|
||||
Res when Res == ok; Res == error_trimmed ->
|
||||
%% Detecting a race here between fills and trims is too crazy,
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_client).
|
||||
|
||||
-export([append_page/2, read_page/2, fill_page/2, trim_page/2, scan_forward/3]).
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_flu).
|
||||
|
||||
-behaviour(gen_server).
|
||||
|
|
@ -123,7 +124,7 @@ init({Dir, ExpPageSize, ExpMaxMem}) ->
|
|||
lclock_init(),
|
||||
|
||||
MemFile = memfile_path(Dir),
|
||||
ok = filelib:ensure_dir(MemFile),
|
||||
filelib:ensure_dir(MemFile),
|
||||
{ok, FH} = file:open(MemFile, [read, write, raw, binary]),
|
||||
|
||||
{_Version, MinEpoch, PageSize, MaxMem, TrimWatermark} =
|
||||
|
|
@ -324,7 +325,7 @@ check_write(LogicalPN, PageBin,
|
|||
error_overwritten
|
||||
end;
|
||||
true ->
|
||||
{bummer, ?MODULE, ?LINE, lpn, LogicalPN, offset, Offset, max_mem, MaxMem, page_size, PageSize, bin_size, byte_size(PageBin)}
|
||||
{bummer, ?MODULE, ?LINE, lpn, LogicalPN, offset, Offset, max_mem, MaxMem, page_size, PageSize}
|
||||
end.
|
||||
|
||||
check_is_written(Offset, _PhysicalPN, #state{mem_fh=FH}) ->
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_sequencer).
|
||||
|
||||
-behaviour(gen_server).
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_util).
|
||||
|
||||
-export([delete_dir/1]).
|
||||
|
|
@ -1,9 +0,0 @@
|
|||
{application, foo, [
|
||||
{description, "Prototype of Machi chain manager."},
|
||||
{vsn, "0.0.0"},
|
||||
{applications, [kernel, stdlib, lager]},
|
||||
{mod,{foo_unfinished_app,[]}},
|
||||
{registered, []},
|
||||
{env, [
|
||||
]}
|
||||
]}.
|
||||
|
|
@ -2,7 +2,7 @@
|
|||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%% Copyright (c) 2014-2015 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
%% Version 2.0 (the "License"); you may not use this file
|
||||
|
|
@ -50,7 +50,8 @@
|
|||
test_calc_proposed_projection/1,
|
||||
test_write_proposed_projection/1,
|
||||
test_read_latest_public_projection/2,
|
||||
test_react_to_env/1]).
|
||||
test_react_to_env/1,
|
||||
get_all_hosed/1]).
|
||||
|
||||
-ifdef(EQC).
|
||||
-include_lib("eqc/include/eqc.hrl").
|
||||
|
|
@ -113,16 +114,22 @@ init({MyName, All_list, MyFLUPid, MgrOpts}) ->
|
|||
{seed, now()},
|
||||
{network_partitions, []},
|
||||
{network_islands, []},
|
||||
{flapping_i, []},
|
||||
{up_nodes, not_init_yet}],
|
||||
BestProj = make_initial_projection(MyName, All_list, All_list,
|
||||
[], [{author_proc, init_best}]),
|
||||
[], []),
|
||||
NoneProj = make_initial_projection(MyName, All_list, [],
|
||||
[], [{author_proc, init_none}]),
|
||||
[], []),
|
||||
S = #ch_mgr{init_finished=false,
|
||||
name=MyName,
|
||||
proj=NoneProj,
|
||||
proj_history=queue:new(),
|
||||
myflu=MyFLUPid, % pid or atom local name
|
||||
%% TODO 2015-03-04: revisit, should this constant be bigger?
|
||||
%% Yes, this should be bigger, but it's a hack. There is
|
||||
%% no guarantee that all parties will advance to a minimum
|
||||
%% flap awareness in the amount of time that this mgr will.
|
||||
flap_limit=length(All_list) + 50,
|
||||
runenv=RunEnv,
|
||||
opts=MgrOpts},
|
||||
|
||||
|
|
@ -145,7 +152,7 @@ handle_call(_Call, _From, #ch_mgr{init_finished=false} = S) ->
|
|||
handle_call({calculate_projection_internal_old}, _From,
|
||||
#ch_mgr{name=MyName}=S) ->
|
||||
RelativeToServer = MyName,
|
||||
{Reply, S2} = calc_projection(S, RelativeToServer, [{author_proc, call}]),
|
||||
{Reply, S2} = calc_projection(S, RelativeToServer),
|
||||
{reply, Reply, S2};
|
||||
handle_call({test_write_proposed_projection}, _From, S) ->
|
||||
if S#ch_mgr.proj_proposed == none ->
|
||||
|
|
@ -161,7 +168,7 @@ handle_call({stop}, _From, S) ->
|
|||
handle_call({test_calc_projection, KeepRunenvP}, _From,
|
||||
#ch_mgr{name=MyName}=S) ->
|
||||
RelativeToServer = MyName,
|
||||
{P, S2} = calc_projection(S, RelativeToServer, [{author_proc, call}]),
|
||||
{P, S2} = calc_projection(S, RelativeToServer),
|
||||
{reply, {ok, P}, if KeepRunenvP -> S2;
|
||||
true -> S
|
||||
end};
|
||||
|
|
@ -180,7 +187,7 @@ handle_cast(_Cast, #ch_mgr{init_finished=false} = S) ->
|
|||
{noreply, S};
|
||||
handle_cast({test_calc_proposed_projection}, #ch_mgr{name=MyName}=S) ->
|
||||
RelativeToServer = MyName,
|
||||
{Proj, S2} = calc_projection(S, RelativeToServer, [{author_proc, cast}]),
|
||||
{Proj, S2} = calc_projection(S, RelativeToServer),
|
||||
{noreply, S2#ch_mgr{proj_proposed=Proj}};
|
||||
handle_cast(_Cast, S) ->
|
||||
?D({cast_whaaaaaaaaaaa, _Cast}),
|
||||
|
|
@ -256,9 +263,13 @@ cl_write_public_proj_local(Epoch, Proj, SkipLocalWriteErrorP,
|
|||
end,
|
||||
case Res0 of
|
||||
ok ->
|
||||
Continue();
|
||||
{XX, SS} = Continue(),
|
||||
{{qqq_local_write, ok, XX}, SS};
|
||||
%% Continue();
|
||||
_Else when SkipLocalWriteErrorP ->
|
||||
Continue();
|
||||
{XX, SS} = Continue(),
|
||||
{{qqq_local_write, _Else, XX}, SS};
|
||||
%% Continue();
|
||||
Else when Else == error_written; Else == timeout; Else == t_timeout ->
|
||||
{Else, S2}
|
||||
end.
|
||||
|
|
@ -274,7 +285,7 @@ cl_write_public_proj_remote(FLUs, Partitions, Epoch, Proj, S) ->
|
|||
do_cl_read_latest_public_projection(ReadRepairP,
|
||||
#ch_mgr{proj=Proj1, myflu=_MyFLU} = S) ->
|
||||
_Epoch1 = Proj1#projection.epoch_number,
|
||||
case cl_read_latest_public_projection(S) of
|
||||
case cl_read_latest_projection(public, S) of
|
||||
{needs_repair, FLUsRs, Extra, S3} ->
|
||||
if not ReadRepairP ->
|
||||
{not_unanimous, todoxyz, [{results, FLUsRs}|Extra], S3};
|
||||
|
|
@ -286,11 +297,11 @@ do_cl_read_latest_public_projection(ReadRepairP,
|
|||
{UnanimousTag, Proj2, Extra, S3}
|
||||
end.
|
||||
|
||||
cl_read_latest_public_projection(#ch_mgr{proj=CurrentProj}=S) ->
|
||||
cl_read_latest_projection(ProjectionType, #ch_mgr{proj=CurrentProj}=S) ->
|
||||
#projection{all_members=All_list} = CurrentProj,
|
||||
{_UpNodes, Partitions, S2} = calc_up_nodes(S),
|
||||
DoIt = fun(X) ->
|
||||
case machi_flu0:proj_read_latest(X, public) of
|
||||
case machi_flu0:proj_read_latest(X, ProjectionType) of
|
||||
{ok, P} -> P;
|
||||
Else -> Else
|
||||
end
|
||||
|
|
@ -300,6 +311,11 @@ cl_read_latest_public_projection(#ch_mgr{proj=CurrentProj}=S) ->
|
|||
FLUsRs = lists:zip(All_list, Rs),
|
||||
UnwrittenRs = [x || error_unwritten <- Rs],
|
||||
Ps = [Proj || {_FLU, Proj} <- FLUsRs, is_record(Proj, projection)],
|
||||
%% debug only:
|
||||
%% BadAnswerFLUs = [{FLU,bad_answer,Answer} || {FLU, Answer} <- FLUsRs,
|
||||
%% not is_record(Answer, projection)],
|
||||
BadAnswerFLUs = [FLU || {FLU, Answer} <- FLUsRs,
|
||||
not is_record(Answer, projection)],
|
||||
if length(UnwrittenRs) == length(Rs) ->
|
||||
{error_unwritten, FLUsRs, [todo_fix_caller_perhaps], S2};
|
||||
UnwrittenRs /= [] ->
|
||||
|
|
@ -312,8 +328,17 @@ cl_read_latest_public_projection(#ch_mgr{proj=CurrentProj}=S) ->
|
|||
end,
|
||||
Extra = [{all_members_replied, length(Rs) == length(All_list)}],
|
||||
Best_FLUs = [FLU || {FLU, Projx} <- FLUsRs, Projx == BestProj],
|
||||
AllHosed = lists:usort(
|
||||
lists:flatten([get_all_hosed(P) || P <- Ps])),
|
||||
AllFlapCounts = merge_flap_counts([get_all_flap_counts(P) ||
|
||||
P <- Ps]),
|
||||
Extra2 = [{unanimous_flus,Best_FLUs},
|
||||
{not_unanimous_flus, NotBestPs}|Extra],
|
||||
{not_unanimous_flus, All_list --
|
||||
(Best_FLUs ++ BadAnswerFLUs)},
|
||||
{bad_answer_flus, BadAnswerFLUs},
|
||||
{not_unanimous_answers, NotBestPs},
|
||||
{trans_all_hosed, AllHosed},
|
||||
{trans_all_flap_counts, AllFlapCounts}|Extra],
|
||||
{UnanimousTag, BestProj, Extra2, S2}
|
||||
end.
|
||||
|
||||
|
|
@ -364,26 +389,31 @@ make_projection(EpochNum,
|
|||
P2 = update_projection_checksum(P),
|
||||
P2#projection{dbg2=Dbg2}.
|
||||
|
||||
update_projection_checksum(P) ->
|
||||
CSum = crypto:hash(sha, term_to_binary(P)),
|
||||
P#projection{epoch_csum=CSum}.
|
||||
update_projection_checksum(#projection{dbg2=Dbg2} = P) ->
|
||||
CSum = crypto:hash(sha, term_to_binary(P#projection{dbg2=[]})),
|
||||
P#projection{epoch_csum=CSum, dbg2=Dbg2}.
|
||||
|
||||
update_projection_dbg2(P, Dbg2) when is_list(Dbg2) ->
|
||||
P#projection{dbg2=Dbg2}.
|
||||
|
||||
calc_projection(S, RelativeToServer) ->
|
||||
AllHosed = [],
|
||||
calc_projection(S, RelativeToServer, AllHosed).
|
||||
|
||||
calc_projection(#ch_mgr{proj=LastProj, runenv=RunEnv} = S, RelativeToServer,
|
||||
Dbg) ->
|
||||
AllHosed) ->
|
||||
Dbg = [],
|
||||
OldThreshold = proplists:get_value(old_threshold, RunEnv),
|
||||
NoPartitionThreshold = proplists:get_value(no_partition_threshold, RunEnv),
|
||||
calc_projection(OldThreshold, NoPartitionThreshold, LastProj,
|
||||
RelativeToServer, Dbg, S).
|
||||
RelativeToServer, AllHosed, Dbg, S).
|
||||
|
||||
%% OldThreshold: Percent chance of using the old/previous network partition list
|
||||
%% NoPartitionThreshold: If the network partition changes, what percent chance
|
||||
%% that there are no partitions at all?
|
||||
|
||||
calc_projection(_OldThreshold, _NoPartitionThreshold, LastProj,
|
||||
RelativeToServer, Dbg,
|
||||
RelativeToServer, _____TODO_delme_I_think__AllHosed, Dbg,
|
||||
#ch_mgr{name=MyName, runenv=RunEnv1}=S) ->
|
||||
#projection{epoch_number=OldEpochNum,
|
||||
all_members=All_list,
|
||||
|
|
@ -403,7 +433,7 @@ calc_projection(_OldThreshold, _NoPartitionThreshold, LastProj,
|
|||
{NewUPI_list3, Repairing_list3, RunEnv3} =
|
||||
case {NewUp, Repairing_list2} of
|
||||
{[], []} ->
|
||||
D_foo=[],
|
||||
D_foo=[],
|
||||
{NewUPI_list, [], RunEnv2};
|
||||
{[], [H|T]} when RelativeToServer == hd(NewUPI_list) ->
|
||||
%% The author is head of the UPI list. Let's see if
|
||||
|
|
@ -417,16 +447,19 @@ D_foo=[],
|
|||
tl(NewUPI_list) ++ Repairing_list2,
|
||||
S#ch_mgr.proj, Partitions, S),
|
||||
if not SameEpoch_p ->
|
||||
D_foo=[],
|
||||
D_foo=[],
|
||||
{NewUPI_list, OldRepairing_list, RunEnv2};
|
||||
true ->
|
||||
D_foo=[{repair_airquote_done, {we_agree, (S#ch_mgr.proj)#projection.epoch_number}}],
|
||||
D_foo=[{repair_airquote_done,
|
||||
{we_agree,
|
||||
(S#ch_mgr.proj)#projection.epoch_number}}],
|
||||
{NewUPI_list ++ [H], T, RunEnv2}
|
||||
end;
|
||||
{_, _} ->
|
||||
D_foo=[],
|
||||
D_foo=[],
|
||||
{NewUPI_list, OldRepairing_list, RunEnv2}
|
||||
end,
|
||||
|
||||
Repairing_list4 = case NewUp of
|
||||
[] -> Repairing_list3;
|
||||
NewUp -> Repairing_list3 ++ NewUp
|
||||
|
|
@ -446,7 +479,7 @@ D_foo=[],
|
|||
|
||||
P = make_projection(OldEpochNum + 1,
|
||||
MyName, All_list, Down, NewUPI, NewRepairing,
|
||||
D_foo ++
|
||||
[da_hd] ++ D_foo ++
|
||||
Dbg ++ [{ps, Partitions},{nodes_up, Up}]),
|
||||
{P, S#ch_mgr{runenv=RunEnv3}}.
|
||||
|
||||
|
|
@ -529,6 +562,8 @@ rank_projections(Projs, CurrentProj) ->
|
|||
N = length(All_list),
|
||||
[{rank_projection(Proj, MemberRank, N), Proj} || Proj <- Projs].
|
||||
|
||||
rank_projection(#projection{upi=[]}, _MemberRank, _N) ->
|
||||
-100;
|
||||
rank_projection(#projection{author_server=Author,
|
||||
upi=UPI_list,
|
||||
repairing=Repairing_list}, MemberRank, N) ->
|
||||
|
|
@ -546,15 +581,8 @@ react_to_env_A10(S) ->
|
|||
?REACT(a10),
|
||||
react_to_env_A20(0, S).
|
||||
|
||||
react_to_env_A20(Retries, #ch_mgr{name=MyName} = S) ->
|
||||
react_to_env_A20(Retries, S) ->
|
||||
?REACT(a20),
|
||||
RelativeToServer = MyName,
|
||||
{P_newprop, S2} = calc_projection(S, RelativeToServer,
|
||||
[{author_proc, react}]),
|
||||
react_to_env_A30(Retries, P_newprop, S2).
|
||||
|
||||
react_to_env_A30(Retries, P_newprop, S) ->
|
||||
?REACT(a30),
|
||||
{UnanimousTag, P_latest, ReadExtra, S2} =
|
||||
do_cl_read_latest_public_projection(true, S),
|
||||
|
||||
|
|
@ -562,29 +590,58 @@ react_to_env_A30(Retries, P_newprop, S) ->
|
|||
%% to determine if *all* of the UPI+Repairing FLUs are members of
|
||||
%% the unanimous server replies.
|
||||
UnanimousFLUs = lists:sort(proplists:get_value(unanimous_flus, ReadExtra)),
|
||||
UPI_Repairing_FLUs = lists:sort(P_latest#projection.upi ++
|
||||
P_latest#projection.repairing),
|
||||
?REACT({a20,?LINE,latest_epoch,P_latest#projection.epoch_number}),
|
||||
?REACT({a20,?LINE,latest_upi,P_latest#projection.upi}),
|
||||
?REACT({a20,?LINE,latest_repairing,P_latest#projection.repairing}),
|
||||
?REACT({a20,?LINE,flapping_i,get_raw_flapping_i(P_latest)}),
|
||||
|
||||
%% Reach into hosed compensation, if necessary, to find effective
|
||||
%% UPI and Repairing lists.
|
||||
{E_UPI, E_Repairing} = case get_flapping_hosed_compensation(P_latest) of
|
||||
undefined ->
|
||||
{P_latest#projection.upi,
|
||||
P_latest#projection.repairing};
|
||||
Answer ->
|
||||
Answer
|
||||
end,
|
||||
UPI_Repairing_FLUs = lists:sort(E_UPI ++ E_Repairing),
|
||||
All_UPI_Repairing_were_unanimous = UPI_Repairing_FLUs == UnanimousFLUs,
|
||||
%% TODO: investigate if the condition below is more correct?
|
||||
%% All_UPI_Repairing_were_unanimous = (UPI_Repairing_FLUs -- UnanimousFLUs) == [],
|
||||
%% TODO: or:
|
||||
%% All_UPI_Repairing_were_unanimous =
|
||||
%% ordsets:is_subset(ordsets:from_list(UPI_Repairing_FLUs),
|
||||
%% ordsets:from_list(UnanimousFLUs)),
|
||||
LatestUnanimousP =
|
||||
if UnanimousTag == unanimous
|
||||
andalso
|
||||
All_UPI_Repairing_were_unanimous ->
|
||||
?REACT({a30,?LINE}),
|
||||
?REACT({a20,?LINE}),
|
||||
true;
|
||||
UnanimousTag == unanimous ->
|
||||
?REACT({a30,?LINE,UPI_Repairing_FLUs,UnanimousFLUs}),
|
||||
?REACT({a20,?LINE,UPI_Repairing_FLUs,UnanimousFLUs}),
|
||||
false;
|
||||
UnanimousTag == not_unanimous ->
|
||||
?REACT({a30,?LINE}),
|
||||
?REACT({a20,?LINE}),
|
||||
false;
|
||||
true ->
|
||||
exit({badbad, UnanimousTag})
|
||||
end,
|
||||
react_to_env_A40(Retries, P_newprop, P_latest,
|
||||
react_to_env_A30(Retries, P_latest,
|
||||
LatestUnanimousP, S2).
|
||||
|
||||
react_to_env_A30(Retries, P_latest, LatestUnanimousP,
|
||||
#ch_mgr{name=MyName, flap_limit=FlapLimit} = S) ->
|
||||
?REACT(a30),
|
||||
RelativeToServer = MyName,
|
||||
AllHosed = get_all_hosed(S),
|
||||
{P_newprop1, S2} = calc_projection(S, RelativeToServer, AllHosed),
|
||||
|
||||
{P_newprop2, S3} = calculate_flaps(P_newprop1, FlapLimit, S2),
|
||||
|
||||
react_to_env_A40(Retries, P_newprop2, P_latest,
|
||||
LatestUnanimousP, S3).
|
||||
|
||||
react_to_env_A40(Retries, P_newprop, P_latest, LatestUnanimousP,
|
||||
#ch_mgr{name=MyName, proj=P_current}=S) ->
|
||||
?REACT(a40),
|
||||
|
|
@ -690,33 +747,81 @@ react_to_env_A50(P_latest, S) ->
|
|||
{{no_change, P_latest#projection.epoch_number}, S}.
|
||||
|
||||
react_to_env_B10(Retries, P_newprop, P_latest, LatestUnanimousP,
|
||||
Rank_newprop, Rank_latest, #ch_mgr{name=MyName}=S0) ->
|
||||
Rank_newprop, Rank_latest,
|
||||
#ch_mgr{name=MyName, flap_limit=FlapLimit}=S) ->
|
||||
?REACT(b10),
|
||||
|
||||
S = calculate_flaps(P_newprop, S0),
|
||||
FlapLimit = 3, % todo tweak
|
||||
{_P_newprop_flap_time, P_newprop_flap_count} = get_flap_count(P_newprop),
|
||||
LatestAllFlapCounts = get_all_flap_counts_counts(P_latest),
|
||||
P_latest_trans_flap_count = my_find_minmost(LatestAllFlapCounts),
|
||||
|
||||
if
|
||||
LatestUnanimousP ->
|
||||
?REACT({b10, ?LINE}),
|
||||
put(b10_hack, false),
|
||||
|
||||
react_to_env_C100(P_newprop, P_latest, S);
|
||||
|
||||
S#ch_mgr.flaps > FlapLimit
|
||||
andalso
|
||||
Rank_latest =< Rank_newprop ->
|
||||
if S#ch_mgr.flaps - FlapLimit - 3 =< 0 -> io:format(user, "{FLAP: ~w flaps ~w}!\n", [S#ch_mgr.name, S#ch_mgr.flaps]); true -> ok end,
|
||||
{_, _, USec} = os:timestamp(),
|
||||
%% If we always go to C200, then we can deadlock sometimes.
|
||||
%% So we roll the dice.
|
||||
%% TODO: make this PULSE-friendly!
|
||||
if USec rem 3 == 0 ->
|
||||
P_newprop_flap_count >= FlapLimit ->
|
||||
%% I am flapping ... what else do I do?
|
||||
B10Hack = get(b10_hack),
|
||||
if B10Hack == false andalso P_newprop_flap_count - FlapLimit - 3 =< 0 -> io:format(user, "{FLAP: ~w flaps ~w}!\n", [S#ch_mgr.name, P_newprop_flap_count]), put(b10_hack, true); true -> ok end,
|
||||
|
||||
if
|
||||
%% So, if we noticed a flap count by some FLU X with a
|
||||
%% count below FlapLimit, then X crashes so that X's
|
||||
%% flap count remains below FlapLimit, then we could get
|
||||
%% stuck forever? Hrm, except that 'crashes' ought to be
|
||||
%% detected by our own failure detector and get us out of
|
||||
%% this current flapping situation, right? TODO
|
||||
%%
|
||||
%% 2015-04-05: If we add 'orelse AllSettled' to this 'if'
|
||||
%% clause, then we can end up short-circuiting too
|
||||
%% early. (Where AllSettled comes from the runenv's
|
||||
%% flapping_i prop.) So, I believe that we need to
|
||||
%% rely on the failure detector to rescue us.
|
||||
%%
|
||||
%% TODO About the above ^^ I think that was based on buggy
|
||||
%% calculation of AllSettled. Recheck!
|
||||
%%
|
||||
%% TODO Yay, another magic constant below, added to
|
||||
%% FlapLimit, that needs thorough examination and
|
||||
%% hopefully elimination. I'm adding it to try to
|
||||
%% make it more likely that someone's private proj
|
||||
%% will include all_flap_counts_settled,true 100%
|
||||
%% of the time. But I'm not sure how important that
|
||||
%% really is.
|
||||
%% That settled flag can lag behind after a change in
|
||||
%% network conditions, so I'm not sure how big its
|
||||
%% value is, if any.
|
||||
P_latest_trans_flap_count >= FlapLimit + 20 ->
|
||||
%% Everyone that's flapping together now has flap_count
|
||||
%% that's larger than the limit. So it's safe and good
|
||||
%% to stop here, so we can break the cycle of flapping.
|
||||
react_to_env_A50(P_latest, S);
|
||||
true ->
|
||||
react_to_env_C200(Retries, P_latest, S)
|
||||
|
||||
true ->
|
||||
%% It is our moral imperative to write so that the flap
|
||||
%% cycle continues enough times so that everyone notices
|
||||
%% and thus the earlier clause above fires.
|
||||
P_newprop2 = trim_proj_with_all_hosed(P_newprop, S),
|
||||
io:format(user, "GEE ~w\n", [self()]),
|
||||
io:format(user, "GEE1 ~w ~w\n", [self(), make_projection_summary(P_newprop)]),
|
||||
if P_newprop2#projection.upi == [] ->
|
||||
io:format(user, "GEE1-50 ~w ~w\n", [self(), make_projection_summary(P_newprop)]),
|
||||
?REACT({b10, ?LINE}),
|
||||
react_to_env_A50(P_latest, S);
|
||||
true ->
|
||||
io:format(user, "GEE1-300 newprop ~w ~w\n", [self(), make_projection_summary(P_newprop)]),
|
||||
io:format(user, "GEE1-300 latest ~w ~w\n", [self(), make_projection_summary(P_latest)]),
|
||||
?REACT({b10, ?LINE}),
|
||||
react_to_env_C300(P_newprop2, P_latest, S)
|
||||
end
|
||||
end;
|
||||
|
||||
Retries > 2 ->
|
||||
?REACT({b10, ?LINE}),
|
||||
put(b10_hack, false),
|
||||
|
||||
%% The author of P_latest is too slow or crashed.
|
||||
%% Let's try to write P_newprop and see what happens!
|
||||
|
|
@ -726,6 +831,7 @@ react_to_env_B10(Retries, P_newprop, P_latest, LatestUnanimousP,
|
|||
andalso
|
||||
P_latest#projection.author_server /= MyName ->
|
||||
?REACT({b10, ?LINE}),
|
||||
put(b10_hack, false),
|
||||
|
||||
%% Give the author of P_latest an opportunite to write a
|
||||
%% new projection in a new epoch to resolve this mixed
|
||||
|
|
@ -734,6 +840,7 @@ react_to_env_B10(Retries, P_newprop, P_latest, LatestUnanimousP,
|
|||
|
||||
true ->
|
||||
?REACT({b10, ?LINE}),
|
||||
put(b10_hack, false),
|
||||
|
||||
%% P_newprop is best, so let's write it.
|
||||
react_to_env_C300(P_newprop, P_latest, S)
|
||||
|
|
@ -781,8 +888,10 @@ react_to_env_C110(P_latest, #ch_mgr{myflu=MyFLU} = S) ->
|
|||
Islands = proplists:get_value(network_islands, RunEnv),
|
||||
P_latest2 = update_projection_dbg2(
|
||||
P_latest,
|
||||
[{network_islands, Islands},
|
||||
{hooray, {v2, date(), time()}}|Extra_todo]),
|
||||
[%% {network_islands, Islands},
|
||||
%% {hooray, {v2, date(), time()}}
|
||||
Islands--Islands
|
||||
|Extra_todo]),
|
||||
Epoch = P_latest2#projection.epoch_number,
|
||||
ok = machi_flu0:proj_write(MyFLU, Epoch, private, P_latest2),
|
||||
case proplists:get_value(private_write_verbose, S#ch_mgr.opts) of
|
||||
|
|
@ -790,7 +899,7 @@ react_to_env_C110(P_latest, #ch_mgr{myflu=MyFLU} = S) ->
|
|||
{_,_,C} = os:timestamp(),
|
||||
MSec = trunc(C / 1000),
|
||||
{HH,MM,SS} = time(),
|
||||
io:format(user, "~2..0w:~2..0w:~2..0w.~3..0w ~p uses: ~w\n",
|
||||
io:format(user, "\n~2..0w:~2..0w:~2..0w.~3..0w ~p uses: ~w\n",
|
||||
[HH,MM,SS,MSec, S#ch_mgr.name,
|
||||
make_projection_summary(P_latest2)]);
|
||||
_ ->
|
||||
|
|
@ -802,6 +911,10 @@ react_to_env_C120(P_latest, #ch_mgr{proj_history=H} = S) ->
|
|||
?REACT(c120),
|
||||
H2 = queue:in(P_latest, H),
|
||||
H3 = case queue:len(H2) of
|
||||
%% TODO: revisit this constant? Is this too long as a base?
|
||||
%% My hunch is that it's fine and that the flap_limit needs to
|
||||
%% be raised much higher (because it can increase several ticks
|
||||
%% without a newer public epoch proposed anywhere).
|
||||
X when X > length(P_latest#projection.all_members) * 2 ->
|
||||
{_V, Hxx} = queue:out(H2),
|
||||
Hxx;
|
||||
|
|
@ -842,29 +955,183 @@ react_to_env_C310(P_newprop, S) ->
|
|||
?REACT(c310),
|
||||
Epoch = P_newprop#projection.epoch_number,
|
||||
{_Res, S2} = cl_write_public_proj_skip_local_error(Epoch, P_newprop, S),
|
||||
io:format(user, "GEE3 ~w ~w epoch ~w ~w\n", [self(), S#ch_mgr.name, P_newprop#projection.epoch_number, _Res]),
|
||||
io:format(user, "GEE3 ~w ~w\n", [self(), make_projection_summary(P_newprop)]),
|
||||
HH = lists:sublist(get(react), 90),
|
||||
io:format(user, "GEE3 ~w ~p\n", [self(), lists:reverse(HH)]),
|
||||
?REACT({c310,make_projection_summary(P_newprop)}),
|
||||
?REACT({c310,_Res}),
|
||||
|
||||
react_to_env_A10(S2).
|
||||
|
||||
calculate_flaps(P_newprop, #ch_mgr{name=_MyName,
|
||||
proj_history=H, flaps=Flaps} = S) ->
|
||||
Ps = queue:to_list(H) ++ [P_newprop],
|
||||
UPI_Repairing_combos =
|
||||
lists:usort([{P#projection.upi, P#projection.repairing} || P <- Ps]),
|
||||
Down_combos = lists:usort([P#projection.down || P <- Ps]),
|
||||
case {queue:len(H), length(UPI_Repairing_combos), length(Down_combos)} of
|
||||
{N, _, _} when N < length(P_newprop#projection.all_members) ->
|
||||
S#ch_mgr{flaps=0};
|
||||
%% {_, URs=_URs, 1=_Ds} when URs < 3 ->
|
||||
{_, 1=_URs, 1=_Ds} ->
|
||||
%%%%%% io:format(user, "F{~w,~w,~w..~w}!", [_MyName, _URs, _Ds, Flaps]),
|
||||
S#ch_mgr{flaps=Flaps + 1};
|
||||
%% todo_flapping;
|
||||
_ ->
|
||||
S#ch_mgr{flaps=0}
|
||||
proposals_are_flapping(Ps) ->
|
||||
%% This works:
|
||||
%% UniqueProposalSummaries = lists:usort([{P#projection.upi,
|
||||
%% P#projection.repairing,
|
||||
%% P#projection.down} || P <- Ps]),
|
||||
%% length(UniqueProposalSummaries).
|
||||
%% ... but refactor to use a fold, for later refactoring ease.
|
||||
[First|Rest] = Ps,
|
||||
case lists:foldl(
|
||||
fun(#projection{upi=UPI,repairing=Repairing,down=Down}=NewP,
|
||||
#projection{upi=UPI,repairing=Repairing,down=Down}) ->
|
||||
NewP;
|
||||
(#projection{}=NewP,
|
||||
#projection{upi=UPIo,repairing=Repairingo}=_OldP) ->
|
||||
case get_flapping_hosed_compensation(NewP) of
|
||||
{NewUnadjUPI, NewUnadjRepairing} ->
|
||||
OK = case get_flapping_hosed_compensation(NewP) of
|
||||
{OldUnadjUPI, OldUnadjRepairing} ->
|
||||
OldUnadjUPI == NewUnadjUPI
|
||||
andalso
|
||||
OldUnadjRepairing == NewUnadjRepairing;
|
||||
_Else9 ->
|
||||
UPIo == NewUnadjUPI
|
||||
andalso
|
||||
Repairingo == NewUnadjRepairing
|
||||
end,
|
||||
if not OK ->
|
||||
bummer4;
|
||||
true ->
|
||||
NewP
|
||||
end;
|
||||
undefined ->
|
||||
bummer2;
|
||||
_Else ->
|
||||
bummer3
|
||||
end;
|
||||
(_, _Else) ->
|
||||
bummer
|
||||
end, First, Rest) of
|
||||
LastProj when is_record(LastProj, projection) ->
|
||||
1;
|
||||
_Else ->
|
||||
-1 % arbitrary, anything but 1
|
||||
end.
|
||||
|
||||
calculate_flaps(P_newprop, FlapLimit,
|
||||
#ch_mgr{name=MyName, proj_history=H,
|
||||
flaps=Flaps, runenv=RunEnv0} = S) ->
|
||||
Now = os:timestamp(),
|
||||
RunEnv1 = replace(RunEnv0, [{flapping_i, []}]),
|
||||
HistoryPs = queue:to_list(H),
|
||||
Ps = HistoryPs ++ [P_newprop],
|
||||
UniqueProposalSummaries = proposals_are_flapping(Ps),
|
||||
|
||||
{_WhateverUnanimous, BestP, Props, _S} =
|
||||
cl_read_latest_projection(private, S),
|
||||
NotBestPs = proplists:get_value(not_unanimous_answers, Props),
|
||||
DownUnion = lists:usort(
|
||||
lists:flatten(
|
||||
[P#projection.down ||
|
||||
P <- [BestP|NotBestPs]])),
|
||||
HosedTransUnion = proplists:get_value(trans_all_hosed, Props),
|
||||
TransFlapCounts0 = proplists:get_value(trans_all_flap_counts, Props),
|
||||
|
||||
_Unanimous = proplists:get_value(unanimous_flus, Props),
|
||||
_NotUnanimous = proplists:get_value(not_unanimous_flus, Props),
|
||||
%% NOTE: bad_answer_flus are probably due to timeout or some other network
|
||||
%% glitch, i.e., anything other than {ok, P::projection()}
|
||||
%% response from machi_flu0:proj_read_latest().
|
||||
BadFLUs = proplists:get_value(bad_answer_flus, Props),
|
||||
|
||||
RemoteTransFlapCounts1 = lists:keydelete(MyName, 1, TransFlapCounts0),
|
||||
RemoteTransFlapCounts =
|
||||
[X || {_FLU, {FlTime, _FlapCount}}=X <- RemoteTransFlapCounts1,
|
||||
FlTime /= ?NOT_FLAPPING],
|
||||
TempNewFlaps = Flaps + 1,
|
||||
TempAllFlapCounts = lists:sort([{MyName, {Now, TempNewFlaps}}|
|
||||
RemoteTransFlapCounts]),
|
||||
%% Sanity check.
|
||||
true = lists:all(fun({_,{_,_}}) -> true;
|
||||
(_) -> false end, TempAllFlapCounts),
|
||||
|
||||
%% H is the bounded history of all of this manager's private
|
||||
%% projection store writes. If we've proposed the *same*
|
||||
%% {UPI+Repairing, Down} combination for the entire length of our
|
||||
%% bounded size of H, then we're flapping.
|
||||
%%
|
||||
%% If we're flapping, then we use our own flap counter and that of
|
||||
%% all of our peer managers to see if we've all got flap counters
|
||||
%% that exceed the flap_limit. If that global condition appears
|
||||
%% true, then we "blow the circuit breaker" by stopping our
|
||||
%% participation in the flapping store (via the shortcut to A50).
|
||||
%%
|
||||
%% We reset our flap counter on any of several conditions:
|
||||
%%
|
||||
%% 1. If our bounded history H contains more than one proposal,
|
||||
%% then by definition we are not flapping.
|
||||
%% 2. If a remote manager is flapping and has re-started a new
|
||||
%% flapping episode.
|
||||
%% 3. If one of the remote managers that we saw earlier has
|
||||
%% stopped flapping.
|
||||
|
||||
case {queue:len(H), UniqueProposalSummaries} of
|
||||
{N, 1} when N >= length(P_newprop#projection.all_members) ->
|
||||
NewFlaps = TempNewFlaps,
|
||||
|
||||
%% Wow, this behavior is almost spooky.
|
||||
%%
|
||||
%% For an example partition map [{c,a}], on the very first
|
||||
%% time this 'if' clause is hit by FLU b, AllHosed=[a,c].
|
||||
%% How the heck does B know that??
|
||||
%%
|
||||
%% If I use:
|
||||
%% DownUnionQQQ = [{P#projection.epoch_number, P#projection.author_server, P#projection.down} || P <- [BestP|NotBestPs]],
|
||||
%% AllHosed = [x_1] ++ DownUnion ++ [x_2] ++ HosedTransUnion ++ [x_3] ++ BadFLUs ++ [{downunionqqq, DownUnionQQQ}];
|
||||
%%
|
||||
%% ... then b sees this when proposing epoch 451:
|
||||
%%
|
||||
%% {all_hosed,
|
||||
%% [x_1,a,c,x_2,x_3,
|
||||
%% {downunionqqq,
|
||||
%% [{450,a,[c]},{449,b,[]},{448,c,[a]},{441,d,[]}]}]},
|
||||
%%
|
||||
%% So b's working on epoch 451 at the same time that d's latest
|
||||
%% public projection is only epoch 441. But there's enough
|
||||
%% lag so that b can "see" that a's bad=[c] (due to t_timeout!)
|
||||
%% and c's bad=[a]. So voila, b magically knows about both
|
||||
%% problem FLUs. Weird/cool.
|
||||
|
||||
AllFlapCounts = TempAllFlapCounts,
|
||||
AllHosed = lists:usort(DownUnion ++ HosedTransUnion ++ BadFLUs);
|
||||
{_N, _} ->
|
||||
NewFlaps = 0,
|
||||
AllFlapCounts = [],
|
||||
AllHosed = []
|
||||
end,
|
||||
|
||||
%% If there's at least one count in AllFlapCounts that isn't my
|
||||
%% flap count, and if it's over the flap limit, then consider them
|
||||
%% settled.
|
||||
AllFlapCountsSettled = lists:keydelete(MyName, 1, AllFlapCounts) /= []
|
||||
andalso
|
||||
my_find_minmost(AllFlapCounts) >= FlapLimit,
|
||||
FlappingI = {flapping_i, [{flap_count, {Now, NewFlaps}},
|
||||
{all_hosed, AllHosed},
|
||||
{all_flap_counts, lists:sort(AllFlapCounts)},
|
||||
{all_flap_counts_settled, AllFlapCountsSettled},
|
||||
{bad,BadFLUs},
|
||||
{da_downu, DownUnion}, % debugging aid
|
||||
{da_hosedtu, HosedTransUnion}, % debugging aid
|
||||
{da_downreports, [{P#projection.epoch_number, P#projection.author_server, P#projection.down} || P <- [BestP|NotBestPs]]} % debugging aid
|
||||
]},
|
||||
Dbg2 = [FlappingI|P_newprop#projection.dbg],
|
||||
%% SLF TODO: 2015-03-04: I'm growing increasingly suspicious of
|
||||
%% the 'runenv' variable that's threaded through all this code.
|
||||
%% It isn't doing what I'd originally intended. And I think that
|
||||
%% the flapping information that we've just constructed here is
|
||||
%% going to get lost, and that's a shame. Fix it.
|
||||
RunEnv2 = replace(RunEnv1, [FlappingI]),
|
||||
%% NOTE: If we'd increment of flaps here, that doesn't mean that
|
||||
%% someone's public proj store has been updated. For example,
|
||||
%% if we loop through states C2xx a few times, we would incr
|
||||
%% flaps each time ... but the C2xx path doesn't write a new
|
||||
%% proposal to everyone's public proj stores, and there's no
|
||||
%% guarantee that anyone else as written a new public proj either.
|
||||
{update_projection_checksum(P_newprop#projection{dbg=Dbg2}),
|
||||
S#ch_mgr{flaps=NewFlaps, runenv=RunEnv2}}.
|
||||
|
||||
projection_transitions_are_sane(Ps, RelativeToServer) ->
|
||||
projection_transitions_are_sane(Ps, RelativeToServer, false).
|
||||
|
||||
|
|
@ -1134,6 +1401,82 @@ sleep_ranked_order(MinSleep, MaxSleep, FLU, FLU_list) ->
|
|||
timer:sleep(SleepTime),
|
||||
SleepTime.
|
||||
|
||||
my_find_minmost([]) ->
|
||||
0;
|
||||
my_find_minmost([{_,_}|_] = TransFlapCounts0) ->
|
||||
lists:min([FlapCount || {_T, {_FlTime, FlapCount}} <- TransFlapCounts0]);
|
||||
my_find_minmost(TransFlapCounts0) ->
|
||||
lists:min(TransFlapCounts0).
|
||||
|
||||
get_raw_flapping_i(#projection{dbg=Dbg}) ->
|
||||
proplists:get_value(flapping_i, Dbg, []).
|
||||
|
||||
get_flap_count(P) ->
|
||||
proplists:get_value(flap_count, get_raw_flapping_i(P), 0).
|
||||
|
||||
get_all_flap_counts(P) ->
|
||||
proplists:get_value(all_flap_counts, get_raw_flapping_i(P), []).
|
||||
|
||||
get_all_flap_counts_counts(P) ->
|
||||
case get_all_flap_counts(P) of
|
||||
[] ->
|
||||
[];
|
||||
[{_,{_,_}}|_] = Cs ->
|
||||
[Count || {_FLU, {_Time, Count}} <- Cs]
|
||||
end.
|
||||
|
||||
get_all_hosed(P) when is_record(P, projection)->
|
||||
proplists:get_value(all_hosed, get_raw_flapping_i(P), []);
|
||||
get_all_hosed(S) when is_record(S, ch_mgr) ->
|
||||
proplists:get_value(all_hosed,
|
||||
proplists:get_value(flapping_i, S#ch_mgr.runenv, []),
|
||||
[]).
|
||||
|
||||
get_flapping_hosed_compensation(P) ->
|
||||
proplists:get_value(hosed_compensation, get_raw_flapping_i(P),
|
||||
undefined).
|
||||
|
||||
merge_flap_counts(FlapCounts) ->
|
||||
merge_flap_counts(FlapCounts, orddict:new()).
|
||||
|
||||
merge_flap_counts([], D) ->
|
||||
orddict:to_list(D);
|
||||
merge_flap_counts([FlapCount|Rest], D1) ->
|
||||
%% We know that FlapCount is list({Actor, {FlapStartTime,NumFlaps}}).
|
||||
D2 = orddict:from_list(FlapCount),
|
||||
%% If the FlapStartTimes differ, then pick the larger start time tuple.
|
||||
D3 = orddict:merge(fun(_Key, {T1,_NF1}= V1, {T2,_NF2}=_V2)
|
||||
when T1 > T2 ->
|
||||
V1;
|
||||
(_Key, {_T1,_NF1}=_V1, {_T2,_NF2}= V2) ->
|
||||
V2;
|
||||
(_Key, V1, V2) ->
|
||||
exit({bad_merge_2tuples,mod,?MODULE,line,?LINE,
|
||||
_Key, V1, V2})
|
||||
end, D1, D2),
|
||||
merge_flap_counts(Rest, D3).
|
||||
|
||||
trim_proj_with_all_hosed(#projection{upi=UPI, repairing=Repairing,
|
||||
dbg=Dbg}=P, S) ->
|
||||
AllHosed = get_all_hosed(S),
|
||||
HosedComp = get_flapping_hosed_compensation(P),
|
||||
if AllHosed == [] orelse HosedComp /= undefined ->
|
||||
P;
|
||||
true ->
|
||||
UPI2 = UPI -- AllHosed,
|
||||
Repairing2 = Repairing -- AllHosed,
|
||||
X = if AllHosed /= [] ->
|
||||
Compensation = {hosed_compensation, {UPI, Repairing}},
|
||||
[Compensation, {now_all_hosed, AllHosed}];
|
||||
true ->
|
||||
[no_comp]
|
||||
end,
|
||||
FI = get_raw_flapping_i(P),
|
||||
Replace = [{flapping_i, X ++ FI}],
|
||||
DbgB = replace(Dbg, Replace),
|
||||
P#projection{upi=UPI2, repairing=Repairing2, dbg=DbgB}
|
||||
end.
|
||||
|
||||
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
||||
|
||||
perhaps_call_t(S, Partitions, FLU, DoIt) ->
|
||||
|
|
|
|||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_flu_test).
|
||||
|
||||
-ifdef(TEST).
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_pulse).
|
||||
|
||||
-ifdef(TEST).
|
||||
|
|
@ -477,9 +478,7 @@ check_trace(Trace0, _Cmds, _Seed) ->
|
|||
fun(x)-> [] end,
|
||||
Events),
|
||||
{_, _, Perhaps} = lists:last(eqc_temporal:all_future(PerhapsR)),
|
||||
%% ?QC_FMT("*Perhaps: ~p\n", [Perhaps]),
|
||||
_PerhapsLPNs = lists:sort([LPN || {perhaps, LPN, _} <- Perhaps]),
|
||||
%% ?QC_FMT("*_PerhapsLPNs: ~p\n", [_PerhapsLPNs]),
|
||||
%%?QC_FMT("*Perhaps: ~p\n", [Perhaps]),
|
||||
Reads = eqc_temporal:stateful(
|
||||
fun({call, Pid, {read, LPN, _, _}}) ->
|
||||
{read, Pid, LPN, []}
|
||||
|
|
@ -557,12 +556,13 @@ check_trace(Trace0, _Cmds, _Seed) ->
|
|||
InvalidTransitions == []},
|
||||
{no_bad_reads,
|
||||
eqc_temporal:is_false(eqc_temporal:all_future(BadReads))},
|
||||
%% If you want to see PULSE causing crazy scheduling, then
|
||||
%% change one of the "true orelse" -> "false orelse" below.
|
||||
%% {bogus_no_gaps,
|
||||
%% (_PerhapsLPNs == [] orelse length(range_ify(_PerhapsLPNs)) == 1)},
|
||||
%% true orelse
|
||||
%% (AppendLPNs == [] orelse length(range_ify(AppendLPNs)) == 1)},
|
||||
%% {bogus_exactly_1_to_N,
|
||||
%% (_PerhapsLPNs == lists:seq(1, length(_PerhapsLPNs)))},
|
||||
%% Do not remove the {true, true}, please. It should always be the
|
||||
%% last conjunction test.
|
||||
%% true orelse (AppendLPNs == lists:seq(1, length(AppendLPNs)))},
|
||||
{true, true}
|
||||
])).
|
||||
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_sequencer_test).
|
||||
|
||||
-compile(export_all).
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
%% -------------------------------------------------------------------
|
||||
%%
|
||||
%% Machi: a small village of replicated files
|
||||
%%
|
||||
%% Copyright (c) 2014 Basho Technologies, Inc. All Rights Reserved.
|
||||
%%
|
||||
%% This file is provided to you under the Apache License,
|
||||
|
|
@ -17,7 +19,6 @@
|
|||
%% under the License.
|
||||
%%
|
||||
%% -------------------------------------------------------------------
|
||||
|
||||
-module(corfurl_test).
|
||||
|
||||
-include("corfurl.hrl").
|
||||
|
|
@ -29,7 +29,6 @@
|
|||
-export([]).
|
||||
|
||||
-ifdef(TEST).
|
||||
-ifndef(PULSE).
|
||||
|
||||
-ifdef(EQC).
|
||||
-include_lib("eqc/include/eqc.hrl").
|
||||
|
|
@ -459,5 +458,4 @@ combinations(L) ->
|
|||
perms([]) -> [[]];
|
||||
perms(L) -> [[H|T] || H <- L, T <- perms(L--[H])].
|
||||
|
||||
-endif. % ! PULSE
|
||||
-endif.
|
||||
|
|
|
|||
|
|
@ -134,6 +134,19 @@ change_partitions(OldThreshold, NoPartitionThreshold) ->
|
|||
machi_partition_simulator:reset_thresholds(OldThreshold,
|
||||
NoPartitionThreshold).
|
||||
|
||||
always_last_partitions() ->
|
||||
machi_partition_simulator:always_last_partitions().
|
||||
|
||||
private_stable_check(FLUs) ->
|
||||
{_FLU_pids, Mgr_pids} = get(manager_pids_hack),
|
||||
Res = private_projections_are_stable_check(FLUs, Mgr_pids),
|
||||
if not Res ->
|
||||
io:format(user, "BUMMER: private stable check failed!\n", []);
|
||||
true ->
|
||||
ok
|
||||
end,
|
||||
Res.
|
||||
|
||||
do_ticks(Num, PidsMaybe, OldThreshold, NoPartitionThreshold) ->
|
||||
io:format(user, "~p,~p,~p|", [Num, OldThreshold, NoPartitionThreshold]),
|
||||
{_FLU_pids, Mgr_pids} = case PidsMaybe of
|
||||
|
|
@ -229,34 +242,38 @@ prop_pulse() ->
|
|||
%% doesn't always allow unanimous private projection store values:
|
||||
%% FLU a might need one more tick to write its private projection, but
|
||||
%% it isn't given a chance at the end of the PULSE run. So we cheat
|
||||
Stabilize1 = [{set,{var,99999995},
|
||||
{call, ?MODULE, always_last_partitions, []}}],
|
||||
Stabilize2 = [{set,{var,99999996},
|
||||
{call, ?MODULE, private_stable_check, [all_list()]}}],
|
||||
LastTriggerTicks = {set,{var,99999997},
|
||||
{call, ?MODULE, do_ticks, [25, undefined, no, no]}},
|
||||
Cmds1 = lists:duplicate(2, LastTriggerTicks),
|
||||
%% Cmds1 = lists:duplicate(length(all_list())*2, LastTriggerTicks),
|
||||
Cmds = Cmds0 ++
|
||||
Cmds1 ++ [{set,{var,99999999},
|
||||
{call, ?MODULE, dump_state, []}}],
|
||||
Stabilize1 ++
|
||||
Cmds1 ++
|
||||
Stabilize2 ++
|
||||
[{set,{var,99999999}, {call, ?MODULE, dump_state, []}}],
|
||||
{_H2, S2, Res} = pulse:run(
|
||||
fun() ->
|
||||
{_H, _S, _R} = run_commands(?MODULE, Cmds)
|
||||
end, [{seed, Seed},
|
||||
{strategy, unfair}]),
|
||||
%% {FLU_pids, Mgr_pids} = S2#state.pids,
|
||||
%% [ok = machi_flu0:stop(FLU) || FLU <- FLU_pids],
|
||||
%% [ok = ?MGR:stop(Mgr) || Mgr <- Mgr_pids],
|
||||
ok = shutdown_hard(),
|
||||
|
||||
%% ?QC_FMT("Cmds ~p\n", [Cmds]),
|
||||
%% ?QC_FMT("H2 ~p\n", [_H2]),
|
||||
%% ?QC_FMT("S2 ~p\n", [S2]),
|
||||
{Report, Diag} = S2#state.dump_state,
|
||||
%% ?QC_FMT("\nLast report = ~p\n", [lists:last(Report)]),
|
||||
|
||||
%% Report is ordered by Epoch. For each private projection
|
||||
%% written during any given epoch, confirm that all chain
|
||||
%% members appear in only one unique chain, i.e., the sets of
|
||||
%% unique chains are disjoint.
|
||||
AllDisjointP = ?MGRTEST:all_reports_are_disjoint(Report),
|
||||
|
||||
%% Given the report, we flip it around so that we observe the
|
||||
%% sets of chain transitions relative to each FLU.
|
||||
R_Chains = [?MGRTEST:extract_chains_relative_to_flu(FLU, Report) ||
|
||||
FLU <- all_list()],
|
||||
%% ?D(R_Chains),
|
||||
R_Projs = [{FLU, [?MGRTEST:chain_to_projection(
|
||||
FLU, Epoch, UPI, Repairing, all_list()) ||
|
||||
{Epoch, UPI, Repairing} <- E_Chains]} ||
|
||||
|
|
@ -268,16 +285,11 @@ prop_pulse() ->
|
|||
[{FLU,_SaneRes} = {FLU,?MGR:projection_transitions_are_sane_retrospective(
|
||||
Ps, FLU)} ||
|
||||
{FLU, Ps} <- R_Projs],
|
||||
%% ?QC_FMT("Sane ~p\n", [Sane]),
|
||||
SaneP = lists:all(fun({_FLU, SaneRes}) -> SaneRes == true end, Sane),
|
||||
|
||||
%% The final report item should say that all are agreed_membership.
|
||||
{_LastEpoch, {ok_disjoint, LastRepXs}} = lists:last(Report),
|
||||
%% ?QC_FMT("LastEpoch=~p,", [_LastEpoch]),
|
||||
%% ?QC_FMT("Report ~P\n", [Report, 5000]),
|
||||
%% ?QC_FMT("Diag ~s\n", [Diag]),
|
||||
AgreedOrNot = lists:usort([element(1, X) || X <- LastRepXs]),
|
||||
%% ?QC_FMT("LastRepXs ~p", [LastRepXs]),
|
||||
|
||||
%% TODO: Check that we've converged to a single chain with no repairs.
|
||||
SingleChainNoRepair = case LastRepXs of
|
||||
|
|
@ -296,7 +308,7 @@ prop_pulse() ->
|
|||
?QC_FMT("SingleChainNoRepair failure =\n ~p\n", [SingleChainNoRepair])
|
||||
end,
|
||||
conjunction([{res, Res == true orelse Res == ok},
|
||||
{all_disjoint, ?MGRTEST:all_reports_are_disjoint(Report)},
|
||||
{all_disjoint, AllDisjointP},
|
||||
{sane, SaneP},
|
||||
{all_agreed_at_end, AgreedOrNot == [agreed_membership]},
|
||||
{single_chain_no_repair, SingleChainNoRepair}
|
||||
|
|
@ -329,7 +341,7 @@ shutdown_hard() ->
|
|||
|
||||
exec_ticks(Num, Mgr_pids) ->
|
||||
Parent = self(),
|
||||
Pids = [spawn(fun() ->
|
||||
Pids = [spawn_link(fun() ->
|
||||
[begin
|
||||
erlang:yield(),
|
||||
Max = 10,
|
||||
|
|
@ -349,4 +361,19 @@ exec_ticks(Num, Mgr_pids) ->
|
|||
end || _ <- Pids],
|
||||
ok.
|
||||
|
||||
private_projections_are_stable_check(All_list, Mgr_pids) ->
|
||||
%% TODO: extend the check to look not only for latest num, but
|
||||
%% also check for flapping, and if yes, to see if all_hosed are
|
||||
%% all exactly equal.
|
||||
|
||||
_ = exec_ticks(40, Mgr_pids),
|
||||
Private1 = [machi_flu0:proj_get_latest_num(FLU, private) ||
|
||||
FLU <- All_list],
|
||||
_ = exec_ticks(5, Mgr_pids),
|
||||
Private2 = [machi_flu0:proj_get_latest_num(FLU, private) ||
|
||||
FLU <- All_list],
|
||||
|
||||
(Private1 == Private2).
|
||||
|
||||
|
||||
-endif. % PULSE
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@
|
|||
-define(D(X), io:format(user, "~s ~p\n", [??X, X])).
|
||||
-define(Dw(X), io:format(user, "~s ~w\n", [??X, X])).
|
||||
|
||||
-export([unanimous_report/1, unanimous_report/2]).
|
||||
-export([]).
|
||||
|
||||
-ifdef(TEST).
|
||||
|
||||
|
|
@ -42,243 +42,6 @@
|
|||
-include_lib("eunit/include/eunit.hrl").
|
||||
-compile(export_all).
|
||||
|
||||
-ifndef(PULSE).
|
||||
|
||||
smoke0_test() ->
|
||||
machi_partition_simulator:start_link({1,2,3}, 50, 50),
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, M0} = ?MGR:start_link(a, [a,b,c], a),
|
||||
try
|
||||
pong = ?MGR:ping(M0),
|
||||
|
||||
%% If/when calculate_projection_internal_old() disappears, then
|
||||
%% get rid of the comprehension below ... start/ping/stop is
|
||||
%% good enough for smoke0.
|
||||
io:format(user, "\n\nBegin 5 lines of verbose stuff, check manually for differences\n", []),
|
||||
[begin
|
||||
Proj = ?MGR:calculate_projection_internal_old(M0),
|
||||
io:format(user, "~w\n", [?MGR:make_projection_summary(Proj)])
|
||||
end || _ <- lists:seq(1,5)],
|
||||
io:format(user, "\n", [])
|
||||
after
|
||||
ok = ?MGR:stop(M0),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
smoke1_test() ->
|
||||
machi_partition_simulator:start_link({1,2,3}, 100, 0),
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, FLUb} = machi_flu0:start_link(b),
|
||||
{ok, FLUc} = machi_flu0:start_link(c),
|
||||
I_represent = I_am = a,
|
||||
{ok, M0} = ?MGR:start_link(I_represent, [a,b,c], I_am),
|
||||
try
|
||||
{ok, _P1} = ?MGR:test_calc_projection(M0, false),
|
||||
|
||||
_ = ?MGR:test_calc_proposed_projection(M0),
|
||||
{remote_write_results,
|
||||
[{b,ok},{c,ok}]} = ?MGR:test_write_proposed_projection(M0),
|
||||
{unanimous, P1, Extra1} = ?MGR:test_read_latest_public_projection(M0, false),
|
||||
|
||||
ok
|
||||
after
|
||||
ok = ?MGR:stop(M0),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_flu0:stop(FLUb),
|
||||
ok = machi_flu0:stop(FLUc),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
nonunanimous_setup_and_fix_test() ->
|
||||
machi_partition_simulator:start_link({1,2,3}, 100, 0),
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, FLUb} = machi_flu0:start_link(b),
|
||||
I_represent = I_am = a,
|
||||
{ok, Ma} = ?MGR:start_link(I_represent, [a,b], I_am),
|
||||
{ok, Mb} = ?MGR:start_link(b, [a,b], b),
|
||||
try
|
||||
{ok, P1} = ?MGR:test_calc_projection(Ma, false),
|
||||
|
||||
P1a = ?MGR:update_projection_checksum(
|
||||
P1#projection{down=[b], upi=[a], dbg=[{hackhack, ?LINE}]}),
|
||||
P1b = ?MGR:update_projection_checksum(
|
||||
P1#projection{author_server=b, creation_time=now(),
|
||||
down=[a], upi=[b], dbg=[{hackhack, ?LINE}]}),
|
||||
P1Epoch = P1#projection.epoch_number,
|
||||
ok = machi_flu0:proj_write(FLUa, P1Epoch, public, P1a),
|
||||
ok = machi_flu0:proj_write(FLUb, P1Epoch, public, P1b),
|
||||
|
||||
%% ?D(x),
|
||||
{not_unanimous,_,_}=_XX = ?MGR:test_read_latest_public_projection(Ma, false),
|
||||
%% ?Dw(_XX),
|
||||
{not_unanimous,_,_}=_YY = ?MGR:test_read_latest_public_projection(Ma, true),
|
||||
%% The read repair here doesn't automatically trigger the creation of
|
||||
%% a new projection (to try to create a unanimous projection). So
|
||||
%% we expect nothing to change when called again.
|
||||
{not_unanimous,_,_}=_YY = ?MGR:test_read_latest_public_projection(Ma, true),
|
||||
|
||||
{now_using, _} = ?MGR:test_react_to_env(Ma),
|
||||
{unanimous,P2,E2} = ?MGR:test_read_latest_public_projection(Ma, false),
|
||||
{ok, P2pa} = machi_flu0:proj_read_latest(FLUa, private),
|
||||
P2 = P2pa#projection{dbg2=[]},
|
||||
|
||||
%% FLUb should still be using proj #0 for its private use
|
||||
{ok, P0pb} = machi_flu0:proj_read_latest(FLUb, private),
|
||||
0 = P0pb#projection.epoch_number,
|
||||
|
||||
%% Poke FLUb to react ... should be using the same private proj
|
||||
%% as FLUa.
|
||||
{now_using, _} = ?MGR:test_react_to_env(Mb),
|
||||
{ok, P2pb} = machi_flu0:proj_read_latest(FLUb, private),
|
||||
P2 = P2pb#projection{dbg2=[]},
|
||||
|
||||
ok
|
||||
after
|
||||
ok = ?MGR:stop(Ma),
|
||||
ok = ?MGR:stop(Mb),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_flu0:stop(FLUb),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
%% This test takes a long time and spits out a huge amount of logging
|
||||
%% cruft to the console. Comment out the EUnit fixture and run manually.
|
||||
|
||||
%% convergence_demo_test_() ->
|
||||
%% {timeout, 300, fun() -> convergence_demo1() end}.
|
||||
|
||||
convergence_demo1() ->
|
||||
All_list = [a,b,c,d],
|
||||
%% machi_partition_simulator:start_link({111,222,33}, 0, 100),
|
||||
Seed = erlang:now(),
|
||||
machi_partition_simulator:start_link(Seed, 0, 100),
|
||||
io:format(user, "convergence_demo seed = ~p\n", [Seed]),
|
||||
_ = machi_partition_simulator:get(All_list),
|
||||
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, FLUb} = machi_flu0:start_link(b),
|
||||
{ok, FLUc} = machi_flu0:start_link(c),
|
||||
{ok, FLUd} = machi_flu0:start_link(d),
|
||||
Namez = [{a, FLUa}, {b, FLUb}, {c, FLUc}, {d, FLUd}],
|
||||
I_represent = I_am = a,
|
||||
MgrOpts = [private_write_verbose],
|
||||
{ok, Ma} = ?MGR:start_link(I_represent, All_list, I_am, MgrOpts),
|
||||
{ok, Mb} = ?MGR:start_link(b, All_list, b, MgrOpts),
|
||||
{ok, Mc} = ?MGR:start_link(c, All_list, c, MgrOpts),
|
||||
{ok, Md} = ?MGR:start_link(d, All_list, d, MgrOpts),
|
||||
try
|
||||
{ok, P1} = ?MGR:test_calc_projection(Ma, false),
|
||||
P1Epoch = P1#projection.epoch_number,
|
||||
ok = machi_flu0:proj_write(FLUa, P1Epoch, public, P1),
|
||||
ok = machi_flu0:proj_write(FLUb, P1Epoch, public, P1),
|
||||
ok = machi_flu0:proj_write(FLUc, P1Epoch, public, P1),
|
||||
ok = machi_flu0:proj_write(FLUd, P1Epoch, public, P1),
|
||||
|
||||
{now_using, XX1} = ?MGR:test_react_to_env(Ma),
|
||||
?D(XX1),
|
||||
{now_using, _} = ?MGR:test_react_to_env(Mb),
|
||||
{now_using, _} = ?MGR:test_react_to_env(Mc),
|
||||
{QQ,QQP2,QQE2} = ?MGR:test_read_latest_public_projection(Ma, false),
|
||||
?D(QQ),
|
||||
?Dw(?MGR:make_projection_summary(QQP2)),
|
||||
?D(QQE2),
|
||||
%% {unanimous,P2,E2} = test_read_latest_public_projection(Ma, false),
|
||||
|
||||
machi_partition_simulator:reset_thresholds(10, 50),
|
||||
_ = machi_partition_simulator:get(All_list),
|
||||
|
||||
Parent = self(),
|
||||
DoIt = fun(Iters, S_min, S_max) ->
|
||||
Pids = [spawn(fun() ->
|
||||
[begin
|
||||
erlang:yield(),
|
||||
Elapsed =
|
||||
?MGR:sleep_ranked_order(S_min, S_max, M_name, All_list),
|
||||
Res = ?MGR:test_react_to_env(MMM),
|
||||
timer:sleep(S_max - Elapsed),
|
||||
Res=Res %% ?D({self(), Res})
|
||||
end || _ <- lists:seq(1, Iters)],
|
||||
Parent ! done
|
||||
end) || {M_name, MMM} <- [{a, Ma},
|
||||
{b, Mb},
|
||||
{c, Mc},
|
||||
{d, Md}] ],
|
||||
[receive
|
||||
done ->
|
||||
ok
|
||||
after 995000 ->
|
||||
exit(icky_timeout)
|
||||
end || _ <- Pids]
|
||||
end,
|
||||
|
||||
DoIt(30, 0, 0),
|
||||
io:format(user, "\nSET always_last_partitions ON ... we should see convergence to correct chains.\n", []),
|
||||
%% machi_partition_simulator:always_these_partitions([{b,a}]),
|
||||
machi_partition_simulator:always_these_partitions([{a,b}]),
|
||||
%% machi_partition_simulator:always_these_partitions([{b,c}]),
|
||||
%% machi_partition_simulator:always_these_partitions([{a,c},{c,b}]),
|
||||
%% machi_partition_simulator:always_last_partitions(),
|
||||
[DoIt(25, 40, 400) || _ <- [1]],
|
||||
%% TODO: We should be stable now ... analyze it.
|
||||
|
||||
io:format(user, "\nSET always_last_partitions OFF ... let loose the dogs of war!\n", []),
|
||||
machi_partition_simulator:reset_thresholds(10, 50),
|
||||
DoIt(30, 0, 0),
|
||||
io:format(user, "\nSET always_last_partitions ON ... we should see convergence to correct chains2.\n", []),
|
||||
%% machi_partition_simulator:always_last_partitions(),
|
||||
machi_partition_simulator:always_these_partitions([{a,c}]),
|
||||
[DoIt(25, 40, 400) || _ <- [1]],
|
||||
|
||||
io:format(user, "\nSET always_last_partitions ON ... we should see convergence to correct chains3.\n", []),
|
||||
machi_partition_simulator:no_partitions(),
|
||||
[DoIt(20, 40, 400) || _ <- [1]],
|
||||
%% TODO: We should be stable now ... analyze it.
|
||||
io:format(user, "~s\n", [os:cmd("date")]),
|
||||
|
||||
%% Create a report where at least one FLU has written a
|
||||
%% private projection.
|
||||
Report = unanimous_report(Namez),
|
||||
%% ?D(Report),
|
||||
|
||||
%% Report is ordered by Epoch. For each private projection
|
||||
%% written during any given epoch, confirm that all chain
|
||||
%% members appear in only one unique chain, i.e., the sets of
|
||||
%% unique chains are disjoint.
|
||||
true = all_reports_are_disjoint(Report),
|
||||
|
||||
%% Given the report, we flip it around so that we observe the
|
||||
%% sets of chain transitions relative to each FLU.
|
||||
R_Chains = [extract_chains_relative_to_flu(FLU, Report) ||
|
||||
FLU <- All_list],
|
||||
%% ?D(R_Chains),
|
||||
R_Projs = [{FLU, [chain_to_projection(FLU, Epoch, UPI, Repairing,
|
||||
All_list) ||
|
||||
{Epoch, UPI, Repairing} <- E_Chains]} ||
|
||||
{FLU, E_Chains} <- R_Chains],
|
||||
|
||||
%% For each chain transition experienced by a particular FLU,
|
||||
%% confirm that each state transition is OK.
|
||||
try
|
||||
[{FLU, true} = {FLU, ?MGR:projection_transitions_are_sane(Ps, FLU)} ||
|
||||
{FLU, Ps} <- R_Projs]
|
||||
catch _Err:_What ->
|
||||
io:format(user, "Report ~p\n", [Report]),
|
||||
exit({line, ?LINE, _Err, _What})
|
||||
end,
|
||||
%% ?D(R_Projs),
|
||||
|
||||
ok
|
||||
after
|
||||
ok = ?MGR:stop(Ma),
|
||||
ok = ?MGR:stop(Mb),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_flu0:stop(FLUb),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
-endif. % not PULSE
|
||||
|
||||
unanimous_report(Namez) ->
|
||||
UniquePrivateEs =
|
||||
lists:usort(lists:flatten(
|
||||
|
|
@ -366,4 +129,382 @@ chain_to_projection(MyName, Epoch, UPI_list, Repairing_list, All_list) ->
|
|||
All_list -- (UPI_list ++ Repairing_list),
|
||||
UPI_list, Repairing_list, []).
|
||||
|
||||
-ifndef(PULSE).
|
||||
|
||||
smoke0_test() ->
|
||||
machi_partition_simulator:start_link({1,2,3}, 50, 50),
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, M0} = ?MGR:start_link(a, [a,b,c], a),
|
||||
try
|
||||
pong = ?MGR:ping(M0),
|
||||
|
||||
%% If/when calculate_projection_internal_old() disappears, then
|
||||
%% get rid of the comprehension below ... start/ping/stop is
|
||||
%% good enough for smoke0.
|
||||
[begin
|
||||
Proj = ?MGR:calculate_projection_internal_old(M0),
|
||||
io:format(user, "~w\n", [?MGR:make_projection_summary(Proj)])
|
||||
end || _ <- lists:seq(1,5)]
|
||||
after
|
||||
ok = ?MGR:stop(M0),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
smoke1_test() ->
|
||||
machi_partition_simulator:start_link({1,2,3}, 100, 0),
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, FLUb} = machi_flu0:start_link(b),
|
||||
{ok, FLUc} = machi_flu0:start_link(c),
|
||||
I_represent = I_am = a,
|
||||
{ok, M0} = ?MGR:start_link(I_represent, [a,b,c], I_am),
|
||||
try
|
||||
{ok, _P1} = ?MGR:test_calc_projection(M0, false),
|
||||
|
||||
_ = ?MGR:test_calc_proposed_projection(M0),
|
||||
{remote_write_results,
|
||||
[{b,ok},{c,ok}]} = ?MGR:test_write_proposed_projection(M0),
|
||||
{unanimous, P1, Extra1} = ?MGR:test_read_latest_public_projection(M0, false),
|
||||
|
||||
ok
|
||||
after
|
||||
ok = ?MGR:stop(M0),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_flu0:stop(FLUb),
|
||||
ok = machi_flu0:stop(FLUc),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
nonunanimous_setup_and_fix_test() ->
|
||||
machi_partition_simulator:start_link({1,2,3}, 100, 0),
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, FLUb} = machi_flu0:start_link(b),
|
||||
I_represent = I_am = a,
|
||||
{ok, Ma} = ?MGR:start_link(I_represent, [a,b], I_am),
|
||||
{ok, Mb} = ?MGR:start_link(b, [a,b], b),
|
||||
try
|
||||
{ok, P1} = ?MGR:test_calc_projection(Ma, false),
|
||||
|
||||
P1a = ?MGR:update_projection_checksum(
|
||||
P1#projection{down=[b], upi=[a], dbg=[{hackhack, ?LINE}]}),
|
||||
P1b = ?MGR:update_projection_checksum(
|
||||
P1#projection{author_server=b, creation_time=now(),
|
||||
down=[a], upi=[b], dbg=[{hackhack, ?LINE}]}),
|
||||
P1Epoch = P1#projection.epoch_number,
|
||||
ok = machi_flu0:proj_write(FLUa, P1Epoch, public, P1a),
|
||||
ok = machi_flu0:proj_write(FLUb, P1Epoch, public, P1b),
|
||||
|
||||
?D(x),
|
||||
{not_unanimous,_,_}=_XX = ?MGR:test_read_latest_public_projection(Ma, false),
|
||||
?Dw(_XX),
|
||||
{not_unanimous,_,_}=_YY = ?MGR:test_read_latest_public_projection(Ma, true),
|
||||
%% The read repair here doesn't automatically trigger the creation of
|
||||
%% a new projection (to try to create a unanimous projection). So
|
||||
%% we expect nothing to change when called again.
|
||||
{not_unanimous,_,_}=_YY = ?MGR:test_read_latest_public_projection(Ma, true),
|
||||
|
||||
{now_using, _} = ?MGR:test_react_to_env(Ma),
|
||||
{unanimous,P2,E2} = ?MGR:test_read_latest_public_projection(Ma, false),
|
||||
{ok, P2pa} = machi_flu0:proj_read_latest(FLUa, private),
|
||||
P2 = P2pa#projection{dbg2=[]},
|
||||
|
||||
%% FLUb should still be using proj #0 for its private use
|
||||
{ok, P0pb} = machi_flu0:proj_read_latest(FLUb, private),
|
||||
0 = P0pb#projection.epoch_number,
|
||||
|
||||
%% Poke FLUb to react ... should be using the same private proj
|
||||
%% as FLUa.
|
||||
{now_using, _} = ?MGR:test_react_to_env(Mb),
|
||||
{ok, P2pb} = machi_flu0:proj_read_latest(FLUb, private),
|
||||
P2 = P2pb#projection{dbg2=[]},
|
||||
|
||||
ok
|
||||
after
|
||||
ok = ?MGR:stop(Ma),
|
||||
ok = ?MGR:stop(Mb),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_flu0:stop(FLUb),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
short_doc() ->
|
||||
"
|
||||
A visualization of the convergence behavior of the chain self-management
|
||||
algorithm for Machi.
|
||||
1. Set up 4 FLUs and chain manager pairs.
|
||||
2. Create a number of different network partition scenarios, where
|
||||
(simulated) partitions may be symmetric or asymmetric. Then halt changing
|
||||
the partitions and keep the simulated network stable and broken.
|
||||
3. Run a number of iterations of the algorithm in parallel by poking each
|
||||
of the manager processes on a random'ish basis.
|
||||
4. Afterward, fetch the chain transition changes made by each FLU and
|
||||
verify that no transition was unsafe.
|
||||
|
||||
During the iteration periods, the following is a cheatsheet for the output.
|
||||
See the internal source for interpreting the rest of the output.
|
||||
|
||||
'Let loose the dogs of war!' Network instability
|
||||
'SET partitions = ' Network stability (but broken)
|
||||
'x uses:' The FLU x has made an internal state transition. The rest of
|
||||
the line is a dump of internal state.
|
||||
'{t}' This is a tick event which triggers one of the manager processes
|
||||
to evaluate its environment and perhaps make a state transition.
|
||||
|
||||
A long chain of '{t}{t}{t}{t}' means that the chain state has settled
|
||||
to a stable configuration, which is the goal of the algorithm.
|
||||
Press control-c to interrupt....".
|
||||
|
||||
long_doc() ->
|
||||
"
|
||||
'Let loose the dogs of war!'
|
||||
|
||||
The simulated network is very unstable for a few seconds.
|
||||
|
||||
'x uses'
|
||||
|
||||
After a single iteration, server x has determined that the chain
|
||||
should be defined by the upi, repair, and down list in this record.
|
||||
If all participants reach the same conclusion at the same epoch
|
||||
number (and checksum, see next item below), then the chain is
|
||||
stable, fully configured, and can provide full service.
|
||||
|
||||
'epoch,E'
|
||||
|
||||
The epoch number for this decision is E. The checksum of the full
|
||||
record is not shown. For purposes of the protocol, a server will
|
||||
'wedge' itself and refuse service (until a new config is chosen)
|
||||
whenever: a). it sees a bigger epoch number mentioned somewhere, or
|
||||
b). it sees the same epoch number but a different checksum. In case
|
||||
of b), there was a network partition that has healed, and both sides
|
||||
had chosen to operate with an identical epoch number but different
|
||||
chain configs.
|
||||
|
||||
'upi', 'repair', and 'down'
|
||||
|
||||
Members in the chain that are fully in sync and thus preserving the
|
||||
Update Propagation Invariant, up but under repair (simulated), and
|
||||
down, respectively.
|
||||
|
||||
'ps,[some list]'
|
||||
|
||||
The list of asymmetric network partitions. {a,b} means that a
|
||||
cannot send to b, but b can send to a.
|
||||
|
||||
This partition list is recorded for debugging purposes but is *not*
|
||||
used by the algorithm. The algorithm only 'feels' its effects via
|
||||
simulated timeout whenever there's a partition in one of the
|
||||
messaging directions.
|
||||
|
||||
'nodes_up,[list]'
|
||||
|
||||
The best guess right now of which ndoes are up, relative to the
|
||||
author node, specified by '{author,X}'
|
||||
|
||||
'SET partitions = [some list]'
|
||||
|
||||
All subsequent iterations should have a stable list of partitions,
|
||||
i.e. the 'ps' list described should be stable.
|
||||
|
||||
'{FLAP: x flaps n}!'
|
||||
|
||||
Server x has detected that it's flapping/oscillating after iteration
|
||||
n of a naive/1st draft detection algorithm.
|
||||
".
|
||||
|
||||
convergence_demo_test_() ->
|
||||
{timeout, 98*300, fun() -> convergence_demo_test(x) end}.
|
||||
|
||||
convergence_demo_test(_) ->
|
||||
timer:sleep(100),
|
||||
io:format(user, short_doc(), []),
|
||||
timer:sleep(3000),
|
||||
|
||||
All_list = [a,b,c,d],
|
||||
machi_partition_simulator:start_link({111,222,33}, 0, 100),
|
||||
_ = machi_partition_simulator:get(All_list),
|
||||
|
||||
{ok, FLUa} = machi_flu0:start_link(a),
|
||||
{ok, FLUb} = machi_flu0:start_link(b),
|
||||
{ok, FLUc} = machi_flu0:start_link(c),
|
||||
{ok, FLUd} = machi_flu0:start_link(d),
|
||||
Namez = [{a, FLUa}, {b, FLUb}, {c, FLUc}, {d, FLUd}],
|
||||
I_represent = I_am = a,
|
||||
MgrOpts = [private_write_verbose],
|
||||
{ok, Ma} = ?MGR:start_link(I_represent, All_list, I_am, MgrOpts),
|
||||
{ok, Mb} = ?MGR:start_link(b, All_list, b, MgrOpts),
|
||||
{ok, Mc} = ?MGR:start_link(c, All_list, c, MgrOpts),
|
||||
{ok, Md} = ?MGR:start_link(d, All_list, d, MgrOpts),
|
||||
try
|
||||
{ok, P1} = ?MGR:test_calc_projection(Ma, false),
|
||||
P1Epoch = P1#projection.epoch_number,
|
||||
ok = machi_flu0:proj_write(FLUa, P1Epoch, public, P1),
|
||||
ok = machi_flu0:proj_write(FLUb, P1Epoch, public, P1),
|
||||
ok = machi_flu0:proj_write(FLUc, P1Epoch, public, P1),
|
||||
ok = machi_flu0:proj_write(FLUd, P1Epoch, public, P1),
|
||||
|
||||
machi_partition_simulator:reset_thresholds(10, 50),
|
||||
_ = machi_partition_simulator:get(All_list),
|
||||
|
||||
Parent = self(),
|
||||
DoIt = fun(Iters, S_min, S_max) ->
|
||||
io:format(user, "\nDoIt: top\n\n", []),
|
||||
Pids = [spawn(fun() ->
|
||||
random:seed(now()),
|
||||
[begin
|
||||
erlang:yield(),
|
||||
S_max_rand = random:uniform(
|
||||
S_max + 1),
|
||||
io:format(user, "{t}", []),
|
||||
Elapsed =
|
||||
?MGR:sleep_ranked_order(
|
||||
S_min, S_max_rand,
|
||||
M_name, All_list),
|
||||
_ = ?MGR:test_react_to_env(MMM),
|
||||
%% Be more unfair by not
|
||||
%% sleeping here.
|
||||
%% timer:sleep(S_max - Elapsed),
|
||||
Elapsed
|
||||
end || _ <- lists:seq(1, Iters)],
|
||||
Parent ! done
|
||||
end) || {M_name, MMM} <- [{a, Ma},
|
||||
{b, Mb},
|
||||
{c, Mc},
|
||||
{d, Md}] ],
|
||||
[receive
|
||||
done ->
|
||||
ok
|
||||
after 995000 ->
|
||||
exit(icky_timeout)
|
||||
end || _ <- Pids]
|
||||
end,
|
||||
|
||||
XandYs1 = [[{X,Y}] || X <- All_list, Y <- All_list, X /= Y],
|
||||
XandYs2 = [[{X,Y}, {A,B}] || X <- All_list, Y <- All_list, X /= Y,
|
||||
A <- All_list, B <- All_list, A /= B,
|
||||
X /= A],
|
||||
%% XandYs3 = [[{X,Y}, {A,B}, {C,D}] || X <- All_list, Y <- All_list, X /= Y,
|
||||
%% A <- All_list, B <- All_list, A /= B,
|
||||
%% C <- All_list, D <- All_list, C /= D,
|
||||
%% X /= A, X /= C, A /= C],
|
||||
AllPartitionCombinations = XandYs1 ++ XandYs2,
|
||||
%% AllPartitionCombinations = XandYs3,
|
||||
?D({?LINE, length(AllPartitionCombinations)}),
|
||||
|
||||
machi_partition_simulator:reset_thresholds(10, 50),
|
||||
io:format(user, "\nLet loose the dogs of war!\n", []),
|
||||
DoIt(30, 0, 0),
|
||||
[begin
|
||||
%% machi_partition_simulator:reset_thresholds(10, 50),
|
||||
%% io:format(user, "\nLet loose the dogs of war!\n", []),
|
||||
%% DoIt(30, 0, 0),
|
||||
machi_partition_simulator:always_these_partitions(Partition),
|
||||
io:format(user, "\nSET partitions = ~w.\n", [Partition]),
|
||||
[DoIt(50, 10, 100) || _ <- [1,2,3,4] ],
|
||||
true = private_projections_are_stable(Namez, DoIt),
|
||||
true = all_hosed_lists_are_identical(Namez, Partition),
|
||||
io:format(user, "\nSweet, we converged & all_hosed are unanimous-or-islands-inconclusive.\n", []),
|
||||
%% PPP =
|
||||
%% [begin
|
||||
%% PPPallPubs = machi_flu0:proj_list_all(FLU, public),
|
||||
%% [begin
|
||||
%% {ok, Pr} = machi_flu0:proj_read(FLU, PPPepoch, public),
|
||||
%% {Pr#projection.epoch_number, FLUName, Pr}
|
||||
%% end || PPPepoch <- PPPallPubs]
|
||||
%% end || {FLUName, FLU} <- Namez],
|
||||
%% io:format(user, "PPP ~p\n", [lists:sort(lists:append(PPP))]),
|
||||
timer:sleep(1000),
|
||||
ok
|
||||
end || Partition <- AllPartitionCombinations
|
||||
%% end || Partition <- [ [{c,a}] ]
|
||||
%% end || Partition <- [ [{c,a}], [{c,b}, {a, b}] ]
|
||||
%% end || Partition <- [ [{a,b},{b,a}, {a,c},{c,a}, {a,d},{d,a}],
|
||||
%% [{a,b},{b,a}, {a,c},{c,a}, {a,d},{d,a}, {b,c}],
|
||||
%% [{a,b},{b,a}, {a,c},{c,a}, {a,d},{d,a}, {c,d}] ]
|
||||
],
|
||||
%% exit(end_experiment),
|
||||
|
||||
io:format(user, "\nSET partitions = []\n", []),
|
||||
io:format(user, "Sweet, finishing early\n", []), exit(yoyoyo_testing_hack),
|
||||
io:format(user, "We should see convergence to 1 correct chain.\n", []),
|
||||
machi_partition_simulator:no_partitions(),
|
||||
[DoIt(50, 10, 100) || _ <- [1]],
|
||||
true = private_projections_are_stable(Namez, DoIt),
|
||||
io:format(user, "~s\n", [os:cmd("date")]),
|
||||
|
||||
%% We are stable now ... analyze it.
|
||||
|
||||
%% Create a report where at least one FLU has written a
|
||||
%% private projection.
|
||||
Report = unanimous_report(Namez),
|
||||
%% ?D(Report),
|
||||
|
||||
%% Report is ordered by Epoch. For each private projection
|
||||
%% written during any given epoch, confirm that all chain
|
||||
%% members appear in only one unique chain, i.e., the sets of
|
||||
%% unique chains are disjoint.
|
||||
true = all_reports_are_disjoint(Report),
|
||||
|
||||
%% Given the report, we flip it around so that we observe the
|
||||
%% sets of chain transitions relative to each FLU.
|
||||
R_Chains = [extract_chains_relative_to_flu(FLU, Report) ||
|
||||
FLU <- All_list],
|
||||
%% ?D(R_Chains),
|
||||
R_Projs = [{FLU, [chain_to_projection(FLU, Epoch, UPI, Repairing,
|
||||
All_list) ||
|
||||
{Epoch, UPI, Repairing} <- E_Chains]} ||
|
||||
{FLU, E_Chains} <- R_Chains],
|
||||
|
||||
%% For each chain transition experienced by a particular FLU,
|
||||
%% confirm that each state transition is OK.
|
||||
try
|
||||
[{FLU, true} = {FLU, ?MGR:projection_transitions_are_sane(Ps, FLU)} ||
|
||||
{FLU, Ps} <- R_Projs],
|
||||
io:format(user, "\nAll sanity checks pass, hooray!\n", [])
|
||||
catch _Err:_What ->
|
||||
io:format(user, "Report ~p\n", [Report]),
|
||||
exit({line, ?LINE, _Err, _What})
|
||||
end,
|
||||
%% ?D(R_Projs),
|
||||
|
||||
ok
|
||||
after
|
||||
ok = ?MGR:stop(Ma),
|
||||
ok = ?MGR:stop(Mb),
|
||||
ok = machi_flu0:stop(FLUa),
|
||||
ok = machi_flu0:stop(FLUb),
|
||||
ok = machi_partition_simulator:stop()
|
||||
end.
|
||||
|
||||
private_projections_are_stable(Namez, PollFunc) ->
|
||||
Private1 = [machi_flu0:proj_get_latest_num(FLU, private) ||
|
||||
{_Name, FLU} <- Namez],
|
||||
PollFunc(5, 1, 10),
|
||||
Private2 = [machi_flu0:proj_get_latest_num(FLU, private) ||
|
||||
{_Name, FLU} <- Namez],
|
||||
true = (Private1 == Private2).
|
||||
|
||||
all_hosed_lists_are_identical(Namez, Partition) ->
|
||||
Ps = [machi_flu0:proj_read_latest(FLU, private) || {_Name, FLU} <- Namez],
|
||||
Uniques = lists:usort([machi_chain_manager1:get_all_hosed(P) ||
|
||||
{ok, P} <- Ps]),
|
||||
Members = [M || {M, _Pid} <- Namez],
|
||||
Islands = machi_partition_simulator:partitions2num_islands(
|
||||
Members, Partition),
|
||||
%% io:format(user, "all_hosed_lists_are_identical:\n", []),
|
||||
%% io:format(user, " Uniques = ~p Islands ~p\n Partition ~p\n",
|
||||
%% [Uniques, Islands, Partition]),
|
||||
case length(Uniques) of
|
||||
1 ->
|
||||
true;
|
||||
_ when Islands == 'many' ->
|
||||
%% There are at least two partitions, so yes, it's quite
|
||||
%% possible that the all_hosed lists may differ.
|
||||
%% TODO Fix this up to be smarter about fully-isolated
|
||||
%% islands of partition.
|
||||
true;
|
||||
_ ->
|
||||
false
|
||||
end.
|
||||
|
||||
-endif. % not PULSE
|
||||
-endif. % TEST
|
||||
|
|
|
|||
|
|
@ -29,7 +29,6 @@
|
|||
-endif.
|
||||
|
||||
-ifdef(TEST).
|
||||
-ifndef(PULSE).
|
||||
|
||||
repair_status_test() ->
|
||||
{ok, F} = machi_flu0:start_link(one),
|
||||
|
|
@ -42,6 +41,7 @@ repair_status_test() ->
|
|||
ok = machi_flu0:stop(F)
|
||||
end.
|
||||
|
||||
-ifndef(PULSE).
|
||||
|
||||
concuerror1_test() ->
|
||||
ok.
|
||||
|
|
@ -375,5 +375,5 @@ event_get_all() ->
|
|||
Tab = ?MODULE,
|
||||
ets:tab2list(Tab).
|
||||
|
||||
-endif. % ! PULSE
|
||||
-endif.
|
||||
-endif.
|
||||
|
|
|
|||
|
|
@ -38,6 +38,8 @@
|
|||
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
|
||||
terminate/2, code_change/3]).
|
||||
|
||||
-export([islands2partitions/1, partitions2num_islands/2]).
|
||||
|
||||
-define(TAB, ?MODULE).
|
||||
|
||||
-record(state, {
|
||||
|
|
@ -178,6 +180,16 @@ islands2partitions([Island|Rest]) ->
|
|||
++
|
||||
islands2partitions(Rest).
|
||||
|
||||
|
||||
partitions2num_islands(Members, Partition) ->
|
||||
Connections0 = [{X,Y} || X <- Members, Y <- Members, X /= Y],
|
||||
Connections1 = Connections0 -- Partition,
|
||||
Cs = [lists:member({X,Y}, Connections1)
|
||||
orelse
|
||||
lists:member({Y,X}, Connections1) || X <- Members, Y <- Members,
|
||||
X /= Y],
|
||||
case lists:usort(Cs) of
|
||||
[true] -> 1;
|
||||
[false, true] -> many % TODO too lazy to finish
|
||||
end.
|
||||
|
||||
-endif. % TEST
|
||||
|
|
|
|||
|
|
@ -26,7 +26,6 @@
|
|||
-export([]).
|
||||
|
||||
-ifdef(TEST).
|
||||
-ifndef(PULSE).
|
||||
|
||||
-ifdef(EQC).
|
||||
-include_lib("eqc/include/eqc.hrl").
|
||||
|
|
@ -147,6 +146,5 @@ make_canonical_form2([{File, Start, End, Members}|T]) ->
|
|||
Member <- Members] ++
|
||||
make_canonical_form2(T).
|
||||
|
||||
-endif. % ! PULSE
|
||||
-endif. % TEST
|
||||
|
||||
|
|
|
|||
BIN
prototype/corfurl/.eqc-info
Normal file
7
prototype/corfurl/.gitignore
vendored
|
|
@ -1,7 +0,0 @@
|
|||
.eunit
|
||||
.eqc-info
|
||||
current_counterexample.eqc
|
||||
deps
|
||||
ebin/*.beam
|
||||
ebin/*.app
|
||||
erl_crash.dump
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
REBAR_BIN := $(shell which rebar)
|
||||
ifeq ($(REBAR_BIN),)
|
||||
REBAR_BIN = /local/path/to/rebar
|
||||
endif
|
||||
|
||||
.PHONY: rel deps package pkgclean
|
||||
|
||||
all: deps compile
|
||||
|
||||
compile:
|
||||
$(REBAR_BIN) compile
|
||||
|
||||
deps:
|
||||
$(REBAR_BIN) get-deps
|
||||
|
||||
clean:
|
||||
$(REBAR_BIN) -r clean
|
||||
|
||||
test: deps compile eunit
|
||||
|
||||
eunit:
|
||||
$(REBAR_BIN) -v skip_deps=true eunit
|
||||
|
||||
pulse: compile
|
||||
env USE_PULSE=1 $(REBAR_BIN) skip_deps=true clean compile
|
||||
env USE_PULSE=1 $(REBAR_BIN) skip_deps=true -D PULSE eunit
|
||||
|
|
@ -1,45 +0,0 @@
|
|||
# CORFU in Erlang, a prototype
|
||||
|
||||
This is a mostly-complete complete prototype implementation of the
|
||||
CORFU server & client specification. More details on the papers about
|
||||
CORFU are mentioned in the `docs/corfurl.md` file.
|
||||
|
||||
## Compilation & unit testing
|
||||
|
||||
Use `make` and `make test`. Note that the Makefile assumes that the
|
||||
`rebar` utility is available somewhere in your path.
|
||||
|
||||
## Testing with QuickCheck + PULSE
|
||||
|
||||
This model is a bit exciting because it includes all of the following:
|
||||
|
||||
* It uses PULSE
|
||||
* It uses temporal logic to help verify the model's properties
|
||||
* It also includes a (manual!) fault injection method to help verify
|
||||
that the model can catch many bugs. The `eqc_temporal` library uses
|
||||
a lot of `try/catch` internally, and if your callback code causes an
|
||||
exception in the "wrong" places, the library will pursue a default
|
||||
action rather than triggering an error! The fault injection is an
|
||||
additional sanity check to verify that the model isn't (obviously)
|
||||
flawed or broken.
|
||||
* Uses Lamport clocks to help order happens-before and concurrent events.
|
||||
* Includes stopping the sequencer (either nicely or brutal kill) to verify
|
||||
that the logic still works without any active sequencer.
|
||||
* Includes logic to allow the sequencer to give
|
||||
**faulty sequencer assignments**, including duplicate page numbers and
|
||||
gaps of unused pages. Even if the sequencer **lies to us**, all other
|
||||
CORFU operation should remain 100% correct.
|
||||
|
||||
If you have a Quviq QuickCheck license, then you can also use the
|
||||
`make pulse` target.
|
||||
Please note the following prerequisites:
|
||||
|
||||
* Erlang R16B. Perhaps R15B might also work, but it has not been
|
||||
tested yet.
|
||||
* Quviq QuickCheck version 1.30.2. There appears to be an
|
||||
`eqc_statem` change in Quviq EQC 1.33.2 that has broken the
|
||||
test. We'll try to fix the test to be able to use 1.33.x or later,
|
||||
but it is a lower priority work item for the team right now.
|
||||
|
||||
For more information about the PULSE test and how to use it, see the
|
||||
`docs/using-pulse.md` file.
|
||||
BIN
prototype/corfurl/current_counterexample.eqc
Normal file
|
|
@ -1,98 +0,0 @@
|
|||
## Notes on developing & debugging this CORFU prototype
|
||||
|
||||
I've recorded some notes while developing & debugging this CORFU
|
||||
prototype. See the `corfurl/notes` subdirectory.
|
||||
|
||||
Most of the cases mentioned involve race conditions that were notable
|
||||
during the development cycle. There is one case that IIRC is not
|
||||
mentioned in any of the CORFU papers and is probably a case that
|
||||
cannot be fixed/solved by CORFU itself.
|
||||
|
||||
Each of the scenario notes includes an MSC diagram specification file
|
||||
to help illustrate the race. The diagrams are annotated by hand, both
|
||||
with text and color, to point out critical points of timing.
|
||||
|
||||
## CORFU papers
|
||||
|
||||
I recommend the "5 pages" paper below first, to give a flavor of
|
||||
what the CORFU is about. When Scott first read the CORFU paper
|
||||
back in 2011 (and the Hyder paper), he thought it was insanity.
|
||||
He recommends waiting before judging quite so hastily. :-)
|
||||
|
||||
After that, then perhaps take a step back are skim over the
|
||||
Hyder paper. Hyder started before CORFU, but since CORFU, the
|
||||
Hyder folks at Microsoft have rewritten Hyder to use CORFU as
|
||||
the shared log underneath it. But the Hyder paper has lots of
|
||||
interesting bits about how you'd go about creating a distributed
|
||||
DB where the transaction log *is* the DB.
|
||||
|
||||
### "CORFU: A Distributed Shared Log"
|
||||
|
||||
MAHESH BALAKRISHNAN, DAHLIA MALKHI, JOHN D. DAVIS, and VIJAYAN
|
||||
PRABHAKARAN, Microsoft Research Silicon Valley, MICHAEL WEI,
|
||||
University of California, San Diego, TED WOBBER, Microsoft Research
|
||||
Silicon Valley
|
||||
|
||||
Long version of introduction to CORFU (~30 pages)
|
||||
http://www.snookles.com/scottmp/corfu/corfu.a10-balakrishnan.pdf
|
||||
|
||||
### "CORFU: A Shared Log Design for Flash Clusters"
|
||||
|
||||
Same authors as above
|
||||
|
||||
Short version of introduction to CORFU paper above (~12 pages)
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/corfu-shared-log-design.nsdi12-final30.pdf
|
||||
|
||||
### "From Paxos to CORFU: A Flash-Speed Shared Log"
|
||||
|
||||
Same authors as above
|
||||
|
||||
5 pages, a short summary of CORFU basics and some trial applications
|
||||
that have been implemented on top of it.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/paxos-to-corfu.malki-acmstyle.pdf
|
||||
|
||||
### "Beyond Block I/O: Implementing a Distributed Shared Log in Hardware"
|
||||
|
||||
Wei, Davis, Wobber, Balakrishnan, Malkhi
|
||||
|
||||
Summary report of implmementing the CORFU server-side in
|
||||
FPGA-style hardware. (~11 pages)
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/beyond-block-io.CameraReady.pdf
|
||||
|
||||
### "Tango: Distributed Data Structures over a Shared Log"
|
||||
|
||||
Balakrishnan, Malkhi, Wobber, Wu, Brabhakaran, Wei, Davis, Rao, Zou, Zuck
|
||||
|
||||
Describes a framework for developing data structures that reside
|
||||
persistently within a CORFU log: the log *is* the database/data
|
||||
structure store.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/Tango.pdf
|
||||
|
||||
### "Dynamically Scalable, Fault-Tolerant Coordination on a Shared Logging Service"
|
||||
|
||||
Wei, Balakrishnan, Davis, Malkhi, Prabhakaran, Wobber
|
||||
|
||||
The ZooKeeper inter-server communication is replaced with CORFU.
|
||||
Faster, fewer lines of code than ZK, and more features than the
|
||||
original ZK code base.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/zookeeper-techreport.pdf
|
||||
|
||||
### "Hyder – A Transactional Record Manager for Shared Flash"
|
||||
|
||||
Bernstein, Reid, Das
|
||||
|
||||
Describes a distributed log-based DB system where the txn log is
|
||||
treated quite oddly: a "txn intent" record is written to a
|
||||
shared common log All participants read the shared log in
|
||||
parallel and make commit/abort decisions in parallel, based on
|
||||
what conflicts (or not) that they see in the log. Scott's first
|
||||
reading was "No way, wacky" ... and has since changed his mind.
|
||||
|
||||
http://www.snookles.com/scottmp/corfu/CIDR11Proceedings.pdf
|
||||
pages 9-20
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB |
{kind=link}
|
Before Width: | Height: | Size: 31 KiB |
{kind=link}
|
Before Width: | Height: | Size: 30 KiB |
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
|
|
@ -1,192 +0,0 @@
|
|||
|
||||
# Fiddling with PULSE
|
||||
|
||||
## About the PULSE test
|
||||
|
||||
This test is based on `eqc_statem` QuickCheck model, i.e., a
|
||||
stateful/state machine style test. Roughly speaking, it does the
|
||||
following things:
|
||||
|
||||
1. Chooses a random number of chains, chain length, and simulated flash
|
||||
page size.
|
||||
2. Generates a random set of stateful commands to run.
|
||||
3. During the test case run, an event trace log is generated.
|
||||
4. If there are any `postcondition()` checks that fail, of course,
|
||||
QuickCheck will stop the test and start shrinking.
|
||||
5. If all of the postcondition checks (and the rest of QuickCheck's
|
||||
sanity checking) are OK, the event trace log is checked for
|
||||
sanity.
|
||||
|
||||
### The eqc_statem commands used.
|
||||
|
||||
See the `corfurl_pulse:command/1` function for full details. In
|
||||
summary:
|
||||
|
||||
* `'setup'`, for configuring the # of chains, chain length, simulated
|
||||
page size, and whether or not the sequencer is faulty (i.e.,
|
||||
gives faulty sequencer assignments, including duplicate page numbers and
|
||||
gaps of unused pages).
|
||||
* `'append'`, for `corfurl_client:append_page/2`
|
||||
* '`read_approx'`, for `corfurl_client:read_page/2`
|
||||
* `'scan_forward'`, for `corfurl_client:scan_forward/3`
|
||||
* `'fill'`, for `corfurl_client:fill_page/2`
|
||||
* `'trim'`, for `corfurl_client:trim_page/2'
|
||||
* `'stop_sequencer'`, for `corfurl_sequencer:stop/2'
|
||||
|
||||
### Sanity checks for the event trace log
|
||||
|
||||
Checking the event trace log for errors is a bit tricky. The model is
|
||||
similar to checking a key-value store. In a simple key-value store
|
||||
model, we know (in advance) the full key. However, in CORFU, the
|
||||
sequencer tells us the key, i.e., the flash page number that an
|
||||
"append page" operation will use. So the model must be able to infer
|
||||
the flash page number from the event trace, then use that page number
|
||||
as the key for the rest of the key-value-store-like model checks.
|
||||
|
||||
This test also uses the `eqc_temporal` library for temporal logic. I
|
||||
don't claim to be a master of using temporal logic in general or that
|
||||
library specifically ... so I hope that I haven't introduced a subtle
|
||||
bug into the model. <tt>^_^</tt>.
|
||||
|
||||
Summary of the sanity checks of the event trace:
|
||||
|
||||
* Do all calls finish?
|
||||
* Are there any invalid page transitions? E.g., `written ->
|
||||
unwritten` is forbidden.
|
||||
* Are there any bad reads? E.g., reading an `error_unwritten` result
|
||||
when the page has **definitely** been written/filled/trimmed.
|
||||
* Note that temporal logic is used to calculate when we definitely
|
||||
know a page's value vs. when we know that a page's value is
|
||||
definitely going to change
|
||||
**but we don't know exactly when the change has taken place**.
|
||||
|
||||
### Manual fault injection
|
||||
|
||||
TODO: Automate the fault injection testing, via "erl -D" compilation.
|
||||
|
||||
There are (at least) five different types of fault injection that can
|
||||
be implemented by defining certain Erlang preprocessor symbols at
|
||||
compilation time of `corfurl_pulse.erl`.
|
||||
|
||||
TRIP_no_append_duplicates
|
||||
Will falsely report the LPN (page number) of an append, if the
|
||||
actual LPN is 3, as page #3.
|
||||
TRIP_bad_read
|
||||
Will falsely report the value of a read operation of LPN #3.
|
||||
TRIP_bad_scan_forward
|
||||
Will falsely report written/filled pages if the # of requested
|
||||
pages is equal to 10.
|
||||
TRIP_bad_fill
|
||||
Will falsely report the return value of a fill operation if the
|
||||
requested LPN is between 3 & 5.
|
||||
TRIP_bad_trim
|
||||
Will falsely report the return value of a trim operation if the
|
||||
requested LPN is between 3 & 5.
|
||||
|
||||
## Compiling and executing batch-style
|
||||
|
||||
Do the following:
|
||||
|
||||
make clean ; make ; make pulse
|
||||
|
||||
... then watch the dots go across the screen for 60 seconds. If you
|
||||
wish, you can press `Control-c` to interrupt the test. We're really
|
||||
interested in the build artifacts.
|
||||
|
||||
## Executing interactively at the REPL shell
|
||||
|
||||
After running `make pulse`, use the following two commands to start an
|
||||
Erlang REPL shell and run a test for 5 seconds.
|
||||
|
||||
erl -pz .eunit deps/*/ebin
|
||||
eqc:quickcheck(eqc:testing_time(5, corfurl_pulse:prop_pulse())).
|
||||
|
||||
This will run the PULSE test for 5 seconds. Feel free to adjust for
|
||||
as many seconds as you wish.
|
||||
|
||||
Erlang R16B02-basho4 (erts-5.10.3) [source] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
|
||||
|
||||
Eshell V5.10.3 (abort with ^G)
|
||||
1> eqc:quickcheck(eqc:testing_time(5, corfurl_pulse:prop_pulse())).
|
||||
Starting Quviq QuickCheck version 1.30.4
|
||||
(compiled at {{2014,2,7},{9,19,50}})
|
||||
Licence for Basho reserved until {{2014,2,17},{1,41,39}}
|
||||
......................................................................................
|
||||
OK, passed 86 tests
|
||||
schedule: Count: 86 Min: 2 Max: 1974 Avg: 3.2e+2 Total: 27260
|
||||
true
|
||||
2>
|
||||
|
||||
REPL interactive work can be done via:
|
||||
|
||||
1. Edit code, e.g. `corfurl_pulse.erl`.
|
||||
2. Run `env USE_PULSE=1 rebar skip_deps=true -D PULSE eunit suites=SKIP`
|
||||
to compile.
|
||||
3. Reload any recompiled modules, e.g. `l(corfurl_pulse).`
|
||||
4. Resume QuickCheck activities.
|
||||
|
||||
## Seeing an PULSE scheduler interleaving failure in action
|
||||
|
||||
1. Edit `corfurl_pulse:check_trace()` to uncomment the
|
||||
use of `conjunction()` that mentions the `{bogus_no_gaps, ...}` tuple.
|
||||
2. Recompile & reload.
|
||||
3. Check.
|
||||
|
||||
For example:
|
||||
|
||||
9> eqc:quickcheck(eqc:testing_time(5, corfurl_pulse:prop_pulse())).
|
||||
.........Failed! After 9 tests.
|
||||
|
||||
Sweet! The first tuple below are the first `?FORALL()` values,
|
||||
and the 2nd is the list of commands,
|
||||
`{SequentialCommands, ListofParallelCommandLists}`. The 3rd is the
|
||||
seed used to perturb the PULSE scheduler.
|
||||
|
||||
In this case, `SequentialCommands` has two calls (to `setup()` then
|
||||
`append()`) and there are two parallel procs: one makes 1 call
|
||||
call to `append()` and the other makes 2 calls to `append()`.
|
||||
|
||||
{2,2,9}
|
||||
{{[{set,{var,1},{call,corfurl_pulse,setup,[2,2,9]}}],
|
||||
[[{set,{var,3},
|
||||
{call,corfurl_pulse,append,
|
||||
[{var,1},<<231,149,226,203,10,105,54,223,147>>]}}],
|
||||
[{set,{var,2},
|
||||
{call,corfurl_pulse,append,
|
||||
[{var,1},<<7,206,146,75,249,13,154,238,110>>]}},
|
||||
{set,{var,4},
|
||||
{call,corfurl_pulse,append,
|
||||
[{var,1},<<224,121,129,78,207,23,79,216,36>>]}}]]},
|
||||
{27492,46961,4884}}
|
||||
|
||||
Here are our results:
|
||||
|
||||
simple_result: passed
|
||||
errors: passed
|
||||
events: failed
|
||||
identity: passed
|
||||
bogus_order_check_do_not_use_me: failed
|
||||
[{ok,1},{ok,3},{ok,2}] /= [{ok,1},{ok,2},{ok,3}]
|
||||
|
||||
Our (bogus!) order expectation was violated. Shrinking!
|
||||
|
||||
simple_result: passed
|
||||
errors: passed
|
||||
events: failed
|
||||
identity: passed
|
||||
bogus_order_check_do_not_use_me: failed
|
||||
[{ok,1},{ok,3},{ok,2}] /= [{ok,1},{ok,2},{ok,3}]
|
||||
|
||||
Shrinking was able to remove two `append()` calls and to shrink the
|
||||
size of the pages down from 9 bytes down to 1 byte.
|
||||
|
||||
Shrinking........(8 times)
|
||||
{1,1,1}
|
||||
{{[{set,{var,1},{call,corfurl_pulse,setup,[1,1,1]}}],
|
||||
[[{set,{var,3},{call,corfurl_pulse,append,[{var,1},<<0>>]}}],
|
||||
[{set,{var,4},{call,corfurl_pulse,append,[{var,1},<<0>>]}}]]},
|
||||
{27492,46961,4884}}
|
||||
events: failed
|
||||
bogus_order_check_do_not_use_me: failed
|
||||
[{ok,2},{ok,1}] /= [{ok,1},{ok,2}]
|
||||
false
|
||||
9
prototype/corfurl/ebin/corfurl.app
Normal file
|
|
@ -0,0 +1,9 @@
|
|||
{application,corfurl,
|
||||
[{description,"Quick prototype of CORFU in Erlang."},
|
||||
{vsn,"0.0.0"},
|
||||
{applications,[kernel,stdlib,lager]},
|
||||
{mod,{corfurl_unfinished_app,[]}},
|
||||
{registered,[]},
|
||||
{env,[{ring_size,32}]},
|
||||
{modules,[corfurl,corfurl_client,corfurl_flu,corfurl_sequencer,
|
||||
corfurl_util]}]}.
|
||||