9.9 KiB
Machi cluster-of-clusters "name game" sketch
- 1. "Name Games" with random-slicing style consistent hashing
- 2. Assumptions
- Basic familiarity with Machi high level design and Machi's "projection"
- Familiarity with the Machi cluster-of-clusters/CoC concept
- Continue CoC prototype's assumption: a Machi cluster is unaware of CoC
- Analogy: "neighborhood : city :: Machi :: cluster-of-clusters"
- The reader is familiar with the random slicing technique
- We use random slicing to map CoC file names -> Machi cluster ID/name
- Machi cluster ID/name management: TBD, but, really, should be simple
- 3. A simple illustration
- 4. An additional assumption: clients will want some control over file placement
- 5. Proposal: Break the opacity of Machi file names, slightly
- Acknowledgements
-- mode: org; --
1. "Name Games" with random-slicing style consistent hashing
Our goal: to distribute lots of files very evenly across a cluster of Machi clusters (hereafter called a "cluster of clusters" or "CoC").
2. Assumptions
Basic familiarity with Machi high level design and Machi's "projection"
The Machi high level design document contains all of the basic background assumed by the rest of this document.
Familiarity with the Machi cluster-of-clusters/CoC concept
This isn't yet well-defined (April 2015). However, it's clear from the Machi high level design document that Machi alone does not support any kind of file partitioning/distribution/sharding across multiple machines. There must be another layer above a Machi cluster to provide such partitioning services.
The name "cluster of clusters" orignated within Basho to avoid conflicting use of the word "cluster". A Machi cluster is usually synonymous with a single Chain Replication chain and a single set of machines (e.g. 2-5 machines). However, in the not-so-far future, we expect much more complicated patterns of Chain Replication to be used in real-world deployments.
"Cluster of clusters" is clunky and long, but we haven't found a good substitute yet. If you have a good suggestion, please contact us! ^_^
Using the cluster-of-clusters quick-and-dirty prototype as an architecture sketch, let's now assume that we have N independent Machi clusters. We wish to provide partitioned/distributed file storage across all N clusters. We call the entire collection of N Machi clusters a "cluster of clusters", or abbreviated "CoC".
Continue CoC prototype's assumption: a Machi cluster is unaware of CoC
Let's continue with an assumption that an individual Machi cluster inside of the cluster-of-clusters is completely unaware of the cluster-of-clusters layer.
We may need to break this assumption sometime in the future? It isn't quite clear yet, sorry.
Analogy: "neighborhood : city :: Machi :: cluster-of-clusters"
Analogy: The word "machi" in Japanese means small town or neighborhood. As the Tokyo Metropolitan Area is built from many machis and smaller cities, therefore a big, partitioned file store can be built out of many small Machi clusters.
The reader is familiar with the random slicing technique
I'd done something very-very-nearly-identical for the Hibari database 6 years ago. But the Hibari technique was based on stuff I did at Sendmail, Inc, so it felt old news to me. {shrug}
The Hibari documentation has a brief photo illustration of how random slicing works, see Hibari Sysadmin Guide, chain migration
For a comprehensive description, please see these two papers:
Reliable and Randomized Data Distribution Strategies for Large Scale Storage Systems Alberto Miranda et al. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.226.5609 (short version, HIPC'11)
Random Slicing: Efficient and Scalable Data Placement for Large-Scale Storage Systems Alberto Miranda et al. DOI: http://dx.doi.org/10.1145/2632230 (long version, ACM Transactions on Storage, Vol. 10, No. 3, Article 9, 2014)
We use random slicing to map CoC file names -> Machi cluster ID/name
We will use a single random slicing map. This map (called "Map" in the descriptions below), together with the random slicing hash function (called "rs_hash()" below), will be used to map:
CoC client-visible file name -> Machi cluster ID/name/thingie
Machi cluster ID/name management: TBD, but, really, should be simple
The mapping from:
Machi CoC member ID/name/thingie -> ???
… remains To Be Determined. But, really, this is going to be pretty simple. The ID/name/thingie will probably be a human-friendly, printable ASCII string, and the "???" will probably be a single Machi cluster projection data structure.
The Machi projection is enough information to contact any member of that cluster and, if necessary, request the most up-to-date projection information required to use that cluster.
It's likely that the projection given by this map will be out-of-date, so the client must be ready to use the standard Machi procedure to request the cluster's current projection, in any case.
3. A simple illustration
I'm borrowing an illustration from the HibariDB documentation here, but it fits my purposes quite well. (And I originally created that image, and the use license is OK.)
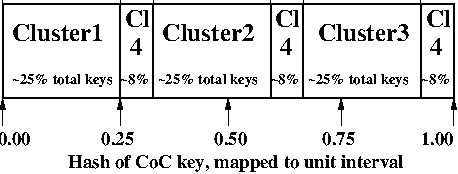
Assume that we have a random slicing map called Map. This particular Map maps the unit interval onto 4 Machi clusters:
| Hash range | Cluster ID |
|---|---|
| 0.00 - 0.25 | Cluster1 |
| 0.25 - 0.33 | Cluster4 |
| 0.33 - 0.58 | Cluster2 |
| 0.58 - 0.66 | Cluster4 |
| 0.66 - 0.91 | Cluster3 |
| 0.91 - 1.00 | Cluster4 |
Then, if we had CoC file name "foo", the hash SHA("foo") maps to about 0.05 on the unit interval. So, according to Map, the value of rs_hash("foo",Map) = Cluster1. Similarly, SHA("hello") is about 0.67 on the unit interval, so rs_hash("hello",Map) = Cluster3.
4. An additional assumption: clients will want some control over file placement
We will continue to use the 4-cluster diagram from the previous section.
When a client wishes to append data to a Machi file, the Machi server chooses the file name & byte offset for storing that data. This feature is why Machi's eventual consistency operating mode is so nifty: it allows us to merge together files safely at any time because any two client append operations will always write to different files & different offsets.
Our new assumption: client control over initial file placement
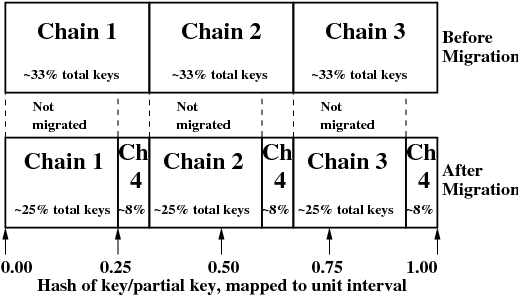
The CoC management scheme may decide that files need to migrate to other clusters. The reason could be for storage load or I/O load balancing reasons. It could be because a cluster is being decomissioned by its owners. There are many legitimate reasons why a file that is initially created on cluster ID X has been moved to cluster ID Y.
However, there are legitimate reasons for why the client would want control over the choice of Machi cluster when the data is first written. The single biggest reason is load balancing. Assuming that the client (or the CoC management layer acting on behalf of the CoC client) knows the current utilization across the participating Machi clusters, then it may be very helpful to send new append() requests to under-utilized clusters.
Cool! Except for a couple of problems…
However, this Machi file naming feature is not so helpful in a cluster-of-clusters context. If the client wants to store some data on Cluster2 and therefore sends an append("foo",CoolData) request to the head of Cluster2 (which the client magically knows how to contact), then the result will look something like {ok,"foo.s923.z47",ByteOffset}.
So, "foo.s923.z47" is the file name that any Machi CoC client must use in order to retrieve the CoolData bytes.
Problem #1: We want CoC files to move around automatically
If the CoC client stores two pieces of information, the file name "foo.s923.z47" and the Cluster ID Cluster2, then what happens when the cluster-of-clusters system decides to rebalance files across all machines? The CoC manager may decide to move our file to Cluster66.
How will a future CoC client wishes to retrieve CoolData when Cluster2 no longer stores the required file?
When migrating the file, we could put a "pointer" on Cluster2 that points to the new location, Cluster66.
This scheme is a bit brittle, even if all of the pointers are always created 100% correctly. Also, if Cluster2 is ever unavailable, then we cannot fetch our CoolData, even though the file moved away from Cluster2 several years ago.
The scheme would also introduce extra round-trips to the servers whenever we try to read a file where we do not know the most up-to-date cluster ID for.
We could store "foo.s923.z47"'s location in an LDAP database!
Or we could store it in Riak. Or in another, external database. We'd rather not create such an external dependency, however.
Problem #2: "foo.s923.z47" doesn't always map via random slicing to Cluster2
… if we ignore the problem of "CoC files may be redistributed in the future", then we still have a problem.
In fact, the value of ps_hash("foo.s923.z47",Map) is Cluster1.
The whole reason using random slicing is to make a very quick, easy-to-distribute mapping of file names to cluster IDs. It would be very nice, very helpful if the scheme would actually work for us.
5. Proposal: Break the opacity of Machi file names, slightly
Assuming that Machi keeps the scheme of creating file names (in response to append() and sequencer_new_range() calls) based on a predictable client-supplied prefix and an opaque suffix, e.g.,
append("foo",CoolData) -> {ok,"foo.s923.z47",ByteOffset}.
… then we propose that all CoC and Machi parties be aware of this naming scheme, i.e. that Machi assigns file names based on:
ClientSuppliedPrefix + "." + SomeOpaqueFileNameSuffix
The Machi system doesn't care about the file name – a Machi server will treat the entire file name as an opaque thing. But this document is called the "Name Game" for a reason.
What if the CoC client uses a similar scheme?
Acknowledgements
The source for the "migration-4.png" and "migration-3to4.png" images come from the HibariDB documentation.
{kind=link}